









转自:新智元
论文来自:An Analysis of Deep Neural Network Models for Practical Applications
【导读】计算机图像计算水平稳步的增长,但各大厉害的模型尚未得到合理应用。在这篇 ICLR 2017 提交论文《深度神经网络模型分析在实践中的应用》中,作者从精确度、内存占用、参数、推理时间和功耗等方面分析比较 ImageNet 历届冠军架构,为有效设计及应用深度神经网络提供了最新的分析资料。
深度神经网络自出现以来,已经成为计算机视觉领域一项举足轻重的技术。其中,ImageNet 图像分类竞赛极大地推动着这项新技术的发展。精确计算水平取得了稳步的增长,但颇具吸引力的模型应用尚未得到合理的利用。
本文将综合分析实际应用中的几项重要指标:准确度、内存占用、参数、操作时间、操作次数、推理时间、功耗,并得出了以下几项主要研究结论:
- 功耗与批量大小、体系结构无关;
- 准确度与推理时间呈双曲线关系;
- 能量限制是最大可达准确度和模式复杂度的上限;
- 操作次数可以有效评估推理时间。
ImageNet 历届冠军架构评析指标
自从2012年的 ImageNet 竞赛上,Alexnet取得突破发展,成为第一个应用深度神经网络的应用,其他关于DNN的更复杂的应用也陆续出现。
图像处理软件分类挑战赛的终极目标是,在考虑实际推理时间的情况下,提高多层分类框架的准确度。为了达到这个目标,就要解决以下三方面的问题。第一,一般情况下,我们会在每个验证图像的多个类似实例中运行一个给定模型的多个训练实例。这种方法叫做模型平均或DNN集成,可以极大提高推理所需的计算量,以获得published准确度。第二,不同研究报告中对验证图像做的预估模型(集合)的操作次数不一样,模型选择会受到影响,因此不同的抽样方法(以及取样集合的大小不同)得出的报告准确度结果就会有所偏差。第三,加速推理过程是模型实际应用的关键,影响着资源利用、功耗以及推理延迟等因素,而目前尚无方法使推理时间缩短。
本文旨在对过去4年图像处理软件分类挑战赛上出现的不同种类的先进的DNN架构做对比,从计算需要和准确度两个角度做分析,主要比较这些架构与资源利用实际部署相关的多个指标,即准确度、内存占用、参数、操作时间、操作次数、推理时间、功耗。
文章主要目的是通过分析,强调这些指标的重要性,因为这些指标是优化神经网络实际部署与应用的基本硬性限制条件。
评析方法
为了比较不同模型的质量,我们收集了文献中的一些数据,分析发现不同的抽样方法得出的结论也不一样。比如,VGG-16和GoogleNet 的central-crop误差分别是8.7%和10.07%,表明VGG-16性能优于googleNet,而用10-crop抽样,则误差分别是9.33%和9.15%,VGG-16又比GoogleNet差了。于是,我们决定基于分析,对所有网络重新评估,使用单个central-crop抽样方法。
