







 文章讲述了使用k-Means算法对MNIST数据集进行手写数字图像聚类的实验过程,包括实验目的、问题探讨、模型建立、性能分析以及算法的优缺点和优化策略。结果显示,聚类正确率受初始聚类中心和样本数量影响,且时间复杂度与参数有关。
文章讲述了使用k-Means算法对MNIST数据集进行手写数字图像聚类的实验过程,包括实验目的、问题探讨、模型建立、性能分析以及算法的优缺点和优化策略。结果显示,聚类正确率受初始聚类中心和样本数量影响,且时间复杂度与参数有关。
一、 实验目的与要求
1.熟练掌握k-Means方法对手写数字图像进行分类;
2.用Matlab编写代码,熟悉其画图工具,进行实验,并验证结果;
3.锻炼数学描述能力,提高报告的叙述能力。
二、 问题
手写数字图像数据分类问题:文件train_images.mat包含大小为28×28的手写数字图像,共60000张;文件train_labels.mat是其对应的数字标签。文件数据的具体读写和数据格式,请参考附件DataRead.m文件。实验要求对手写数字图像进行聚类,并讨论其性能:
(MNIST DATABASE下载网址: http://yann.lecun.com/exdb/mnist/)
(1) 对train_images.mat的前100张手写数字图像进行聚类,共10类;
(2) 对train_images.mat的前1000张手写数字图像进行聚类,共10类;
(3) 根据实际情况,讨论k-Means能对多少张手写图像进行聚类,性能如何?
三、模型建立及求解
1.解决问题思路
实验使用Matlab实现使用K-means算法对MNIST数据集聚类并进行分析。
2.模型建立
2.1聚类
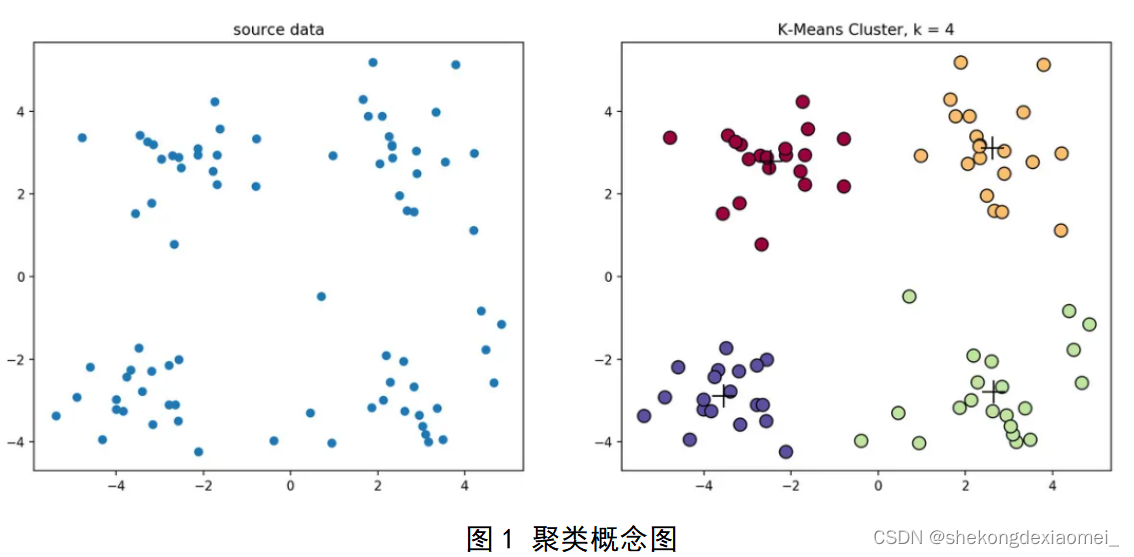
将物理或抽象对象的集合分成由类似特征组成的多个类的过程称为聚类。
给定N个n维向量x_1,…,x_N∈R^n,目标:分成k个集合,尽量使得同一个集合中的向量彼此接近。
2.2 k-means聚类
聚类问题从本质上来说是将包含若干元素的集合按某一准则划分成若干个互不相交的集合的并集,该准则常常用一个函数来定义,称为目标函数。我们优化(聚类)的目标往往是极大化或者极小化该目标函数。我们将它进行数学表述:
给定一个集合:

K-means是一种无监督的学习,是将N个向量xi∈R^n划分成k类的迭代聚类算法,主要通过不断地取离种子点(质心)最近均值的数据,自动将相似的对象归到同一个簇中(共聚类k个簇),循环往复执行,直到满足聚类的收敛条件为止。常用于聚类分析。
| 步骤 | 操作 |
| 1 | 在N个点中随机选取k个点,分别作为聚类中心 |
| 2 | 计算每个点到k个聚类中心的距离,并将其分配到最近的聚类中心所在的聚类中 |
| 3 | 重新计算每个聚类现在的质心,并以其作为新的聚类中心 |
| 4 | 重复步骤2、3,直到所有聚类中心不再变化 |
