







相关内容为CSDN博主「莫莫莫i」的原创文章:https://blog.csdn.net/wmymo/article/details/107815217
目标检测需要解决的问题
1 物体位置
2 物体种类
目标检测中重要的名词
1 bounding box(简称:bbox)
2 ground truth bounding box(简称:gd)
3 predicted bounding box(简称:pd)
 评价pd相对于gd的好坏,即IOU。
评价pd相对于gd的好坏,即IOU。
 在two stage算法中,需要先找出候选去,然后识别候选区的对象。
在two stage算法中,需要先找出候选去,然后识别候选区的对象。
one stage算法中,没有真正的去掉候选区,而是划分了7×7的网格区域在每个区域会预测两个bbox,所以一共会预测98个bbox。
YOLOv1
YOLOv1网络结构
 输入448x448x3图像,最后得到7x7x1024的feature map。之后将其输入到局部连接层,后接dropout层,最后接1715的全连接,最后reshape成7x7x35的输出tensor。真个网络使用的是leakyRelu激活函数。最后一层的输出没使用激活函数,所以输出是logit。(由于最后输出的tensor是通过全连接得到的,所以每一个像素点包含了整个输入图片的信息。)7x7x35的含义,每一个1x1x35会负责原始图像64x64的区域。
输入448x448x3图像,最后得到7x7x1024的feature map。之后将其输入到局部连接层,后接dropout层,最后接1715的全连接,最后reshape成7x7x35的输出tensor。真个网络使用的是leakyRelu激活函数。最后一层的输出没使用激活函数,所以输出是logit。(由于最后输出的tensor是通过全连接得到的,所以每一个像素点包含了整个输入图片的信息。)7x7x35的含义,每一个1x1x35会负责原始图像64x64的区域。

YOLOV1的Bbox置信度:
公式为:
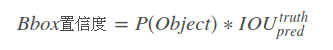
P
(
O
b
j
e
c
t
)
P(Object)
P(Object) 表示是否存在待检对象。
在训练阶段,如果这个像素点的“负责”的区域没有
g
d
gd
gd,则
P
(
O
b
j
e
c
t
)
=
0
P(Object)=0
P(Object)=0 ,反之为 1 。然后就是计算
g
d
gd
gd 和
p
d
pd
pd 的
I
O
U
IOU
IOU 的值。
Bbox 置信度表达了这个像素点对应的“负责”区域有没有,且 Bbox 准不准的程度。反应了 Bbox 的准确性程度。
要注意,Bbox置信度虽然有多个,(一个像素点对应的负责区域会有多个 Bbox,比如这里是2个)。但我们只看和
G
r
o
u
d
T
r
u
t
h
GroudTruth
GroudTruth
I
O
U
IOU
IOU 大的那个,另外一个自动设定为 0 。Bbox 置信度的大小期望在 [0, 1] 之间。
YOLOV1的Bbox的坐标:
2 个 Bbox 需要 8 个值进行存储。
( b x , b y , b w , b h ) × 2 (bx,by,bw,bh)×2 (bx,by,bw,bh)×2
我们主要需要看一下
g
d
gd
gd 的
B
b
o
x
Bbox
Bbox 的坐标表示。
g
d
gd
gd 的
B
b
o
x
Bbox
Bbox 坐标会做一些变换(编码)。
g
w
,
g
h
gw,gh
gw,gh会除以图像对应的
i
m
g
w
,
i
m
g
h
imgw,imgh
imgw,imgh,从而使得
g
w
,
g
h
gw,gh
gw,gh归一化到 [0,1] 之间。直接让
b
x
,
b
y
bx,by
bx,by回归
g
d
gd
gd 的
g
x
,
g
y
gx,gy
gx,gy 会有一定难度,既然我们已知
g
x
,
g
y
gx,gy
gx,gy一定在对应的“负责”区域内。所以我们将
g
x
,
g
y
gx,gy
gx,gy 相对于负责区域的左上角坐标进行归一化,从而使得
g
x
,
g
y
gx,gy
gx,gy 也归一化到 [0,1] 之间。
在训练时,希望两个框同时工作,但真正计算损失的时候,我们只去对 IOU 最大的框进行梯度下降和修正。类似于一个相同的工作,让两个人一起做,为了保障工作正常完成。在训练最后,会发现两个框意见开始出现了分工,比如一个框倾向于去检测细长型的物体。另一个框倾向于去检测扁宽型的物体。
总结一下就是,在训练阶段,输出的两个 Bbox 只会选择其中一个参与损失的计算(和 gd IOU大的那个)。
在测试阶段,输出的两个 Bbox 只有一个有实际预测的意义。
通过前面讲解,可以看到 YoloV1 至多只能预测 49 个目标,即每个“负责”区域输出一个目标。
注意!我们可以使用不止 2 个 Bbox,理论上 Bbox 越多效果越好,但是效率会降低。作者取两个 Bbox 的原因是因为性能和效率的取舍。
YOLOV1中具体对象的概率:
P
(
c
i
∣
o
b
j
e
c
t
)
=
0.6
P(ci | object)= 0.6
P(ci∣object)=0.6
表示这个像素点“负责“原始图像的区域“存在”对应对象的概率。注意,这里的前提是该网格中存在待检测的对象。每一个值的大小期望在 [0,1] 之间。如何定义前面说的“存在”对应对象呢?如果原始图像的待检目标的 bbox 的中心点在对应的“负责”区域内。则表示存在对应对象。

