







过拟合问题
到现在为止,我们已经学习了线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。
现在来看看什么是欠拟合,过拟合,和刚好符合。
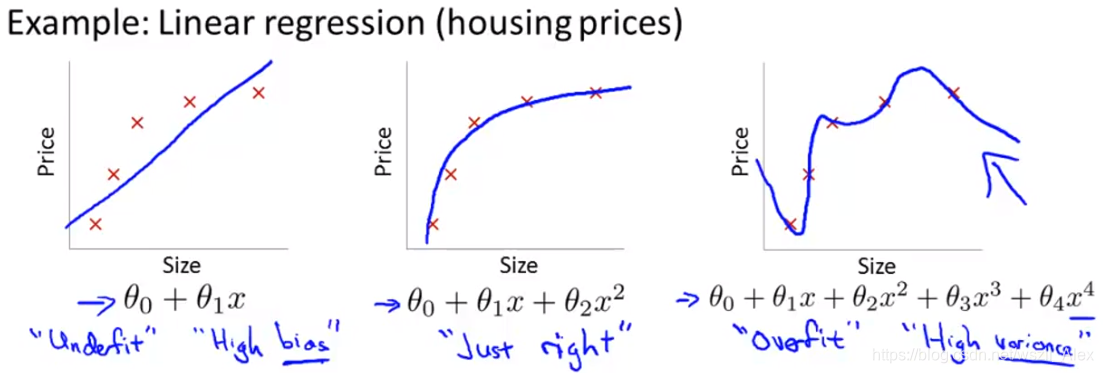
下图为房价问题的线性回归模型。
其中左图为欠拟合(underfitting),也可以说算法具有高偏差(bias)。可以看出,它没有很好的拟合训练数据。
高偏差的意思是,如果拟合一条直线,就好像算法有一个很强的偏见或者很大的偏差,认为房屋价格和房屋面积线性相关,而罔顾数据于不顾,先入为主的拟合一条直线,最终导致拟合数据效果很差。
右图是另一个极端,叫做过拟合(overfitting),也可以说算法具有高方差。可以看出,曲线似乎很好的拟合了训练集,它通过了所有的数据点,但这是条扭曲的曲线,不停的上下波动,我们并不认为它是个预测房价的好模型。
高方差的意思是,如果我们拟合一个高阶多项式,假设函数几乎能拟合所有的数据,该假设函数可能面临变量太大或太多的问题。如果我们没有足够的数据来约束它,来获得一个好的假设函数,这就是过拟合。
中图介于两图之间,恰好定义也在欠拟合和过拟合之间,叫做刚好合适(just-right)。可以看出,该二次曲线刚好拟合了这些数据,并且曲线很平稳哦!
总结下过拟合的定义
过拟合:在变量过多时,可能出现过拟合现象。这时训练出的假设函数能很好的拟合训练集数据,也就是说你的代价函数可能非常接近于0或者恰好为0(如右图所示),但是无法泛化到新样本中(预测新样本的房屋价格)。
泛化的意思是,一个假设模型应用到新样本的能力,此处新样本指没有出现在训练集中的房子。

同样的,逻辑回归莫模型中也会出现此种问题。
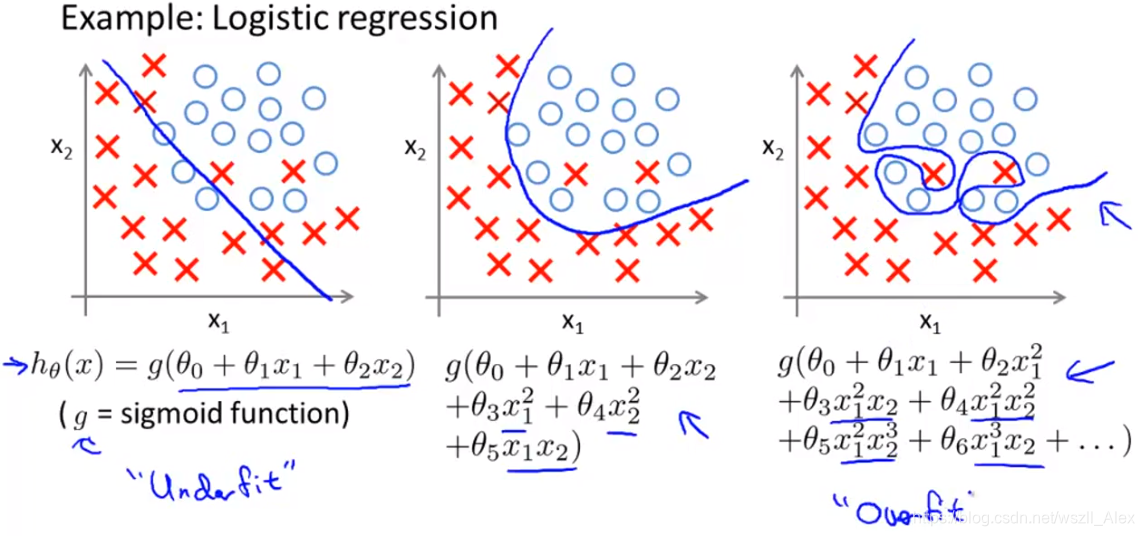
过拟合问题出现时,我们如何解决呢?

以房价问题为例,假设我们现在有100个特征,通过图形观察判断使用哪个模型变得不可行。下面有一些建议:
1.减少特征的数量
- 根据人工判断去选择重要的特征
- 使用模型选择算法
2.正则化
- 保留所有特征,减小参数 θj的量级














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









