






一、背景&思路简述
-
背景:工作中进行消费者分析的时候,需要将消费者按多种维度分为多个人群进行研究(也就是人群分层),然后将购买心智的相似的人群进行合并
-
思路:计算两两人群之间的心智距离,呈现人群距离矩阵,再以层次聚类图的形式展现,最后根据实际业务情况,设置合理阈值,进行人群合并
举例:
- 现将消费者按年龄和性别分为6个人群,如下
人群 名称 人群1 26岁以下女性 人群2 26岁以下男性 人群3 26-35岁女性 人群4 26-35岁男性 人群5 36岁以上女性 人群6 36岁以上男性
人群心智距离计算方式:根据业务有所不同,所以在此不做展示
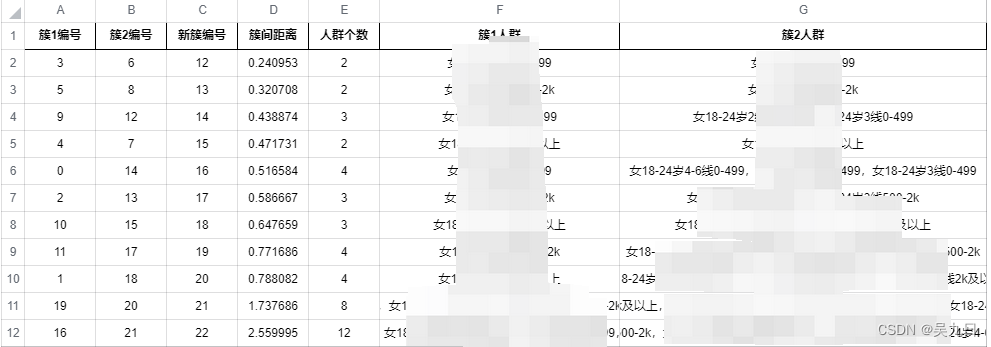
人群距离矩阵如下
两两人群距离 人群1 人群2 人群3 人群4 人群5 人群6 人群1 0 0.2 0.4 0.2 0.1 0.3 人群2 0.2 0 0.1 0.5 0.2 0.2 人群3 0.4 0.1 0 0.4 0.1 0.3 人群4 0.2 0.5 0.4 0 0.3 0.4 人群5 0.1 0.2 0.1 0.3 0 0.1 人群6 0.3 0.2 0.3 0.4 0.1 0
- 人群聚类代码(生成层次聚类图)如下
import pandas as pd from matplotlib import pyplot as plt import scipy.spatial.distance as ssd from scipy.cluster.hierarchy import dendrogram, linkage import matplotlib comb_dist_matrix = pd.DataFrame([[0,0.2,0.4,0.2,0.1,0.3],[0.2,0,0.1,0.5,0.2,0.2],[0.4,0.1,0,0.4,0.1,0.3],[0.2,0.5,0.4,0,0.3,0.4],[0.1,0.2,0.1,0.3,0,0.1],[0.3,0.2,0.3,0.4,0.1,0]],index = ['人群1','人群2','人群3','人群4','人群5','人群6'],columns = ['人群1','人群2','人群3','人群4','人群5','人群6']) d = ssd.squareform(comb_dist_matrix) d = linkage(d, method='ward') # 绘制层次聚类图 hc = plt.figure(figsize=(60, 40)) # 设置图片大小 matplotlib.rc("font",family = "Microsoft YaHei" ) # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.xticks(fontsize = 50) # 设置x坐标轴字体大小 dendrogram(d, labels=comb_dist_matrix.index, leaf_font_size=50, orientation='right') #leaf_font_size用来设置人群标签字体大小,orientation用来设置图片的方位 plt.show()
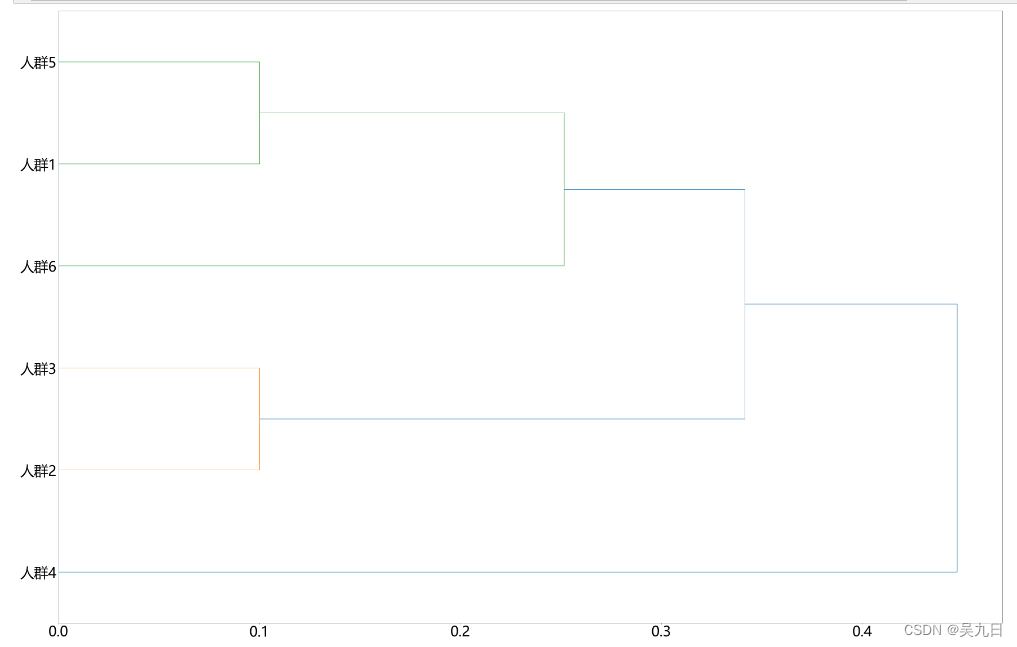
- 人群聚类结果(层次聚类图)如下