我们使用 cuDNN-v5和CUDA-v8配置的Torch 7来做推理时间和内存占用测算。所有的试验都使用的是JstPack-2.3 NVIDIA Jetson TX1,内置视觉计算系统,64-bit ARM A57 CPU。
使用这种限量级的设备是为了更好地强调网络架构的不同,主要是因为使用现存的大多数GPU,比如NVIDIA K40或者Titan X得出的结果基本都一样。为了测算功耗,我们使用的是Keysight 1146B Hall电流探头,内置Keysight MSO-X 2024A 200MHz 数字显波器,抽样周期2s,采样率50kSa/s。该系统由 Keysight E3645A GPIB数控直流电源供电。
具体结果
我们比较了以下 DDN:
- AlexNet (Krizhevsky et al., 2012);batch normalised AlexNet
(Zagoruyko, 2016);batch normalised Network In Network (NIN) (Lin et al., 2013); - ENet (Paszke et al., 2016) for ImageNet (Culurciello, 2016);
- GoogLeNet (Szegedy et al., 2014);
- VGG-16 and -19 (Simonyan & Zisserman, 2014);
- ResNet-18, -34, -50, -101 and -152 (He et al., 2015);
- Inception-v3 (Szegedy et al., 2015) 以及 Inception-v4 (Szegedy et al., 2016)。
1. 准确率(Accuracy)
图 1 展示了提交给 ImageNet 挑战赛的架构的 1-crop 准确率,最左边的是 AlexNet,最右边的是 Inception -v4。最新的 ResNet 和 Inception 架构相比其他架构准确率至少高 7%。本文中,我们使用不同的颜色区分不同的架构和他们的作者,同一个网络的色系相同,例如粉色系的都是 ResNet。
图2 则提供了各网络更详细的准确率值,将计算成本和网络参数的数量可视化呈现。首先非常明显的是,VGG 不管从计算需求还是参数数量方面来说,都是迄今为止最昂贵的架构,尽管它已经被广泛应用于许多应用程序。VGG 的16层和19层的实现实际上与其他所有网络都是隔绝的。其他的架构形成了一条斜线,到 Inception 和 ResNet 时,这条线开始变平缓。这表明这些模型在该数据集上到达一个拐点。在这个拐点上,计算成本(复杂性)开始超过准确率上的好处。
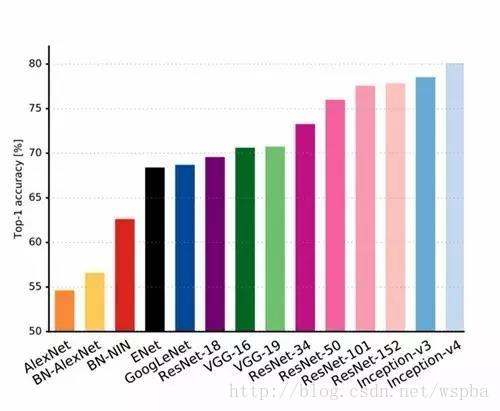
图1: Top1 vs. 网络. Single-crop top-1 用最高评分体系检测准确度。上图中不同的配色方案表示不同的架构和作者。注意,同组网络共享相同的色相,比如所有的ResNet系列都是用粉色系表示的。
