







基本流程
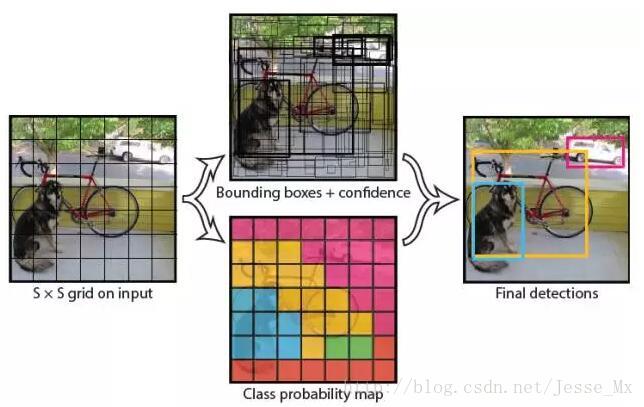
(1) 给个一个输入图像,首先将图像划分成7 * 7(S=7)的网格。
(2) 对于每个网格,每个网格预测2个bouding box(每个box包含5个预测量,这5个预测量为x,y,w,h,confidence)以及20个类别概率。
(3) 根据上一步可以预测出7 * 7 * 2 = 98个目标窗口,然后根据阈值去除可能性比较低的目标窗口,再由NMS去除冗余窗口即可。
YOLOv1使用了end-to-end的回归方法,没有region proposal步骤,直接回归便完成了位置和类别的判定。种种原因使得YOLOv1在目标定位上不那么精准,直接导致YOLO的检测精度并不是很高。
问答解析:
1、对于每一个预测的bounding box,具体说说5个参数?
:是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1];
:该box的长和宽相对于input的长和宽(448)的比例,被归一化到[0,1]
根据这4个元素可还原出原图的一个bbox。假设原图的长宽为448,那么bbox的宽高为:
![]()
假设grid cell左上角坐标为(x0,y0),则bounding box左上角的坐标为:

- 此外还有一个confidence参数,表达式如下:
![]()
其中表示物体位置的准确性,是bbox与gt的重叠度。
表示是否包含物体,当bbox包含物体,则
,否则等于0。也就是说confidence要么为0,表示此bbox中不包含对象,要么不为0,表示该bbox和ground truth的IOU。
2、网络最终输出维度是多少,怎么排列的?
输出的维度为7×7×(5×2+20) = 7×7×20 (20个类别),排列方式如下:

3、一个grid cell预测量两个bbox,那么每一个bbox还应该对应一个分类的confidence不是吗?
实际上yolo的原理是对于一个grid cell只预测一个类别,即虽然每个格子可以预测2个bounding box,但是最终只选择IOU最高的bounding box作为该类别检测输出,即每个格子最多只预测出一个物体一个类别。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
你可以这么理解,yolo现针对每一个grid cell只预测一类,然后将IOU最高的bbox与这一类相连接。
4、如何预测?
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
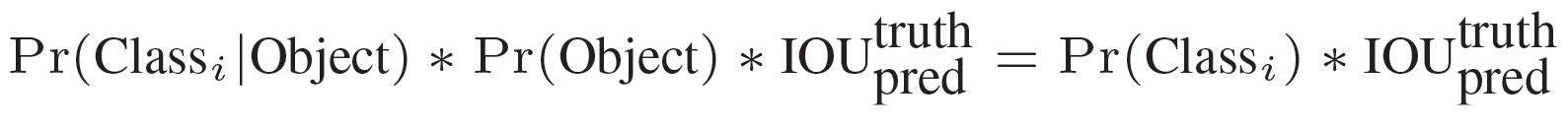
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
损失函数

看起来很复杂,实际上可以分为:
- 有物体中心落入的cell,需要计算分类损失,没有物体落入的cell就不用计算类别损失,即上面公式中的第4个框,类别预测。
- 两个bbox都要计算置信度损失,即上面公式中的第2,3个框。
- 其中上述两个bbox中,与groud truth IOU较大的那个bbox需要计算位置损失,即上面公式中的第1个框。
上面w,h开根号的原因是小目标对于预测wh的误差更敏感,用开根的方法缓解。举例来说,大小为10和大小为100的目标,预测大小分别为20和110,如果不用开根号的话,两者的损失都为10²,但是显然小目标检测的更差一些,开根后,
![]()
相当于强化了小目标的wh的损失。















 2357
2357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