K-means中所用最重要方法即求点群中心的算法:欧氏距离
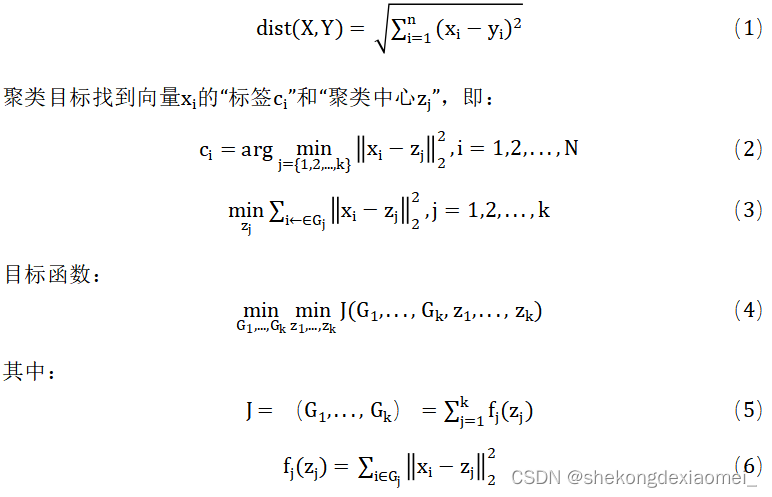
3.算法证明
(1)对于任意给定的迭代聚类中心初值k-means算法的目标函数一定会收敛。
Pr:


4.存在问题
在每一次迭代中目标函数J都会下降,直到聚类中和划分聚类标签集合不再变化。但是k-means算法依赖于初始随机生成的聚类中心,只可得到目标函数J的局部最优。
故可以采用以下几种方法:
①使用不同的(随机的)初始聚类中心运行k-means算法若干次,取目标函数J值最小的一次作为最终的聚类结果。
②择批次距离尽可能远的k个点。
5.求解与性能分析
正确率计算:
手写数字数据集MNIST为带标签数据集,本实验标签在train_labels中。但由于K-means为无监督算法,并不能匹配相应的标签,所以需要人为计算聚类正确率。计算方法核心为:利用mode函数统计聚类中每类出现的最多的标签数作为该类预测标签,并计算正确率(正确率=正确数/总数)。
5.1对train_images.mat的前100张手写数字图像进行聚类,共10类;
5.1.1普通k-means
随机一次聚类中心初始化,然后按照表一的算法步骤进行实现,得出的正确率和其初始类聚心的选择对照表为下表所示:
| 第n次实验 | 初始聚类中心 | K-means正确率 |
| 1 | 42-72-1-30-15-9-18-33-37-50 | 59% |
| 2 | 44-3-54-43-41-32-20-58-28-25 | 61% |
| 3 | 56-71-29-50-86-96-12-20-5-41 | 62% |
由几次运行测试可以看出,k-means聚类可以有效的进行聚类识别,但是正确率因为初始聚类中心的选择不同而不同。
5.1.2 随机初始聚心若干次选择最优情况
现在将4.1.1的操作重复8遍,并选出目标函数J的值最小的作为最终的聚类结果。测试结果如下:
| 第n次循环 | 初始聚类中心 | 正确率 | 目标函数J |
| 1 | 97-55-96-70-67-21-92-1-24-40 | 58% | 141228.5 |
| 2 | 23-87-21-90-47-59-72-49-28-18 | 53% | 143631.5 |
| 3 | 90-33-81-5-11-57-50-39-31-95 | 53% | 141631.5 |
| 4 | 8-78-43-71-94-52-48-7-25-46 | 51% | 144737.4 |
| 5 | 88-96-86-52-23-2-41-38-49-44 | 56% | 144167.1 |
| 6 | 56-71-29-50-86-96-12-20-5-41 | 62% | 140539.3 |
| 7 | 44-3-54-43-41-32-20-58-28-25 | 61% | 141297.7 |