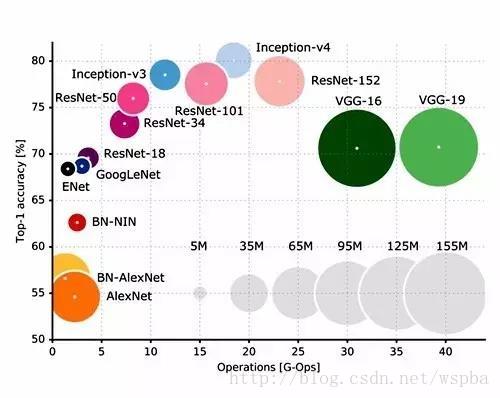
图 2: Top1 vs. 操作、数量大小、参数 Top-1 one-crop 准确度与单向前进传递所需操作次数的对比。图中气泡大小与网络参数数量成正比;右下角记录的是从5*106 到155*106参数值的历史最大值;所有数据都共享一个y轴,灰色点表示气泡中心的值。
2. 推理时间(Inference Time)
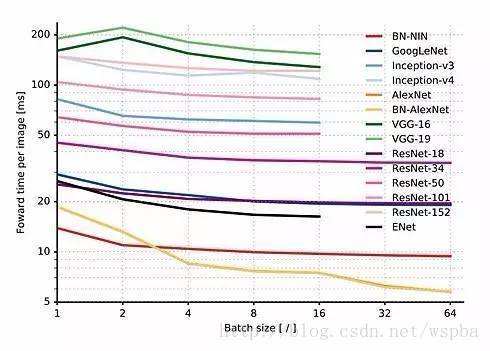
上图(图3)显示了各架构在每个图像上的推理时间,作为一个图像批大小(从1到64)函数。我们注意到 VGG 处理一张图像所需时间约1/5秒,这使它在 NVIDIA TX1 上实时应用的可能性较小。AlexNet 的批大小从1到64的变化中,处理速度提升了3倍,这是由于它的完全连接层的弱优化,这个发现令人惊讶。
3. 功耗(Power)
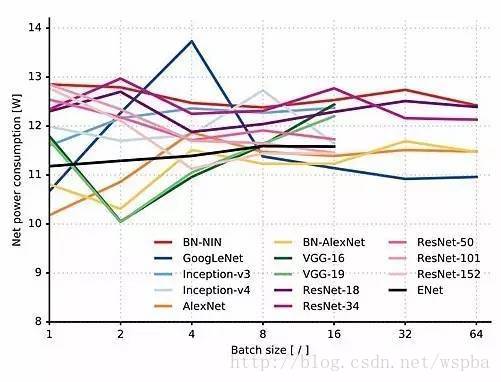
由于电流消耗的高频率波动,功耗的测量相当复杂,需要高采样电流读出以避免混淆。在本研究中,我们使用的测量工具是带电流探头的 200 MHz 数字示波器。如上图所示,功耗多数情况下与批大小无关。由图3可见,AlexNet (批大小为1)和 VGG(批大小为2)的低功耗与较慢的推理时间相关。
4 内存(Memory)
分析使用 CPU 和 GPU 共享内存的 TX1 设备的系统内存消耗得到的结果由下图可见,最初最大系统内存使用情况是不变的,随着批大小增加,内存消耗增大。这是由于网络模型的初始内存分配以及批处理时的内存需求随着图像数量的增加而成比例地增加。
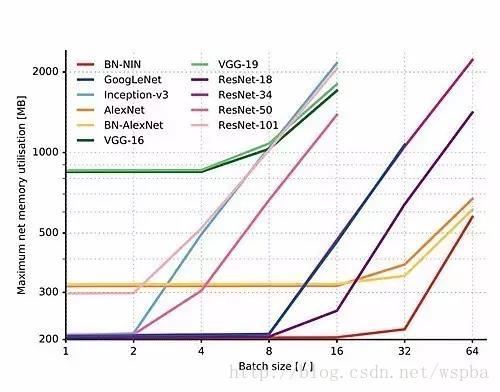
分析使用 CPU 和 GPU 共享内存的 TX1 设备的系统内存消耗得到的结果由上图可见,最初最大系统内存使用情况是不变的,随着批大小增加,内存消耗增大。这是由于网络模型的初始内存分配以及批处理时的内存需求随着图像数量的增加而成比例地增加。
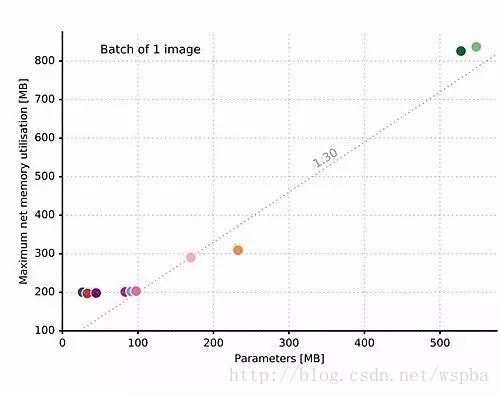
从上图中我们注意到,对规模小于 100 MB的网络,初始内存分配不会小于 200 MB,而且随后呈现为一条斜率为1.3的线性函数。
5 运算(Operations)
在神经网络加速器的自定义实现中,运算量(operation count)对于预估推理时间和硬件电路体积是必要的。
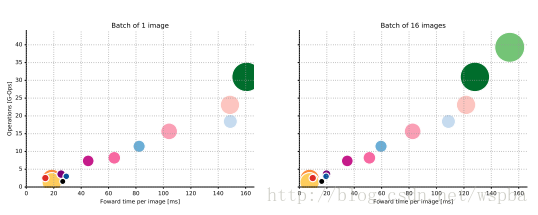
分析发现,对批大小为16的图像,每个图像的运算量和推理时间之间存在线性关系。因此,在设计网络时,可以控制运算量,以使处理速度保持在实时应用或资源有限的应用的可接受范围内。
6. 运算和功耗