- 设置阈值为0.2,则将人群1和人群5合并,人群2和人群3合并,最终得到4个人群
- 问题:人群数量过多时,层次聚类图很难直观地进行解读,因此需要对人群聚类的展现形式做一个优化(PS:基于人群距离的计算方法,无法使用k-means等算法直接进行散点图的绘制)
- 目标:改成更直观的散点图形式
二、散点图绘制方案
基于原始方案层次聚类的过程,输出每个人群的坐标轴,画出散点图
3.2 解决过程
方案一:根据距离矩阵计算坐标轴(比较难实现),假设有ABCD四个点,点A、B可以根据AB的距离确定位置,点C可以根据AC和AB的距离确认位置,但是点D只能根据AD、AB、AC其中的两个距离来确定位置,无法同时满足三个距离,Pass
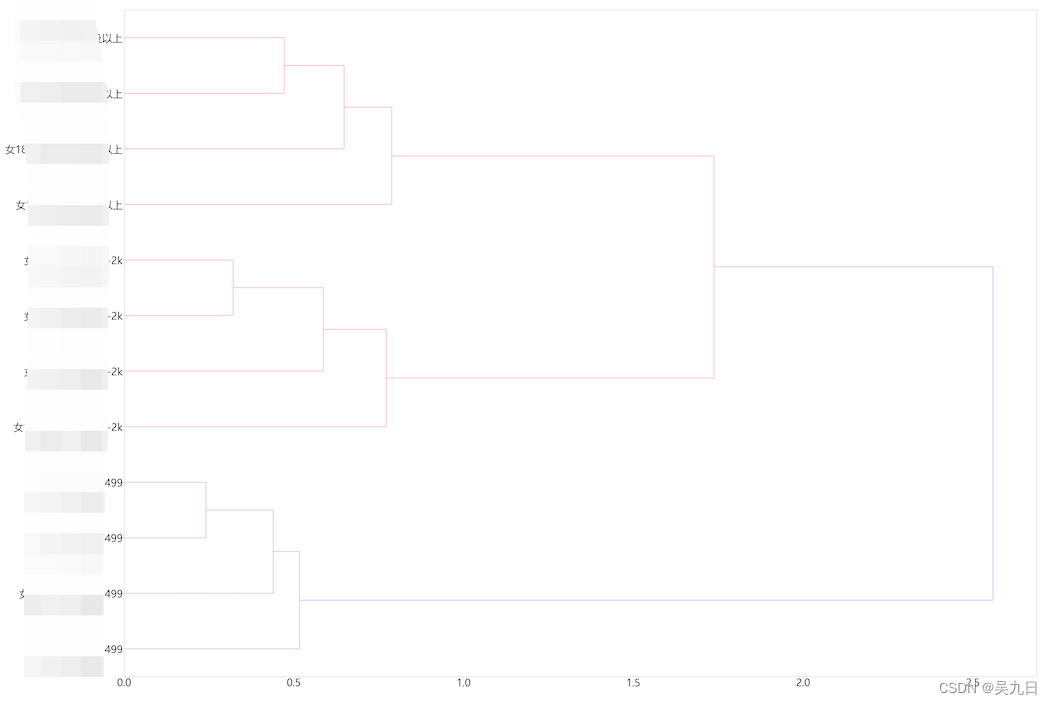
方案二:既然不能满足距离矩阵中的所有值,那只要满足层次聚类图所涉及到的距离即可,即用散点图的形式实现层次聚类过程,上述举例的层次聚类图聚合过程如下:
- S1:首先是【女18-24岁2线0-499,对应人群编号为3】和【女18-24岁3线0-499,对应人群编号为6】进行聚合,该两人群之间的距离为0.240953,他们聚合后新的组合人群,编号为12
- S2:其次是【女18-24岁2线500-2k,对应人群编号为5】和【女18-24岁3线500-2k,对应人群编号为8】进行聚合,该两人群之间的距离为0.320708,他们聚合后新的组合人群,编号为13
- S3:再往下是【女18-24岁4-6线0-499,对应编号为9】和【由S1得到的组合人群12】进行聚合,距离为0.438874…以此类推
基于方案二,映射到散点图的坐标求解上(从大簇往小簇求解),其中为了避免最后散点呈一条直线,所以制定了统一的规则:如果父人群是x/y轴保持一致、则子人群是y/x轴保持一致,过程如下:
- S1:设定 最终生成的族22(即所有人群聚合在一起的编号)一个坐标轴,假设就为原点(0,0)
- S2:簇22由簇16和簇21组成,两者之间的距离为2.559995,假设16和21的X轴相同,以簇22为中心,那坐标分别为(0,2.559995 / 2)、(0,-2.559995 / 2)
- S3:簇16 由簇0和簇14 组成,两者之间的距离为0.516584,假设0和14的y轴相同,以簇16为中心,那坐标分别为(0.516584/2,2.559995 / 2)、(-0.516584/2,-2.559995 / 2),其中簇0即为单个人群【女18-24岁1线0-499】最终的坐标轴
- S4:以此类推,直到求得每单个人群的坐标轴
- S5:去掉人群聚合的簇,只留下单个人群簇
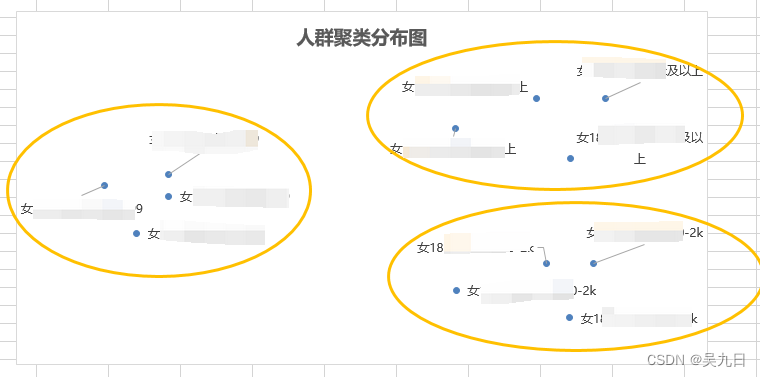
最终的效果图如下:
【注意】
(1)人群的坐标轴并没有实际业务上的意义
(2)只作为人群聚合的参考作用,虽然人群距离并非是距离矩阵中的实际值,但可以反应大致的人群远近趋势
三、代码实现
import pandas as pd
from matplotlib import pyplot as plt
import scipy.spatial.distance as ssd
from scipy.cluster.hierarchy import dendrogram, linkage
from itertools import combinations
import math
import os
import re
