







探索新浪网:使用 Python 爬虫获取动态网页数据
引言
可以实战教爬虫吗,搭个环境尝试爬进去。尝试收集一些数据
一位粉丝想了解爬虫,我们今天从最基础的开始吧!
本文将介绍如何使用 Python 爬虫技术爬取新浪网首页的内容。新浪网作为一个内容丰富且更新频繁的新闻网站,是理解动态网页爬取的绝佳例子。
准备工作
首先,确保你已安装 Python 以及 requests、BeautifulSoup 和 lxml 库。
这可以通过以下命令轻松完成:
pip install requests beautifulsoup4
选择目标
对于我们的第一个项目,让我们选择一个简单的网站进行数据抓取。为了简单起见,我们可以选择一个新闻网站或天气预报网站。这些网站通常有清晰的结构,适合初学者练手。
新浪网的结构
新浪网的首页包含了多个新闻类别,如国内新闻、国际新闻、体育新闻等。我们的目标是提取特定类别下的新闻标题和链接。
编写爬虫代码
爬取example.com
作为示例,我们将使用一个简单的网站 - “example.com”。
import requests
from bs4 import BeautifulSoup
def scrape_example_com():
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
text = soup.get_text().strip()
return text
print(scrape_example_com())
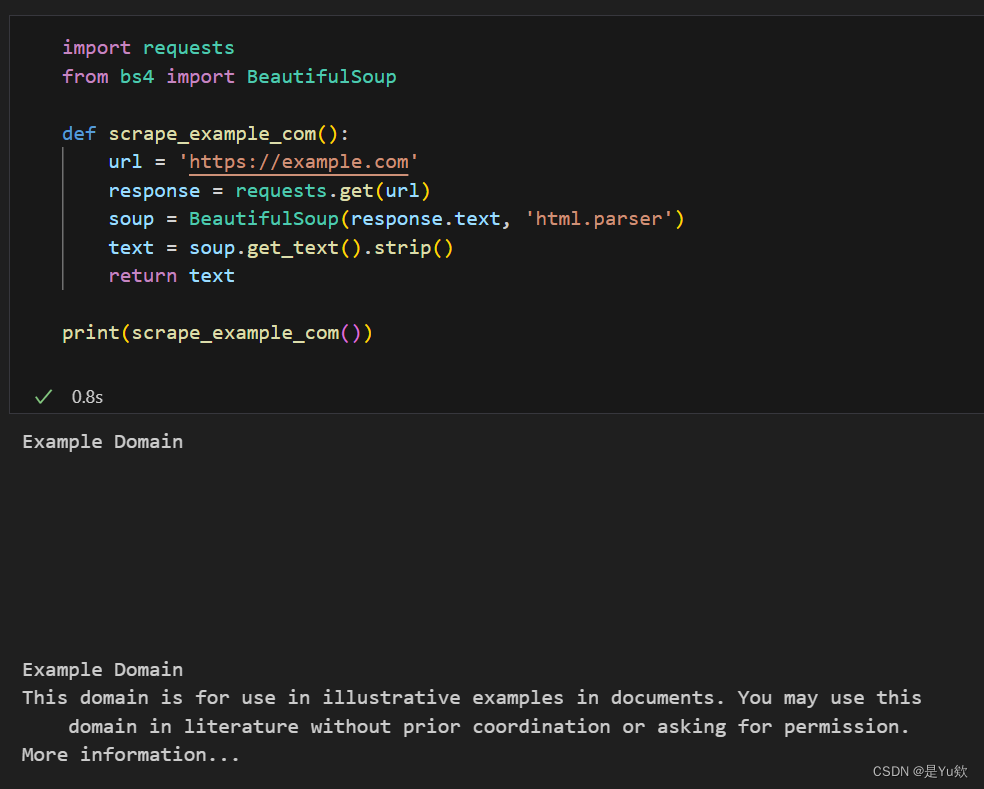
requests.get发送一个请求到网站,并获取响应。BeautifulSoup解析响应内容,使其更易于操作。get_text方法提取页面的文本内容。
爬取新浪首页部分内容
下面是一个 Python 脚本的示例,用于爬取新浪网首页的部分内容:
import requests
from bs4 import BeautifulSoup
def scrape_sina_news():
url = 'https://www.sina.com.cn/'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'lxml', from_encoding='utf-8')