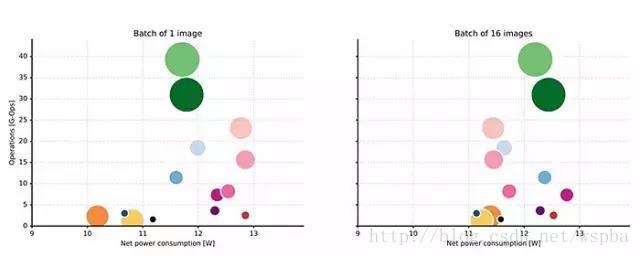
分析功耗和给定模型所需的运算次数之间的关系后,我们发现不同架构之间没有特定的 power footprint(见上图)。当达到完全的资源利用时,通常批大小较大,所有网络的额外消耗大致为 11.8 W,标准偏差为 0.7 W,空闲功率为 1.30 W。这是资源完全利用时的最大系统功耗。因此,如果功耗是我们要关注的点之一,例如电池设备限制,可以简单地选择满足最低功耗要求的最慢的架构。
7 准确率和吞吐量
我们注意到,在单位时间里,准确率和推理数量之间存在非平凡的线性上限。下图显示,对于给定的帧速率,可以实现的最大准确率与帧速率本身形成线性比例。这里分析的所有网络均来自公开出版论文,并且已经得到其他研究团队的独立训练。准确率的线性拟合显示了所有架构的准确率与速度之间的关系。
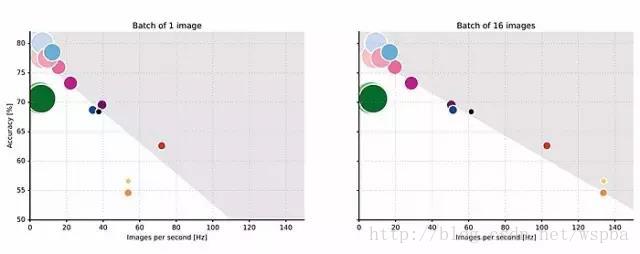
此外,选定一个推理时间,可以得出资源充分利用条件下理论上的最大准确率。由于功耗固定,我们甚至可以进一步得出能耗限制下的最大准确率,这可以作为需要在嵌入式系统上运行的网络的基本设计因素。由于没有了扰流器,考虑前向推理时间时,准确率与吞吐量之间的线性关系转变为双曲线关系。那么,假设运算量与推理时间是线性关系,准确率对网络需要的运算量则具有双曲线依赖性(hyperbolical dependency)。
8 参数使用
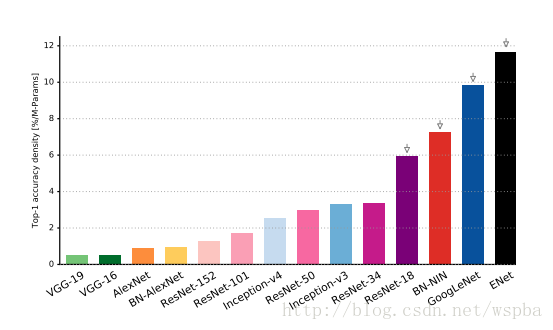
我们已经知道,DNN 在利用全部学习能力(参数数量/自由度)方面非常低效。Han et al., 2015 的研究利用 DNN 的这个缺陷,使用权重剪枝(weights pruning)、量化(quantisation)和变长编码(variable-length symbol encoding)将网络规模减小了50倍。值得注意的是,使用更高效的架构能够产生更紧凑的呈现。如上图所示,虽然 VGG 比 AlexNet 的准确率更高(图1),但其信息密度不如 AlexNet。这意味着在 VGG 架构中引入的自由度带来的准确率上的提高不大。
结语
本文从准确性、内存占用、参数、运算量、推理时间和功耗方面,对 ImageNet 竞赛中多个先进深层神经网络进行了分析,从而对设计用于实际应用的高效神经网络提供参考并优化资源,因为在实际部署中我们能使用的资源往往十分有限。从上文可知,神经网络的精度和推理时间呈双曲关系:准确度的微量增加也会花费大量的计算时间。此外,网络模型的运算量能有效估计推理所需要的时间。
这也是我们为 ImageNet 创建 ENet(Efficient-Network)的原因。ENet 是当前对参数空间利用率最好的架构。















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









