









使用SPDK加速PureFlash存储系统
PureFlash with Spdk
PureFlash存储系统简介:PureFlash简介
PureFlash的开源项目位置:PureFlash github
在原始的PureFlash项目中,我们使用了eventqueue模型进行IO流的传递,同时IO在PureFlash Server中的最后一步是提交给磁盘,也就是在ioengine模块中,PureFlash支持了lioaio以及iouring;
2023年8月我们将spdk集成到pureflash中,增加了pureflash对一下三个关键特性的支持:
- 支持spdk的队列模型,也即dpdk的rte_ring队列模型,进步一减少io在消息队列中传递的性能消耗;
- 支持spdk的用户态驱动,以bypass内核;
- 支持polling模型,以达到快速的io响应速度,提升cpu的利用率;
基于以上优化,再配合RDMA的使用,在单存储节点使用4块nvme磁盘的条件下,我们达到了170万+的4K随机IO读写性能。
队列模型
PureFlash中的class PfSpdkQueue类基于spdk ring实现了消息队列的传递:
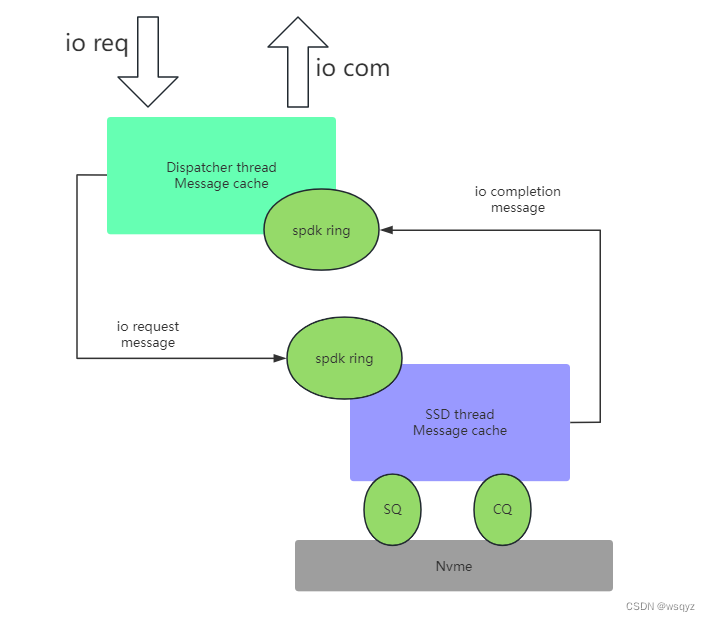
首先,io流的每个线程,都会为自己缓存一个local message cache,这个local因为只用自己使用,所以无需加锁保护;同时,每个线程都会初始化一个spdk ring,用于接受其他线程post过来的message,对这个spdk ring的poll动作,既可以采用polling模型,也可以采用interrupt模型;
以dispatcher线程到SSD线程io流为例说明:
流程1:dispatcher作为source thread,从local message queue拿到msg,携带io信息,入队到target (ssd)thread的spdk ring中;target thread作为ssd thread,io会被再次入队到Nvme 的SQ中;
流程2:io完成后,ssd thread从Nvme的CQ中poll到completion io,此时ssd thread作为source thread,会将io入队到target (dispatcher)thread的spdk ring中;target thread作为dispatcher thread,io会被再次入队网卡的SQ中;
上面的流程中,流程1消耗了source的message cache中的一个message,同时target的message cache中增加了一个message;流程2 source和target的角色互换,会将之前增加message“角色”的message消耗掉,消耗message“角色”的message补充上。基于这种模式,维持了各个线程之间message cache不会发生“枯竭”。
ioengine
当前PureFlash在class PfIoEngine类中,支持了libaio,iouring,spdk nvme三种io engine,在PureFlash启动时,可以根据配置文件,自由配置想要的engine类型:
[engine]
name=spdk
[tray.0]
dev = trtype:PCIe traddr:0000:4d:00.0 # path of physical flash device
PureFlash自己实现了一套简洁且高效的机制管理本地磁盘的元数据,因此我们选择了spdk中spdk_nvme_ns_cmd_read_with_md/spdk_nvme_ns_cmd_write_with_md函数接口直接访问nvme磁盘,以到达最直接的磁盘访问模式:

当选择了spdk engine时,PureFlash会为每个Nvme创建一个QP,然后在SSD thread中去操作这对QP;
同时预分配IO流程中使用的dma buffer,在RDMA模式下,这些dma buffer会同时被注册为网卡的memory region,实现了整个io流程中的zero copy;
OK~ 上面简单描述了PureFlash当前使用spdk的关键技术点,欢迎交流学习~















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