news_titles = soup.find_all('a')
for title in news_titles[:10]:
if 'href' in title.attrs:
print(title.text.strip(), title['href'])
scrape_sina_news()
解析代码
这段代码发送一个请求到新浪网首页,然后使用 BeautifulSoup 和 lxml 解析器来提取新闻链接。
requests.get发送一个请求到网站,并获取响应。BeautifulSoup解析响应内容,使其更易于操作。get_text方法提取页面的文本内容。
注意: KeyError: 'href'
出现 KeyError: 'href' 这个错误表明在尝试访问某些 <a> 标签的 href 属性时出现了问题。这通常发生在某些 <a> 标签中不存在 href 属性的情况。
可以修改代码,在尝试访问 href 属性之前先检查它是否存在。这样可以防止 KeyError 的出现,并确保只处理那些实际包含链接的元素。
结果与展示
运行此脚本会在控制台中打印出新浪网首页上前10个新闻链接的文本和 URL。
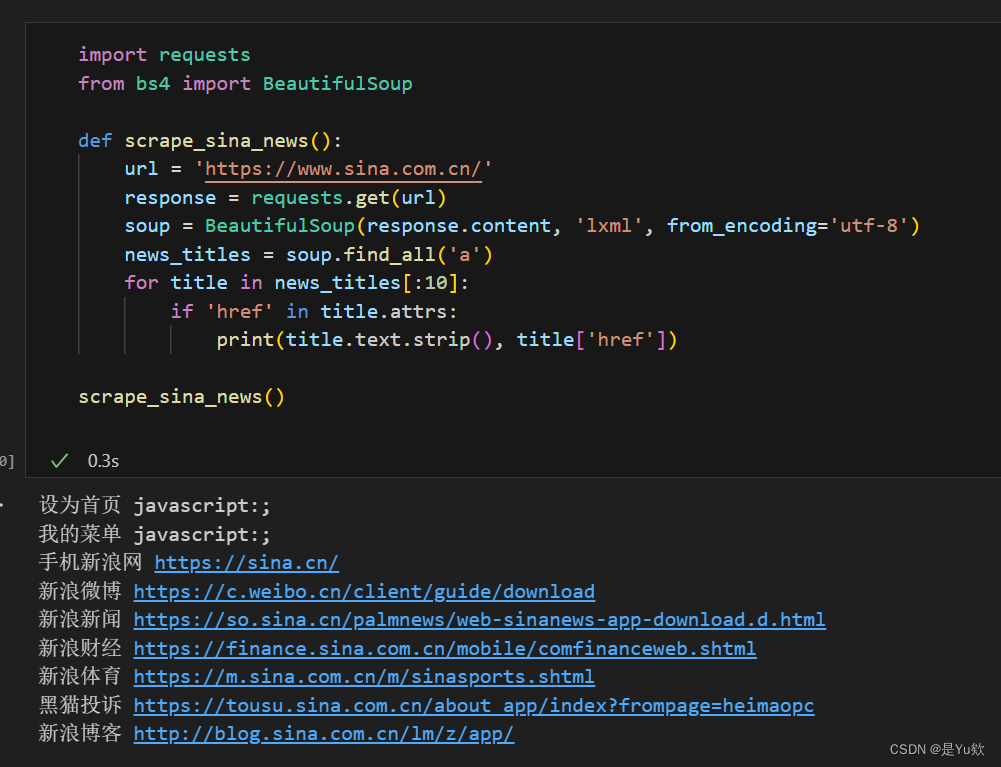
其他
修改和适应
当你想要从不同的网站抓取数据时,你需要根据目标网站的结构来调整代码。使用开发者工具(在大多数浏览器中通过右键点击网页并选择“检查”即可访问)来查看网页的HTML结构是很有帮助的。
注意事项
在编写和运行网络爬虫时,要始终遵守网站的robots.txt规则和版权法。同时,要尊重网站服务器,避免发送过多请求导致服务器负载过重。
总结
通过爬取新浪网,我们学习了如何处理中文和动态加载内容的网站。Python 爬虫技术能够帮助我们从各种网页中提取有用信息,为数据分析和研究提供支持。
这篇博客提供了一个实际的网络爬虫例子,旨在帮助你来理解和实践如何爬取和处理来自复杂网站的数据。希望这对你有所帮助,如果有任何问题,请随时提问。
















 2938
2938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











