






#教程
主要参考开源免费离线语音识别神器whisper如何安装,
OpenAI开源模型Whisper——音频转文字
Whisper是一个开源的自动语音识别系统,它在网络上收集了680,000小时的多语种和多任务监督数据进行训练,使得它可以将多种语言的音频转文字。
Whisper的好处是开源免费、支持多语种(包括中文),有不同模型可供选择,最终的效果比市面上很多音频转文字的效果都要好。
Whisper目前有5个模型,随着参数的变多,转文字的理解性和准确性会提高,但相应速度会变慢:
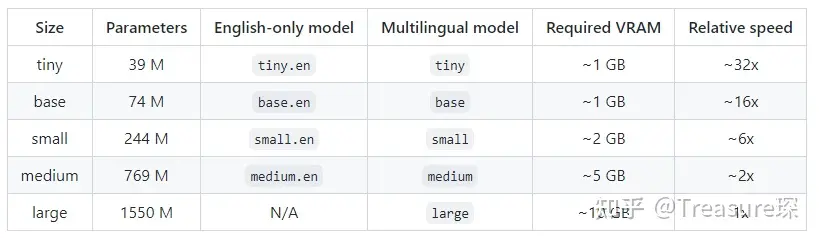
这篇文章会介绍怎样安装和使用Whisper进行音频转文字。
系统环境
官方说他们使用的是Python 3.9.9 and PyTorch 1.10.1来训练和检验的程序,但预计兼容python 3.7以后的版本和pytorch近期更新版本。 大家在安装whisper的时候请尽量保证python版本与官方一致或更新版本,或者至少是3.7版本以后,这样可以避免一些版本不同导致的莫名奇妙的错误。 本文测试系统为windows1064位、python版本3.9.13和windows10 64位、python3.7.5版本.
安装步骤
它还需要一些依赖。比如ffmpeg、pytorch等。本文没涉及python的安装,默认读者是已经安装好python的,如果你不会安装python的话,建议去视频平台搜索安装教程,安装好后再来进行下面的步骤。
1、安装chocolatey
安装chocolatey是为了后面方便在Windows中安装ffmpeg。
chocolatey安装
以管理员身份打开Powershell,运行:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
2、安装ffmpeg
安装好chocolatey后,以管理员身份打开Powershell,输入:
choco install ffmpeg
3.pytorch的安装
这里我们使用pip安装。
打开pytorch.org,下拉页面。
按照下图选择要安装的版本。我选择的是稳定版,windows系统,pip安装方式,python语言、cpu版本的软件。
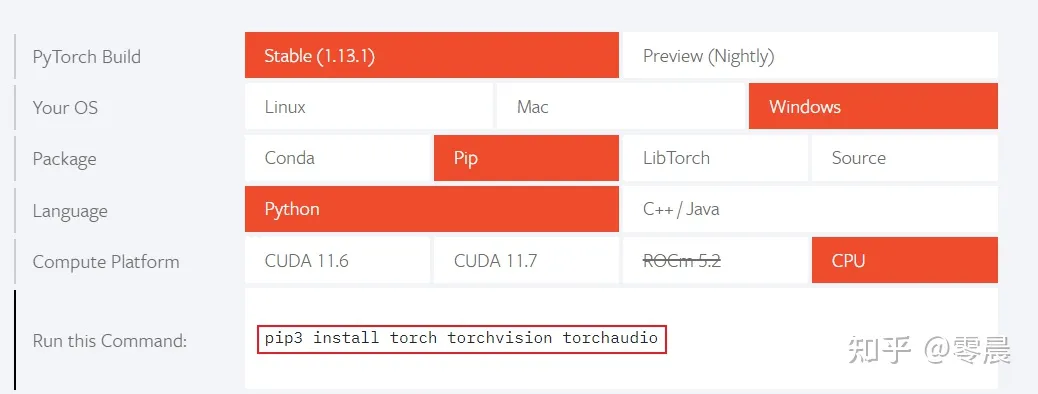
选择好后上图中框选的那行代码就是使用pip安装pytorch的命令。 在命令行界面运行
pip3 install torch torchvision torchaudio
安装pytorch,安装好后这一步也就完成了。
4.whisper的安装
以上步骤都完成后。 按照官方文档,先运行
pip install git+https://github.com/openai/whisper.git
然后再运行
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
完成whisper的安装。
whisper的简单使用
我们准备一段音频,使用whisper将其转换成文字。 以此音频为例:
在音频所在文件夹中右键打开cmd窗口。 (如果是win10的话就在文件夹的空白处按住shift,然后鼠标右键单击,打开powershell窗口)
输入whisper audio.mp3,回车运行。在命令行窗口中显示的是转写结果,同时在当前文件夹下生成三个字幕文件。以下是三种格式的对比。
更换转写模型
以上whisper audio.mp3的命令形式是最简单的一种,它默认使用的是small模式的模型转写,我们还可以使用更高等级的模型来提高正确率。 比如
whisper audio.mp3 --model medium
medium模型耗费时间更长,但也更精准。一般而言,综合权衡速度与精准度,选择small也够用了,如果你对语言识别的精准度高可以使用medium,medium的精准度已经相当高了,如我文章开头所说,我用medium模式识别了我读的一段5min的音频,400多字。正确率基本百分百,只错了2个英文单词,还是因为我发音不准,尴尬。
当然还有其他的模型可供选择,可以在命令行运行whisper --help查看帮助。 有以下11种模式可供选择。
[--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}]
结语
本文简单介绍了whisper的用途、在windows系统下安装部署whisper的方法以及whisper的简单用法。
关于whisper的使用部分仅介绍了命令行模式的使用方法,如果你会使用python,也可以使用以下代码来运行whisper。
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
了解更多请参考官方文档。
或者如果你想要在网页上运行whisper,可以安装Whisper Webui。 可以参考:














 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