| 8 | 42-72-1-30-15-9-18-33-37-50 | 59% | 141403.7 |
则最终结果:
| 第n次循环 | 初始聚类中心 | 正确率 | 目标函数J |
| 6 | 56-71-29-50-86-96-12-20-5-41 | 62% | 140539.3 |
第六次运行的时候,取初始聚类中心为:56-71-29-50-86-96-12-20-5-41是最佳情况,此时正确率达到62%,相比于只运行一次效果明显要好。但是这不是最佳情况,我们只是方便观察所以选择了循环次数为8。
由结果可以看出代码有效的对初始聚心进行了随机选择。下一步,我们将测试次数设置为100,以探求其规律。
5.1.3 随机初始聚心100次选择最优情况
随机选择初始聚类中心,然后按照表一的算法步骤进行实现,执行操作100次,得出的正确率为下表所示
由图表中的可视化信息可以看出,在这100次测试中,聚类的平均正确率为58.58%。
最高达到72%,最低为44%,方差为0.0022,每次聚类的平均时间为0.023s。
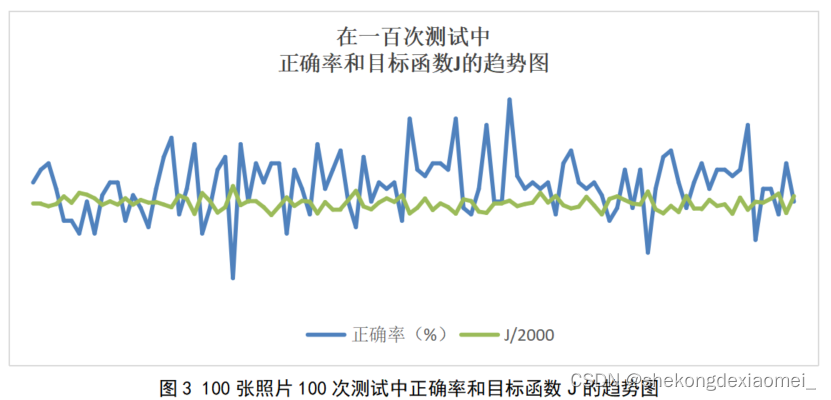
由图表可以看出目标函数和正确率的关系,当目标函数越小时正确率越高。
5.1.4 选择距离尽可能远的k个点作为聚心
在前面的实验中我们知道了初始聚心的选取会对结果造成很大的影响,为了更加直观的看出其影响,或者优化k-means算法,我们现在手动选择聚类类心。观察train_images.mat文件中的手写照片,选择每个数字第一次的图片位置,并将其作为初始聚类类心进行k-means聚类,故选择train_images.mat文件中第1,2,3,4,5,6,8,14,17,18张图片作为初始聚类中心。(k=10,m=100)测试结果为:正确率68%,虽然正确率相比大量随机选取初始聚类类心进行目标函数比较得出的结果正确率相比不算特比好,但是这种方法的效率很高,运行时间只要0.003s。
| 初始聚类类心 | 正确率 | 运行时间 |
| 1-2-3-4-5-6-8-14-17-18 | 68% | 0.003s |
5.2对train_images.mat的前1000张手写数字图像进行聚类,共10类;
参数:k=10,run_time=100
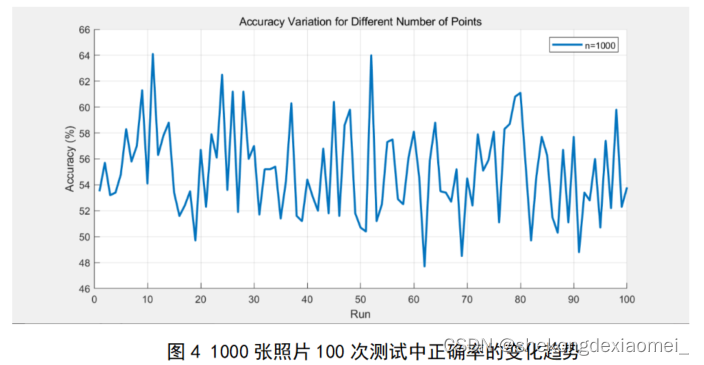
在这100次测试中,聚类结果的平均正确率为55.034%。正确率最高达到64%,最低为48%,运算时间为5503.4 s。
通过对100张照片与1000张照片进行k-means聚类(k=10,run_time=100)的效果比较,可以看出随着样本数增大,聚类效果有降低或波动趋势,且时长增加。
6.讨论k-Means能对多少张手写图像进行聚类