YOLOV1的损失函数
1 损失函数的输入,即标签值gd和预测值pd
2 损失函数的具体形式
通过上述Bbox坐标的讲解,训练样本都是动态变化的,和yolov1预测出的bbox的iou有关。





YOLOv2
基于yolo下,有了新的创新和启发:
1 引入anchor
2 改变ground truth bounding box的编码方式
3 引入PA层,尝试feature map的其他融合方式
4 联合训练
YOLOv2网络结构
YOLOV1中两个bbox各司其职,起到不同预测的效果,比如,一个预测长的,一个预测宽的。YOLOV2则指定一个先验框anchor,最终的检测bbox就是在anchor基础上做修正(two stage思想)
首先将原始图像划分为SxS的区域,然后在每个“负责”区域上设定先验的anchor框。这些框的长宽比均不相同。原始图像的anchor将映射到最终的输出的feature map上,后面的损失计算是相对于feature map上的anchor计算的。YOLOV2中,anchor的长和宽由k-means算法对训练数据聚类所得,在two stage中是人为设定的。
 注意这里 Kmeans 的距离定义如下:
d
i
s
(
A
,
B
)
=
1
−
I
O
U
(
A
,
B
)
dis(A,B)=1−IOU(A,B)
dis(A,B)=1−IOU(A,B)
注意这里 Kmeans 的距离定义如下:
d
i
s
(
A
,
B
)
=
1
−
I
O
U
(
A
,
B
)
dis(A,B)=1−IOU(A,B)
dis(A,B)=1−IOU(A,B)

