







目录
count()函数的正确使用
count()函数用于统计SQL Server表中的记录行。但是当表中存在NULL的内容时,那么如下3种写法的结果将不一样:
select count(*)
select count(1)
select count(列名)
我们创建一个表,然后循环插入5000条记录,并做查询对比
--创建一个test表
CREATE TABLE test (
id UNIQUEIDENTIFIER DEFAULT NEWID() NOT NULL PRIMARY KEY CLUSTERED,
sequence INT NOT NULL,
data CHAR(50) NOT NULL DEFAULT '',
data_null CHAR(50)
);
--循环插入5000条记录
--注意:
-- data字段填充了''
-- data_null字段填充了NULL
SET NOCOUNT ON
DECLARE @i INT;
SET @i = 0;
WHILE @i < 5000
BEGIN
INSERT test (sequence)
VALUES (@i);
SET @i = @i + 1;
END;
GO我们使用上述3种写法分别统计这个表的记录数:
SELECT
COUNT(*),
COUNT(4),
COUNT(t.data),
COUNT(t.data_null)
FROM test t如下所示,count(t.data_null)显示为0,即select count(列名)将过滤NULL的记录:
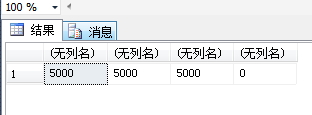
同时可见,count(*)/count(4)的写法等价。
使用兼容性视图替换count()函数
当SQL Server记录行在百万或上千万时,使用count()函数可能需耗时2~3秒或更长时间,这将出现短暂的锁表。那么对于聚集索引表我们可使用兼容性视图中的sys.sysindexes进行高效的查询(如下SQL对堆表同样适用)
SELECT
rowcnt
FROM sys.sysindexes s
WHERE id = OBJECT_ID('test')
AND s.indid < 2 其中s.indid的含义如下:
0 = Heap
1 = Clustered index
>1 = Nonclustered index另需注意这个兼容性视图无法过滤记录行,只能返回表的总记录数
参考资料
COUNT (Transact-SQL)
https://msdn.microsoft.com/en-us/library/ms175997%28v=sql.100%29.aspx















 4711
4711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