k个聚类中心,m个数据,计算两数据之间二范数的复杂度为0(d),则聚类一次的时间复杂度为0(kmd)。对于dim*dim像素的灰度图像,两数据间的欧氏距离的复杂度为3*dim*dim所以时间复杂度可以写为O(3*dim*dim*km)。重新确定聚类中心所需的时间复杂度为O(dim*dim*m)。
则k-Meams 的时间复杂度则为0(dim*dim*km)。
在本次实验中:k=10,dim=28
| 照片数量m | 100次运行时间(s) | 正确率max(%) | 正确率min(%) | 正确率平均值(%) |
| 1000 | 5503.4 | 64 | 48 | 55 |
| 3000 | 5854.8 | 63.7 | 50.8 | 58.5 |
| 5000 | 5719.4 | 62.1 | 48.5 | 57.2 |
| 7000 | 5720.5 | 62.8 | 49.4 | 57.2 |
| 9000 | 5636.4 | 61.7 | 49.8 | 56.4 |
| 11000 | 5801.4 | 62.9 | 51.8 | 58 |
| 13000 | 5838.2 | 64.9 | 51.4 | 58.4 |
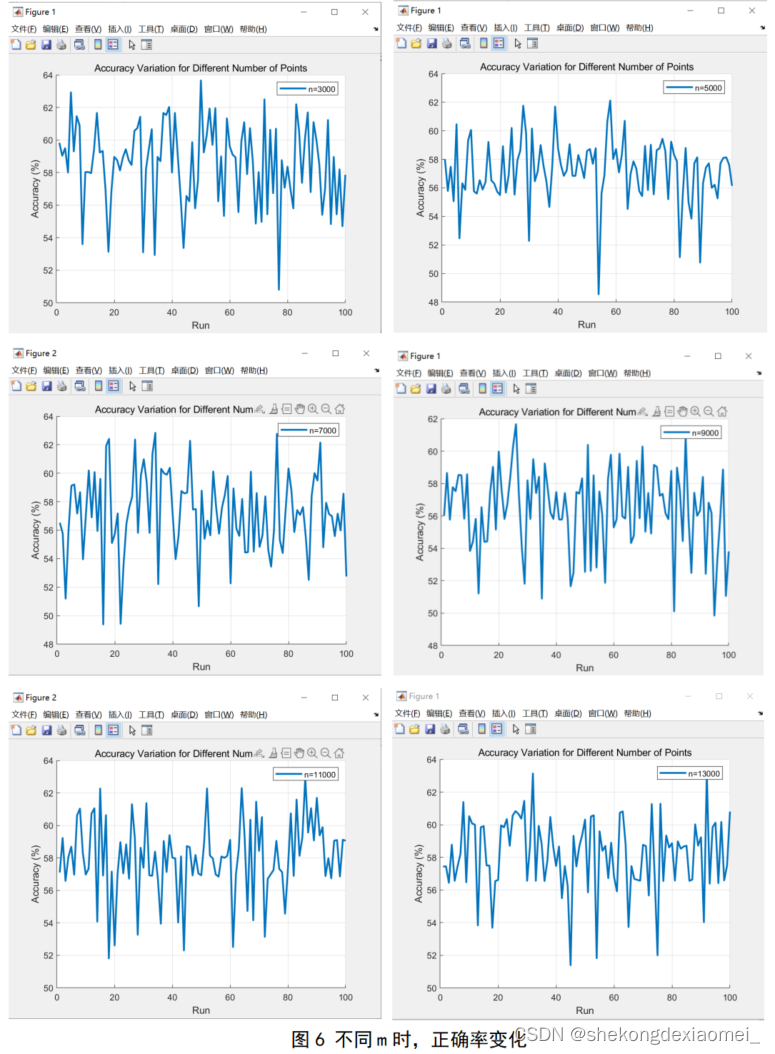
由上面图表分析得:随着样本数量的增加,K-means对MNIST的聚类正确率有一定波动,但基本维持在55~65%,运行时间变化不大,但仍有稍微的增大趋势,根据时间复杂度分析,其时间复杂度为0(dim*dim*km),其中dim=28,k=10,m=60000,且在本次实验中聚类样本数对实验没有限制,K-means可以完成MNIST完整数据集(60000张图片)的聚类。
7.性能分析
当改变k值时,测试算法的效率,结果如下:
表7 m=1000,k取不同值时的运行结果
| k | 正确率最大值(%) | 正确率最小值(%) | 正确率平均值(%) | 运行时间(s) |
| 10 | 64 | 48 | 55.0 | 5503.4 |
| 15 | 70.2 | 56.2 | 64.0 | 6404.2 |
| 20 | 73.8 | 63.4 | 68.9 | 6888.4 |
| 25 | 77.6 | 65.6 | 71.8 | 7183.6 |
| 30 | 78.1 | 68.8 | 73.6 | 7359.8 |
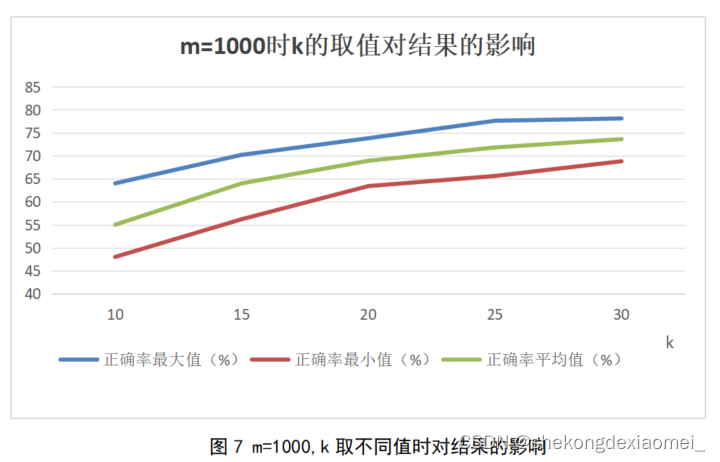
由表7和图8我们可以看出k越大,算法正确率越高,运行时间随着k的增大而增大。
8.优缺点分析
优点:
1.简单且高效,适用于大规模数据集。
2.可解释性强,每个样本都属于最近的簇中心。
3.k-means算法可以扩展到高维数据集,并且可以处理大量特征。
缺点:
1.k-means算法需要预先指定簇的个数k,但在实际应用中,我们可能无法确定最优的簇个数,这可能导致结果不理想。
2.k-means算法的结果受初始簇中心的选择影响较大,不同的初始值可能导致不同的聚类结果。