 V2 这个模块(这个名字是博主自己起的)这个模块的目的期望减少 feature map 空间维度的同时尽量不损失信息。而且它具有了 split transform merge 的形式,一定程度上开始有了特征融合的感觉。
V2 这个模块(这个名字是博主自己起的)这个模块的目的期望减少 feature map 空间维度的同时尽量不损失信息。而且它具有了 split transform merge 的形式,一定程度上开始有了特征融合的感觉。
最后是网络的输出 tensor,这个输出 tensor 的含义如下:
N
×
N
×
B
×
(
C
+
5
)
N×N×B×(C+5)
N×N×B×(C+5)
N 表示输出特征图空间维度,B 表示 anchor 的个数,C 表示识别的类别个数,5 表示 Bbox 的坐标(4个)和 Bbox 的置信度(1个)。
YOLOV2的Bbox坐标
和 YoloV1 的思想一样,要将 ground truth bounding box的 Bbox 坐标进行编码(不同的是,现在是相对于 anchor 进行编码)
假设输出 tensor 的 Bbox 坐标为
(
t
x
,
t
y
,
t
w
,
t
h
)
(tx,ty,tw,th)
(tx,ty,tw,th)。由于最后的 tensor 只是线性层,所以理论上每一个值的值域 [−∞,∞]
假设 ground truth bounding box的映射到最后 feature map 的 Bbox 坐标为
(
g
x
,
g
y
,
g
w
,
g
h
)
(gx,gy,gw,gh)
(gx,gy,gw,gh)。现在我们需要将
(
g
x
,
g
y
,
g
w
,
g
h
)
(gx,gy,gw,gh)
(gx,gy,gw,gh)
相对于 anchor 进行编码。
假设 anchor 所在“负责”区域在最后 feature map 上对应的左上角坐标为
(
c
x
,
c
y
)
(cx,cy)
(cx,cy),对应的长宽为
p
w
,
p
h
pw,ph
pw,ph。注意这里用的是所在“负责”区域的左上角坐标)从 anchor 的 Bbox 变换到 ground truth bounding box 的 Bbox 的最简单方式就是对点做平移,对长宽分别做缩放。
x
坐
标
平
移
=
g
x
−
c
x
x坐标平移=gx−cx
x坐标平移=gx−cx
y
坐
标
平
移
=
g
y
−
c
y
y坐标平移=gy−cy
y坐标平移=gy−cy
宽
的
放
缩
=
g
w
/
p
w
宽的放缩=gw/pw
宽的放缩=gw/pw
长
的
放
缩
=
g
h
/
p
h
长的放缩=gh/ph
长的放缩=gh/ph
直接用
(
t
x
,
t
y
,
t
w
,
t
h
)
(tx,ty,tw,th)
(tx,ty,tw,th)去拟合上面几个值是不合理的,因为
(
t
x
,
t
y
,
t
w
,
t
h
)
(tx,ty,tw,th)
(tx,ty,tw,th) 的取值范围是 [−∞,∞] 。但坐标平移范围在 [0,1](因为最后 feature map 的相邻点距离是一个单位)。长宽的放缩范围在 [0,∞]。不能把无约束优化问题直接去套有约束优化问题。所以需要进一步编码。
t
x
=
σ
−
1
(
g
x
−
c
x
)
tx=σ^ {−1}(gx−cx)
tx=σ−1(gx−cx)
t
y
=
σ
−
1
(
g
y
−
c
y
)
ty=σ^ {−1}(gy−cy)
ty=σ−1(gy−cy)
t
w
=
l
o
g
(
g
w
/
p
w
)
tw=log(gw/pw)
tw=log(gw/pw)
t
h
=
l
o
g
(
g
h
/
p
h
)
th=log(gh/ph)
th=log(gh/ph)
最后经过反向的解码就得到了原始论文的样子
 (
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh) 是在最后一层 feature map 上的坐标。为了方便收敛,也为了后一行数据的类别概率,置信度量纲保持一致,我们需要将
(
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh)归一化,方法很简单,计算
(
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh)相对于最后一层 feature map 的相对大小。
(
b
x
/
f
