









spdk nvme测试工具 perf
perf vs libaio
fio命令
fio -filename=/dev/nvme1n1 -direct=1 -iodepth=128 -thread -rw=randwrite -ioengine=libaio -bs=4k -numjobs=1 -runtime=180 -group_reporting -name=randw
fio -filename=/dev/nvme1n1 -direct=1 -iodepth=128 -thread -rw=randwrite -ioengine=libaio -bs=4k -numjobs=4 -runtime=180 -group_reporting -name=randw
perf命令
/usr/local/bin/spdk_nvme_perf -q 128 -o 4096 -w randwrite -r 'trtype:PCIe traddr:0000:da:00.0' -t 300
/usr/local/bin/spdk_nvme_perf -c 0xf -q 128 -o 4096 -w randwrite -r 'trtype:PCIe traddr:0000:da:00.0' -t 300
以上测试命令,可以用来横向对比fio 和 perf在iodepth为128的情况下,使用1个cpu和4个cpu时,所变现的性能差异;
二者的实现上,首先在下发IO模型上,采用了不同的实现方式;其次perf采用了spdk的线程模型,以及用户态驱动;fio则是业内更加通用的性能测试工具。
perf参数
除了iodepth和使用的线程数外,还可以通过调整给NVMe创建的QP的个数,来比较性能差异:
多qpair vs 单qpair
/usr/local/bin/spdk_nvme_perf -P 4 -q 128 -o 4096 -w randread -r 'trtype:PCIe traddr:0000:da:00.0' -t 300
/usr/local/bin/spdk_nvme_perf -P 1 -q 128 -o 4096 -w randread -r 'trtype:PCIe traddr:0000:da:00.0' -t 300
在这里,研究了一下perf向qpair下发IO的模型:
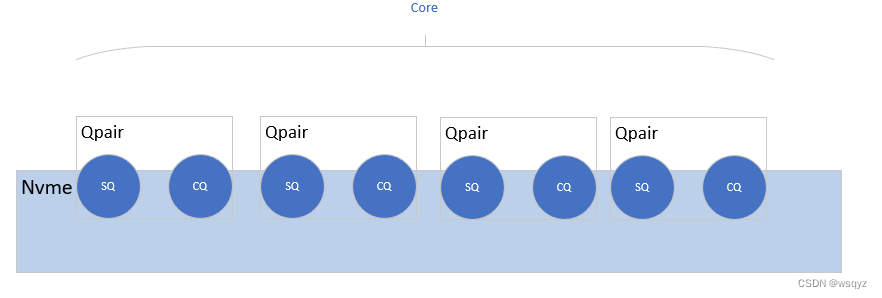
当queue depth为128,qpair数量为4时,平均分配到每个qpair的io个数为32个。perf的IO下发流程为:
1、向每一个qpair下发32个IO;
2 、busy polling这个4个qpair;
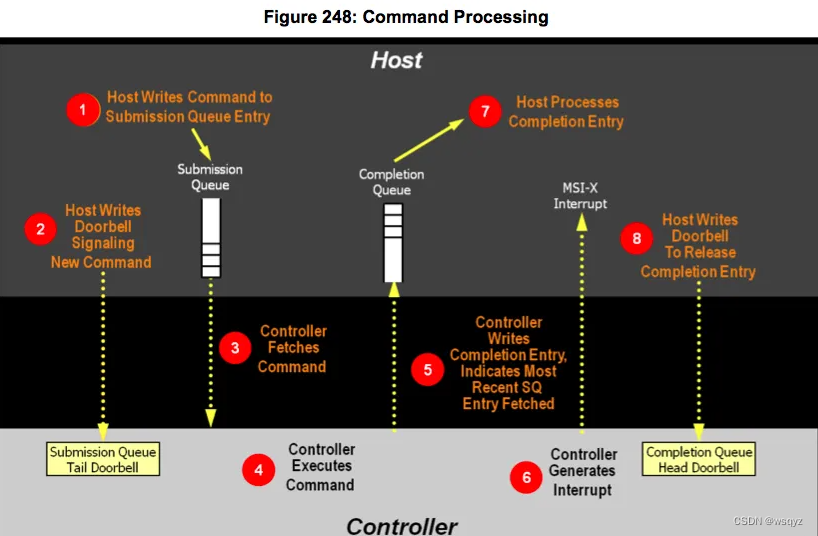
(1) 第一次批量下发IO,此时还没有doorbell SQ,无法poll到completion;触发doorbell SQ;
通过函数nvme_pcie_qpair_ring_sq_doorbell完成,此时相当于批量提交过个cmd;
(2) poll到32个completions,同时在每一个completion的回调中,再次submit一个IO;
(3) 积累到32个completions,同时也下发了32笔IO,一次doorbell SQ和CQ;
再次doorbell SQ,以及doorbell CQ;
需要注意的是,每次poll到一个completion,都会执行completion的回调,最终再一次性的doorbell CQ,
因此doorbell CQ之前,可能已经消费了不止一个completion,
doorbell CQ的目的,是为了更新completion queue的队列head信息;
(4) 继续polling completion;
hardcode最大的poll completions个数为128个
基于上面的分析,在128的队列深度里,使用1qpair进行doorbell的次数还要小于4qpair(因为使用1个qpair时,这个qpair的队深度是128,刚好为max poll completions)。但是显然,在这种情况下,doorbell的差异,并不能引起明显的性能差异。
结论
基于SPDK的nvme驱动替代libaio作为底层的存储engine,PureFlash的磁盘IO engine中的spdk engine采用了类似的io模型,详细文章见PureFlash with SDPK
补充
截取了两个网络上的截图,帮助理解SQ和CQ:
















 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









