









论文:
Lightweight End-to-End Speech Recognition from Raw Audio Data Using Sinc-Convolutions
摘要:
许多端到端自动语音识别(ASR)系统仍依赖于经过预处理的频域特征,这些特征是手工制作的以模仿人类的听力。集成可学习特征提取的最新进展推动了我们的工作。为此,文本提出了将Sinc卷积与深度卷积相结合的轻型Sinc卷积(LSC),作为端到端ASR系统的低参数机器学习特征提取。
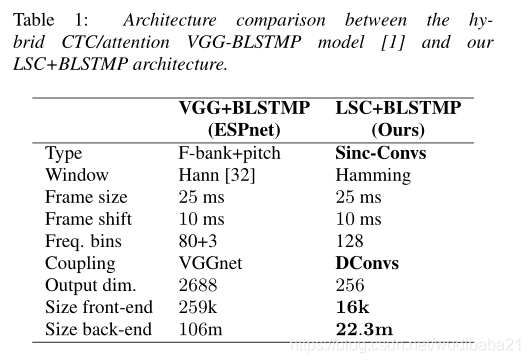
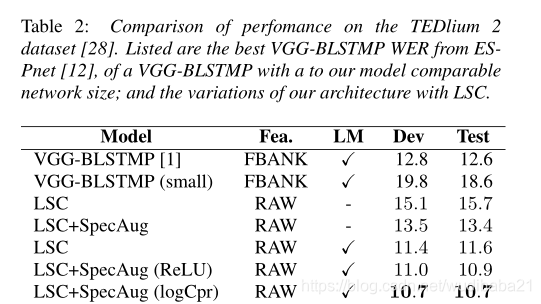
本文将LSC(轻型Sinc卷积)融合进CTC/attention 架构进行评估,最终的端到端模型显示出平滑的收敛行为,通过在时域中应用SpecAugment可以进一步改善收敛效果。我们还将讨论过滤器级别的改进,例如使用对数压缩作为激活函数。本文的模型在TEDlium v2测试数据集上的单词错误率达到10.7%,比具有log-mel滤波器组功能的相应体系结构绝对高出1.9%,但模型大小只有21%。
引言:
描述了端到端语音识别系统的优点:直接可以将语音转为文字,不需要通过太复杂的中间表示,可参数化的Sinc卷积的最新进展使特征提取作为可学习的部门集成到神经网络中[1,2,3]。在这项工作中,本文提出了集成到ASR神经网络中的轻量级机器可学习特征提取,以直接对原始音频中的句子进行分类。为此,我们扩展了已建立的混合CTC /attention 注意系统的体系结构,该体系结构结合了两种用于端到端ASR的主要技术:经过连接主义时间分类(CTC )训练的神经网络计算每个令牌在输入序列中给定的时间步长。基于注意力的编码器-解码器体系结构[9]被作为序列生成模型进行训练,以将输入序列转换为转录的令牌序列。称其为拟议的扩展轻量SincConvolutions(LSC);它结合了Sinc卷积和深度卷积。
- 提出了轻量级Sinc-卷积:一种低参数前端,可以将其集成到端到端ASR架构中,以从原始音频进行解码
- 为了进行性能评估,本文将LSC集成到CTC/attention ASR中
- 结合大容量语言模型,在TEDlium v2上可以实现10.7的竞争性错误率
相关工作
[4]在频谱图特征上训练端到端神经网络,只有少数架构直接对原始音频进行分类[5],端到端语音识别有两种主要技术:(1)连接主义者的时间分类(CTC)将隐马尔可夫状态的概念传递到端到端神经网络,作为序列分类网络的训练损失。经过CTC损失训练的神经网络将计算输入序列中给定时间步长下每个字母的后验概率。 (2)基于注意力的编码器-解码器体系结构[9]被训练为自回归序列生成模型。编码器将输入序列转换为潜在表示。由此,解码器生成句子转录。机器语言翻译领域中提出了基于注意力的序列转录,随后将其应用于语音识别。我们的工作建立在混合CTC / Attention ASR系统的基础上,该系统将CTC与位置感知的注意力机制相结合。借助浅层融合,在集成到解码过程中的RNN语言模型(RNNLM)的帮助下执行句子转录。具有滤波器结构的可参数化卷积在原始音频数据上比单独的CNN具有更好的收敛性能。
系统架构
前端
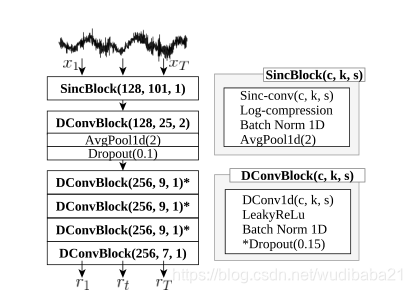
拟议的轻量Sinc卷积(LSC)。原始音频流被划分为帧。然后将可参数化的Sinc卷积和多层DConv应用于特征的轻量提取
在Sinc卷积层之后是多个深度卷积(DConvs),用于提取更高级别的潜在表示。 DConv为每个输入通道使用单独的内核,从而减少了cininput和cout = n·cin,n∈N个输出通道以及大小为k的内核(从cin·cout·k到cout)的DConv层的参数数量。它们
