







 本文详细解读了《Deep Convolutional Generative Adversarial Networks》这篇论文,并结合TensorFlow实现的DCGAN源码进行分析。重点讨论了DCGAN使用strided convolutions和fractional strided convolutions、Batch Normalization以及去掉全连接层的设计选择。同时,通过源码展示了生成器和判别器的结构,并讨论了损失函数。尽管在有限的硬件条件下,仍能观察到MNIST数据集的初步生成结果。
本文详细解读了《Deep Convolutional Generative Adversarial Networks》这篇论文,并结合TensorFlow实现的DCGAN源码进行分析。重点讨论了DCGAN使用strided convolutions和fractional strided convolutions、Batch Normalization以及去掉全连接层的设计选择。同时,通过源码展示了生成器和判别器的结构,并讨论了损失函数。尽管在有限的硬件条件下,仍能观察到MNIST数据集的初步生成结果。
论文地址:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
源码地址:DCGAN in TensorFlow
DCGAN,Deep Convolutional Generative Adversarial Networks是生成对抗网络(Generative Adversarial Networks)的一种延伸,将卷积网络引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
DCGAN有以下特点:
1.在判别器模型中使用strided convolutions来替代空间池化(pooling),而在生成器模型中使用fractional strided convolutions,即deconv,反卷积层。
2.除了生成器模型的输出层和判别器模型的输入层,在网络其它层上都使用了Batch Normalization,使用BN可以稳定学习,有助于处理初始化不良导致的训练问题。
3.去除了全连接层,而直接使用卷积层连接生成器和判别器的输入层以及输出层。
4.在生成器的输出层使用Tanh激活函数,而在其它层使用ReLU;在判别器上使用leaky ReLU。
原论文中只给出了在LSUN实验上的生成器模型的结构图如下:
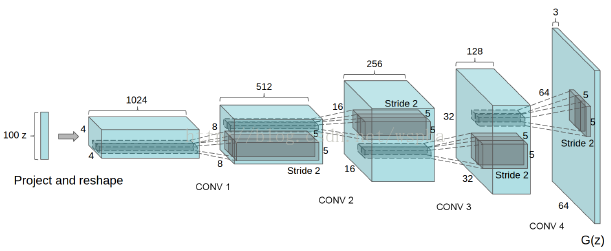
但是对于实验细节以及方法的介绍并不是很详细,于是便从源码入手来理解DCGAN的工作原理。
先看main.py:
with tf.Session(config=run_config) as sess:
if FLAGS.dataset == 'mnist':
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
y_dim=10,
c_dim=1,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
is_crop=FLAGS.is_crop,
checkpoint_dir=FLAGS.checkpoint_d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