w
,
b
y
/
f
h
,
b
w
/
f
w
,
b
h
/
f
h
)
(bx/fw, by/fh, bw/fw, bh/fh)
(bx/fw,by/fh,bw/fw,bh/fh) ,
(
f
w
,
f
h
)
(fw,fh)
(fw,fh)表示最后一层 feature map 的宽和高。在测试阶段,只需要将这个值乘到原始图像的大小上,就能得到原始的图像上的 predict bounding box 。
(
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh) 是在最后一层 feature map 上的坐标。为了方便收敛,也为了后一行数据的类别概率,置信度量纲保持一致,我们需要将
(
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh)归一化,方法很简单,计算
(
b
x
,
b
y
,
b
w
,
b
h
)
(bx,by,bw,bh)
(bx,by,bw,bh)相对于最后一层 feature map 的相对大小。
(
b
x
/
f
w
,
b
y
/
f
h
,
b
w
/
f
w
,
b
h
/
f
h
)
(bx/fw, by/fh, bw/fw, bh/fh)
(bx/fw,by/fh,bw/fw,bh/fh) ,
(
f
w
,
f
h
)
(fw,fh)
(fw,fh)表示最后一层 feature map 的宽和高。在测试阶段,只需要将这个值乘到原始图像的大小上,就能得到原始的图像上的 predict bounding box 。
YOLOv2的损失函数
YOLOv2损失函数整体和YOLOv1相同,但是,有几个地方需要强调:
1 为了解决
w
,
h
w,h
w,h 的敏感度(检测框大小对损失的影响)的问题。这里采用的是
(
2
−
w
i
∗
h
i
)
(2−wi∗hi)
(2−wi∗hi) 去掉了,在YoloV1 中使用的是
w
i
,
h
i
wi,hi
wi,hi 的根号。
w
i
,
h
i
wi,hi
wi,hi 已经是解码后的值,所以在 [0,1]
之间。
2 类别变量使用 softmax, bbox 的置信域使用 sigmoid(因为编码前的
t
x
tx
tx 等都属于负无穷到正无穷了,编码后控制在了 [0,1] 之间,为了使得量纲一致)。但损失仍然使用均方误差(MSE)。
3 最后一项是去修正没有预测准的框,为了加速收敛。仅在前一万多次迭代的时候使用。
YOLOv2的训练过程
高分辨率预训练:
图像分类的训练样本很多,而标注了边框的用于训练对象检测的样本相比而言就比较少了,因为标注边框的人工成本比较高。所以对象检测模型通常都先用图像分类样本训练卷积层,提取图像特征。但这引出的另一个问题是,图像分类样本的分辨率不是很高。所以YOLO v1使用ImageNet的图像分类样本采用 224×224作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448×448的图像作为输入。但这样切换对模型性能有一定影响。
所以YOLO2在采用 224×224图像进行分类模型预训练后,再采用 448×448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448×448 的分辨率。然后再使用 448×448的检测样本进行训练,缓解了分辨率突然切换造成的影响。
多尺度训练:
由于是全卷积网络,其下采样的倍数是 32 。所以可以支持输入任何的 32 倍数尺寸的图片。于是可以输入不同尺寸的图片进行训练。每10个batch之后,就将图片resize成{320, 352, …, 608}中的一种。
联合训练:
联合训练方法思路简单清晰,Yolov2中物体矩形框生成,不依赖于物理类别预测,二者同时独立进行。当输入是检测数据集时,标注信息有类别、有位置,那么对整个loss函数计算loss,进行反向传播;当输入图片只包含分类信息时,loss函数只计算分类loss,其余部分loss为零。当然,一般的训练策略为,先在检测数据集上训练一定的epoch,待预测框的loss基本稳定后,再联合分类数据集、检测数据集进行交替训练,同时为了分类、检测数据量平衡,作者对coco数据集进行了上采样,使得coco数据总数和 ImageNet 大致相同。
由于 coco 和 Imagenet 数据类别不一致的问题,为了能正常联合训练,作者引入了 wordtree。

