






YOLO系列算法
YOLO系列算法是一类典型的one-stage目标检测算法,其利用anthor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好,所以在工业界也十分受欢迎,接下来我们介绍YOLO 系列算法。
Yolo算法思想
在介绍Yolo算法之前,我们回忆下RCNN模型,RCNN模型提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右,然后对每个候选区进行对象识别,但处理速度较慢。
Yolo意思是You Only Look Once,它并没有真正的去掉候选区域,而是创造性的将候选区和目标分类合二为一,看一眼图片就能知道有哪些对象以及它们的位置。
Yolo模型采用预定义预测区域的方法来完成目标检测,具体而言是将原始图像划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。我们将其理解为98个预测区,很粗略的覆盖了图片的整个区域,就在这98个预测区中进行目标检测。
只要得到这98个区域的目标分类和回归结果,再进行NMS就可以得到最终的目标检测结果。那具体要怎样实现呢?
Yolo的网络结构
YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接,从网络结构上看,与前面介绍的CNN分类网络没有本质的区别,最大的差异是输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示: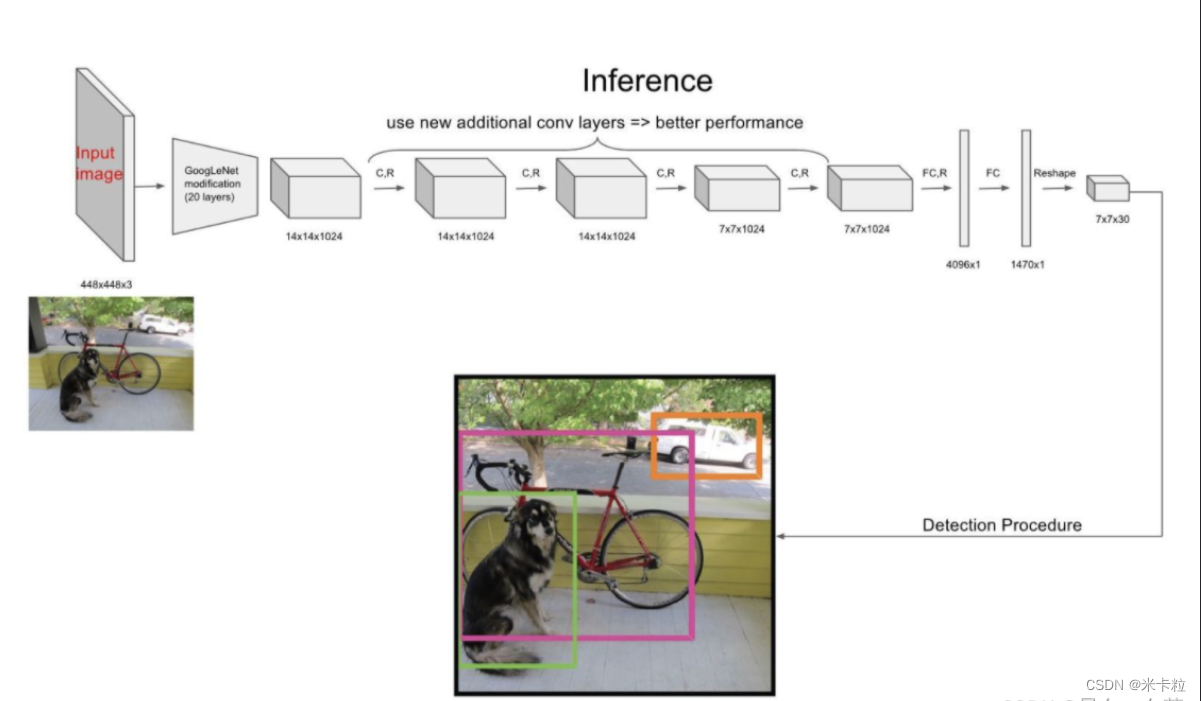
网络结构比较简单,重点是我们要理解网络输入与输出之间的关系。
网络输入
网络的输入是原始图像,唯一的要求是缩放到448x448的大小。主要是因为Yolo的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以Yolo的输入图像的大小固定为448x448。
网络输出
网络的输出就是一个7x7x30 的张量(tensor)。那这个输出结果我们要怎么理解那?