沿时间维度提取短时上下文,但仅限于一帧内的数据。该架构的这一部分充当Sinc卷积信号与ASR后端网络之间的耦合层。 LSC受到Mittermaier等人的轻量级关键字发现架构的启发。 本论文的适应性主要省略了帧间逐点卷积,以进一步减少参数的数量。与逐点卷积相比,DConv对高级特征的贡献更大,而仅占可学习参数的一小部分。
后端
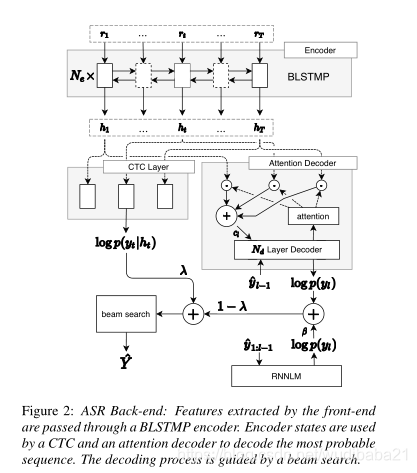
实验
语料:200多个小时TEDlium
数据帧:25ms为一帧,帧移10ms,
优化器:ADadelta
epoch:22
Sinc卷积由128个Sinc滤波器组成,这些滤波器实验mel滤波器权重进行了初始化,对于我们网络的编码器,我们选择使用四个BLSTM层,其投影神经元的大小为512。解码器是单个LSTM层,大小为512,同时还有一个注意层,其大小也为512。我们选择0.5作为我们的CTC /Attention注意权重,由SentencePiece创建,以500字母组合的单位作为令牌进行训练。
数据增强:频谱增强以及时间扭曲
实验结果
结论
许多端到端ASR系统仍然依赖于预处理的fBank功能。本文的工作扩展了具有前端的现有ASR系统,以直接从我们称为轻量级Sinc卷积(LSC)的原始音频中进行分类。精心选择了它的网络架构,使其轻巧,即使用较少的参数,这对于电池驱动设备中的语音识别是一个优势。我们讨论了对该体系结构的进一步改进,例如对数压缩作为激活函数,以及基于时间的数据增强的频谱增强。当与大型RNN语言模型结合使用时,我们的最终模型实现了10.7%的单词错误率,比相应的f-Bank架构的最佳报告模型提高了1.9%的绝对值,但模型大小只有21%
参考文献
- M. Ravanelli and Y . Bengio, “Speaker recognition from raw wave-form with sincnet,” in 2018 IEEE Spoken Language Technology Workshop (SLT), Dec 2018, pp. 1021–1028.
- M. Ravanelli and Y . Bengio, “Speech and speaker recognition from raw waveform with sincnet,” in arXiv preprint arXiv:1812.05920, 2018.
- M. Ravanelli and Y . Bengio, “Interpretable convolutional filters with sincnet,” in NIPS 2018 Interpretability and Robustness for Audio, Speech and Language Workshop, 2018.
- A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos,E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates et al.,“Deep speech: Scaling up end-to-end speech recognition,” arXiv preprint arXiv:1412.5567, 2014.
- K. Kumatani, S. Panchapagesan, M. Wu, M. Kim, N. Strom,G. Tiwari, and A. Mandai, “Direct modeling of raw audio with dnns for wake word detection,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Dec 2017, pp.252–257


















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