YOLOv3
YOLOv3网络结构
 YOLOv3 最大的改进部分是“特征融合”(借鉴FPN网络),采用和YOLOv2同样的ground truth bounding box的编码方式。并采用anchor思想,同时借鉴特征图金字塔的思想,用不同尺度的特征图来检测目标。
YOLOv3 最大的改进部分是“特征融合”(借鉴FPN网络),采用和YOLOv2同样的ground truth bounding box的编码方式。并采用anchor思想,同时借鉴特征图金字塔的思想,用不同尺度的特征图来检测目标。
小尺寸特征图感受野大,于是用来检测大尺寸的物体。
大尺寸特征图感受野小,于是用来检测小尺寸的物体。
YOLOv3共输出三个尺度的特征图,分别是19x19, 38x38, 76x76
YOLOv3同样使用k-means进行聚类作为先验框,(距离仍使用1-IOU)。
以COCO数据集为例,一共聚类得到9个宽度的框,(10x13)(16x30)(33x23)(30x61)(62x45)(59x119)(116x90)(156x198)(373x326)
输出的立方体( 利用YOLOv2中的公式:255 = 3 x(80+4+1)),所以有3类先验框。大的tensor感受野小适合小目标检测,需要小的anchor。小的tensor感受野大适合大目标检测,需要大的anchor。
特征图 19×19,对应(116 × 90), (156 × 198),(373 × 326) anchor。
特征图38×38,对应(30×61),(62×45),(59× 119) anchor。
特征图76×76,对应(10×13),(16×30),(33×23) anchor。
ground truth bounding box的编码方式和解码方式和YOLOv2相同,不同的是类别概率输出使用sigmoid,不是softmax了。这样,一个“负责”区域可以同时输出多个类别。
YOLOV3的损失函数
 总体和YOLOv2一致,不同的是类别和置信度的损失将均差MSE损失函数换成了交叉熵。
总体和YOLOv2一致,不同的是类别和置信度的损失将均差MSE损失函数换成了交叉熵。
YOLOVv3的训练过程
和YOLOv1和YOLOv2的训练过程不同,YOLOv1和YOLOv2是根据ground truth bounding box中心所落的负责区域来确定ground truth bounding box由哪个点负责。而YOLOv3中最后有多个feature map。使用该策略会导致ground truth bounding box同时属于多个点负责。所以需要用用新的方式确定样本由哪个点的区域负责。即 所有预测的predicted bounding box和ground truth bounding box的IOU最大的就是正样本。
创新部分是,将prediceted bounding box分为三类:
正例:产生回归框 loss 和类别置信度 loss。
负例:只产生置信度 loss。
忽略:不产生任何 loss。
正例:
对任意的 ground truth bounding box,与所有的 predicted bounding box 计算IOU,IOU 最大那个就是正例。一个predicted bounding box,只能分配给一个ground truth bounding box。比如第一个 ground truth bounding box 已经匹配了一个正例的 predicted bounding box,那么下一个 ground truth bounding box,需要在剩下的 predicted bounding box 中寻找 IOU 最大的作为正例。
负例:
除正例以外(与 ground truth bounding box 计算后 IOU 最大的检测框,但是IOU小于阈值,仍为正例),与全部 ground truth bounding box 的 IOU 都小于阈值(论文中为 0.5),则为负例。
忽略:
除正例以外,与任意一个 ground truth bounding box 的 IOU 大于阈值(论文中为 0.5),则为忽略。
在 YoloV3 中置信域标签直接设置为 1 和0。而不是 YoloV1 的 IOU 值。原因是假设 iou 是0.8,但学习到的可能只有 0.6 总是会低一些。不如直接将标签设为 1 (学习到的可能就是 0.8)。
YOLOv3的测试过程
由于有三个特征图,所以需要对三个特征图分别进行预测。
三个特征图一共可以出预测 19 × 19 × 3 + 38 × 38 × 3 + 76 × 76 × 3 = 22743 个 pd 坐标以及对应的类别和置信度。
测试时,选取一个置信度阈值,过滤掉低阈值 box,经过 NMS(非极大值抑制),输出整个网络的预测结果。注意最后要还原到原始坐标。该改成测试模式的模块需要改成测试模式(比如 BatchNorm)
YOLOv4
提出了目标检测通用框架套路:backbone, neck, head
backbone:各类卷积网络,目的是对原始图像做初步的特征提取。
neck:各类结构,目的是从结构上做“特征的融合”。主要为解决小目标检测,重叠目标检测等问题。
head:gd 编码,回归和解析。
YOLOv4网络结果
 Mish激活函数
Mish激活函数
 Dropblock:
Dropblock:
对 feature map 的“局部区域”进行丢弃。其实就是 cutout 的推广形式。
 PANET结构:
PANET结构:
 和正常的 PANET 结构的区别:
和正常的 PANET 结构的区别:
 特征图和 anchor 的对应方式和 YoloV3 一致。原则是大的特征图对应小的 anchor,小的特征图对应大的 anchor。
特征图和 anchor 的对应方式和 YoloV3 一致。原则是大的特征图对应小的 anchor,小的特征图对应大的 anchor。
YOLOv4的损失函数
YoloV1-3 都是使用 MSE 进行回归(只是编码方式不同)。作者认为这种损失是不合理的。因为 MSE 的 x , y , w , h x,y,w,h x,y,w,h四者是解耦独立的。但实际上这四者并不独立,应该需要一个损失函数能捕捉到它们之间的相互关系。IOU 能捕捉到他们之间的关系 ( L i o u = 1 − I O U Liou=1−IOU Liou=1−IOU),但 IOU 有很多的问题,后面有陆续的一些推广和改进,最终 YoloV4 选择了 CIOU ,CIOU 是 DIOU 的进一步延伸。
首先看一下 DIOU 对应的损失的公式:
L d i o u = 1 − I O U + ρ 2 ( b , b g t ) / c 2 Ldiou=1−IOU+ρ^2(b,b^{gt})/c^2 Ldiou=1−IOU+ρ2(b,bgt)/c2
b
g
t
b^{gt}
bgt表示 ground truth bounding box 中心点,b 表示 predicted bounding box 中心点,
ρ
2
ρ^2
ρ2 表示欧式距离。c 表示包含两个框的最小矩阵的对角线。
 DIOU 考虑到了
DIOU 考虑到了
两边框交集的面积
两边框中心点距离
但是没有考虑到长宽比。一个好的 predicted bonding box,应该和 ground truth bounding box 的长宽比尽量保持一致。
于是我们有了 CIOU:

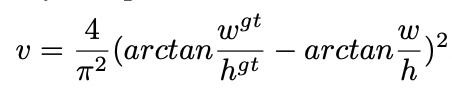
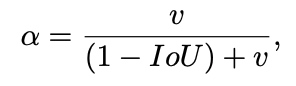

YOLOv4的训练过程
Mosaic数据增强
cmBN
SAT自对抗训练
YOLOv4的测试过程
测试过程重要注意两点:
多个特征图需要检测,但是 78×78的特征图不参与检测。
使用 DIOU_NMS 代替 NMS 。
D
I
O
U
=
I
O
U
−
ρ
2
(
b
,
b
g
t
)
/
c
2
DIOU=IOU−ρ^2(b,b^{gt})/c^2
DIOU=IOU−ρ2(b,bgt)/c2
这里 NMS 不用 CIOU 是合理的。因为只有 ground truth bounding box 和对应的 predicted bounding box 才需要保持 bbox 的长宽比一致。在测试阶段,predicted bounding box 之间并不一定长宽比一致。















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