7X7网格
根据YOLO的设计,输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。如下图所示,比如输入图像左上角的网格对应到输出张量中左上角的向量。
30维向量
30维的向量包含:2个bbox的位置和置信度以及该网格属于20个类别的概率
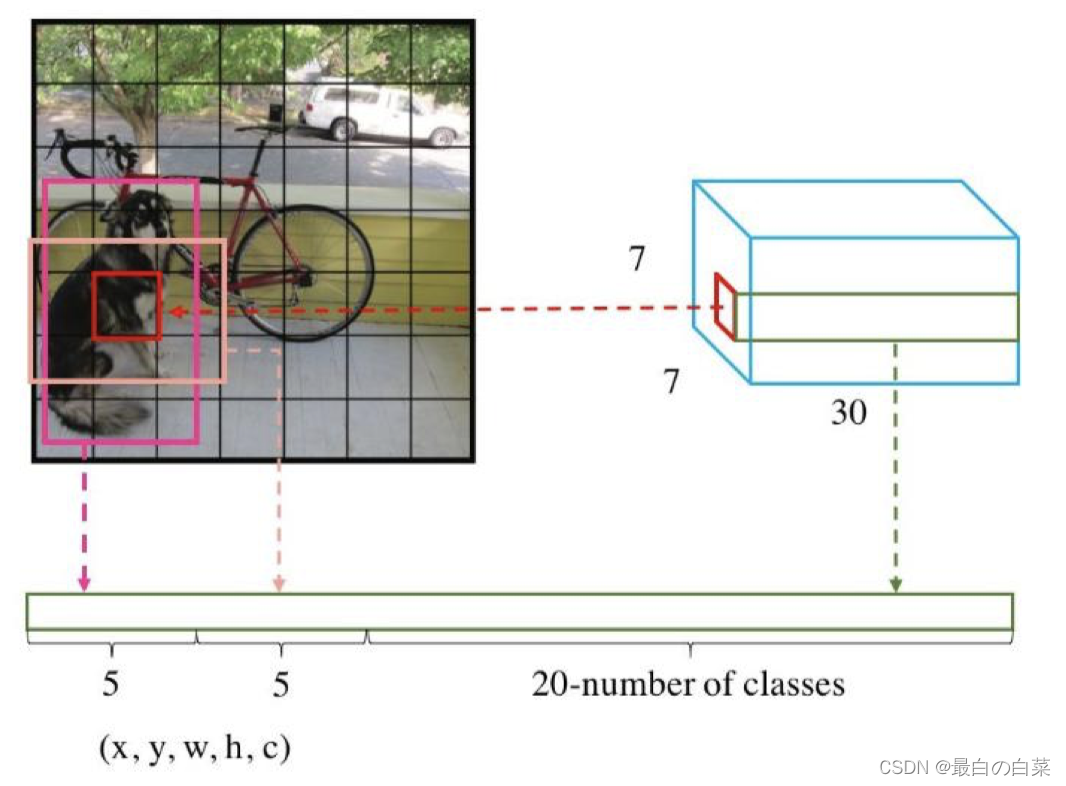
- 2个bounding box的位置 每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
- 2个bounding box的置信度 bounding box的置信度 = 该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU,用公式表示就是:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yCA8yb7G-1646276606894)(笔记图片/image-20200915153543735.png)]](https://img-blog.csdnimg.cn/4191517e545d45fd8dbf09eee9ae54fc.png)
- Pr(Object)是bounding box内存在对象的概率
- 20个对象分类的概率
Yolo支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率.
Yolo模型的训练
在进行模型训练时,我们需要构造训练样本和设计损失函数,才能利用梯度下降对网络进行训练。
训练样本的构建
将一幅图片输入到yolo模型中,对应的输出是一个7x7x30张量,构建标签label时对于原图像中的每一个网格grid都需要构建一个30维的向量。对照下图我们来构建目标向量:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dRlyHzQJ-1646276606895)(笔记图片/image-20200915155204485.png)]](https://img-blog.csdnimg.cn/62951fdd999942f5931b559b1bd63354.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyA55m944Gu55m96I-c,size_15,color_FFFFFF,t_70,g_se,x_16)
- 20个对象分类的概率
对于输入图像中的每个对象,先找到其中心点。比如上图中自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写
- 2个bounding box的位置
训练样本的bbox位置应该填写对象真实的位置bbox,但一个对象对应了2个bounding box,该填哪一个呢?需要根据网络输出的bbox与对象实际bbox的IOU来选择,所以要在训练过程中动态决定到底填哪一个bbox。
- 2个bounding box的置信度
预测置信度的公式为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2TgxHUzV-1646276606896)(笔记图片/image-20200915155812745.png)]](https://img-blog.csdnimg.cn/f76c68b50ccf4deeb753811090b34f54.png)
IOUpredtruth利用网络输出的2个bounding box与对象真实bounding box计算出来。然后看这2个bounding box的IOU,哪个比较大,就由哪个bounding box来负责预测该对象是否存在,即该bounding box的置信度目标值为1,同时对象真实bounding box的位置也就填入该bounding box。另一个不负责预测的bounding box的置信度目标值为0。















 5132
5132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