import matplotlib
# 绘制散点图
data = pd.read_excel('%s/04_各层次人群.xlsx' % (output_path))
x_list = []
y_list = []
people_label = []
people_num = data.shape[0]+1
count = 1
df_index = data.shape[0]-1
value = data.iloc[df_index,2]
traverse1(data,value,0,0,count)
# 去掉散点图多余的中心点
del_index = []
for i in people_label:
if i >= people_num:
del_index.append(people_label.index(i))
people_label = [people_label[i] for i in range(len(people_label)) if i not in del_index]
people_name = []
for i in people_label:
try:
tmp_index = data[data.iloc[:,0] == i].index.to_list()[0]
people_name.append(data.iloc[tmp_index,5])
except:
tmp_index = data[data.iloc[:,1] == i].index.to_list()[0]
people_name.append(data.iloc[tmp_index,6])
x_list = [x_list[i] for i in range(len(x_list)) if i not in del_index]
y_list = [y_list[i] for i in range(len(y_list)) if i not in del_index]
# x_y_coordinates = list(zip(x_list,y_list))
df = pd.DataFrame()
df['人群编号'] = people_label
df['人群名称'] = people_name
df['人群坐标_x'] = x_list
df['人群坐标_y'] = y_list
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(1,1,1)
ax1.scatter(x_list,y_list)
for i in range(0,len(x_list)):
ax1.annotate(people_name[i],xy = (x_list[i],y_list[i]),fontsize = self.fontsize_scatter)
plt.show()
hc.savefig(r'%s/05_人群散点图.jpg' % (output_path))
print("已生成:05_人群散点图.jpg")
df.to_excel(r'%s/06_散点图坐标.xlsx' % (output_path),index=False)
print("已生成:06_人群散点图坐标.xlsx")















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