3.k-means算法对异常值敏感,一个异常值可能会导致整个簇的偏移。
4.仅适用于凸形状簇,对于非凸形状的簇,聚类效果可能不佳。
5.k-means算法基于欧氏距离进行聚类,对于非线性分布的数据,聚类效果可能不好。
9. 算法优化
9.1增加k的取值
由本实验中关于对k取值对算法结果和效率影响研究可以发现,当k值越大,算法正确率越高,但是算法的时间代价会增加。
9.2二分K-Means 算法
为了解决 K-Means 算法对初始簇心比较敏感的问题,二分K-Means 算法是一种弱化初始质心的一种算法,二分K均值不太受初始化问题的影响。
其划分策略为对所有簇计算误差和 SSE,选择SSE最大或误差最小的聚簇进行划分操作。
| 步骤 | 操作 |
| 1 | 将所有样本数据作为一个簇放到一个队列中 |
| 2 | 从队列中选择一个簇进行K-means算法划分,划分为两个子簇,并将子簇添加到队列中。 |
| 3 | 循环迭代第2步操作,直到中止条件达到(聚簇数量、最小平方误差、迭代次数等) |
该算法的局限性是:当簇具有非球形形状或具有不同尺寸或密度时,二分K-Means 很难检测到“自然的”簇。
9.3 k-means++
kmeans++算法的核心思想是:在选择初始聚类中心时,尽量让聚类中心之间的距离较大,这样可以避免出现空聚类或者聚类中心过于接近的情况。
| 步骤 | 操作 |
| 1 | 从数据集中随机选择一个点作为第一个聚类中心。 |
| 2 | 对于数据集中的每个点,计算它到已选聚类中心的最近邻距离,并将这些距离存入一个数组D。 |
| 3 | 从数据集中以概率正比于D中对应元素的平方选择一个点作为下一个聚类中心。 |
| 4 | 重复步骤2和3,直到选择出k个聚类中心。 |
| 5 | 使用kmeans算法,以选出的k个聚类中心为初始值,进行聚类。 |
三种优化算法都展现了其优势,其中k_means++的效果最明显。
四、小结(可含个人心得体会)
在本次实验中我通过MATLAB来实现k-means算法,同时探究了k-means算法在不同规模以及不同初始情况下的效果。根据对不同聚类样本数和聚类中心数进行测试和对比,从而分析算法的性能,最后还扩展实现了优化算法对聚类结果的效果对比。
随着聚类样本数的增加(m = 100,1000,3000,5000,7000,9000,11000),聚类的平均正确率并没有显著差异。这可能是因为随着聚类样本数的增加,在10个聚类中心的前提下,随着带来的错误匹配概率也增加,因此聚类样本数增加并不意味着聚类结果正确率更高。
随着聚类中心数的增加(k=10,15),聚类的平均正确率有明显提高,且迭代次数降低,收敛变快,这可能是因为聚类中心数的增加提高了程序可容错性,不过也导致了平均聚类时间有一些增加。
















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









