







In 1953, David A. Huffman published his paper "A Method for the Construction of Minimum-Redundancy Codes", and hence printed his name in the history of computer science. As a professor who gives the final exam problem on Huffman codes, I am encountering a big problem: the Huffman codes are NOT unique. For example, given a string "aaaxuaxz", we can observe that the frequencies of the characters 'a', 'x', 'u' and 'z' are 4, 2, 1 and 1, respectively. We may either encode the symbols as {'a'=0, 'x'=10, 'u'=110, 'z'=111}, or in another way as {'a'=1, 'x'=01, 'u'=001, 'z'=000}, both compress the string into 14 bits. Another set of code can be given as {'a'=0, 'x'=11, 'u'=100, 'z'=101}, but {'a'=0, 'x'=01, 'u'=011, 'z'=001} is NOT correct since "aaaxuaxz" and "aazuaxax" can both be decoded from the code 00001011001001. The students are submitting all kinds of codes, and I need a computer program to help me determine which ones are correct and which ones are not.
Input Specification:
Each input file contains one test case. For each case, the first line gives an integer N (2≤N≤63), then followed by a line that contains all the Ndistinct characters and their frequencies in the following format:
c[1] f[1] c[2] f[2] ... c[N] f[N]
where c[i] is a character chosen from {'0' - '9', 'a' - 'z', 'A' - 'Z', '_'}, and f[i] is the frequency of c[i] and is an integer no more than 1000. The next line gives a positive integer M (≤1000), then followed by M student submissions. Each student submission consists of N lines, each in the format:
c[i] code[i]
where c[i] is the i-th character and code[i] is an non-empty string of no more than 63 '0's and '1's.
Output Specification:
For each test case, print in each line either "Yes" if the student's submission is correct, or "No" if not.
Note: The optimal solution is not necessarily generated by Huffman algorithm. Any prefix code with code length being optimal is considered correct.
Sample Input:
7
A 1 B 1 C 1 D 3 E 3 F 6 G 6
4
A 00000
B 00001
C 0001
D 001
E 01
F 10
G 11
A 01010
B 01011
C 0100
D 011
E 10
F 11
G 00
A 000
B 001
C 010
D 011
E 100
F 101
G 110
A 00000
B 00001
C 0001
D 001
E 00
F 10
G 11
Sample Output:
Yes
Yes
No
No#include<iostream>
#define MAXSIZE 64
using namespace std;
struct TreeNode{//Huffman二叉树
int weight=0;
TreeNode * lchild=NULL;
TreeNode * rchild=NULL;
};
struct FlagNode{//前缀码二叉树
int flag=0;//0表示未访问过,1表示访问过
FlagNode * lchild=NULL;
FlagNode * rchild=NULL;
};
struct Heap{//堆
TreeNode data[MAXSIZE];//二叉节点数组
int size=0;
};
void Insert(Heap * H,TreeNode * T){
int i;
for(i=++(H->size);T->weight < H->data[i/2].weight;i=i/2) H->data[i]=H->data[i/2];//若失衡(使之不是小根堆),则从下往上覆盖,注意,H->size必须要自增后再赋给i
H->data[i]= * T; //为何不是T?不能,因为T是指针,*T才是节点
}
Heap * ReadInsert(int n,Heap * H,int a[]){
char c='\0';//字母,不能"\0"
int w=0;//字母的权重
for(int i=0;i<n;i++){
cin>>c>>w;
a[i]=w;
TreeNode * T=new TreeNode;
T->weight=w;
Insert(H,T);
}
return H;
}
TreeNode * DeleteMin(Heap * H){
TreeNode * min=new TreeNode; * min=H->data[1];//本来是TreeNode xx=H->data[yy];但是因为最终要返回指针,所以..
TreeNode last=H->data[(H->size)--];//size--非常重要,注意
int parent,child;//下标
//寻找删除结点前堆中最后一个结点在新堆中的插入位置
for(parent=1;parent<=(H->size)/2;parent=child){
child=parent*2;
if((child!=H->size) && (H->data[child].weight > H->data[child+1].weight)) child++;
if(last.weight <= (H->data[child].weight)) break;
else H->data[parent] = H->data[child];//往上覆盖
}
H->data[parent]=last;
return min;
}
//核心是针对原有堆,进行“删2个,插1个”操作n1-1次,即H->size-2次
TreeNode * Huffman(Heap * H){
TreeNode * T;
int n=H->size;
for(int i=0;i<n-1;i++){//循环判断不能写成i<H->size,因为H->size不断在变
T=new TreeNode;
T->lchild=DeleteMin(H);
T->rchild=DeleteMin(H);
T->weight=(T->lchild->weight) + (T->rchild->weight);
Insert(H,T);
//
/*for(int j=1;j<=H->size;j++){
cout<<H->data[j].weight<<" ";
}
cout<<endl;*/
//
}
T=DeleteMin(H);
return T;
}
int WPL(TreeNode * T,int depth){
if(!(T->lchild) && !(T->rchild)) return depth*(T->weight); //叶子
else return WPL(T->lchild,depth+1)+WPL(T->rchild,depth+1);
}
bool Judge(string s,FlagNode * f){//根据A~G构建FlagNode二叉树
for(int i=0;i<s.length();i++){
if(s[i]=='0'){
if(!(f->lchild)){
FlagNode * lf=new FlagNode;
f->lchild=lf;
}else{
if(f->lchild->flag==1) return false;
}
f=f->lchild;
}else{
if(!(f->rchild)){
FlagNode * rf=new FlagNode;
f->rchild=rf;
}else{
if(f->rchild->flag==1) return false;
}
f=f->rchild;
}
}
f->flag=1;
if(!(f->lchild) && !(f->rchild)){//必须是编码最后一定走到叶子节点
return true;
}else{
return false;
}
}
int main(){
//freopen("input.txt","r",stdin);
//1创建一个堆
int n1;cin>>n1;
Heap * H= new Heap;//=(Heap *)sizeof(n1*Heap);
H->data[0].weight=-1;//下标为0的节点不用,设置为岗哨
//2读入各个节点的权值,并插入小根堆
int a[MAXSIZE];
H=ReadInsert(n1,H,a);
TreeNode * T=Huffman(H);//构建Huffman树,返回 最终合成的二叉树
int len=WPL(T,0);
//cout<<"len="<<len<<" ";
char c='\0';//不能是"\0"
string s="\0";//必须是是"\0"
int n2; cin>>n2;
bool result=false;
for(int i=0;i<n2;i++){
bool flag=true;//true表示到目前为止,都满足“非前缀码”(任一编码都不是是其他编码的前缀)
int count=0;
FlagNode * f=new FlagNode;
for(int j=0;j<n1;j++){
cin>>c>>s;
count+=s.length()*a[j];
if(flag){//目前为止,都满足“非前缀码”
result=Judge(s,f);//注意:这里指针f是按值传递,Judge不改变mian里面的指针f,每次f都指向最开始的地方
if(!result) flag=false;//该编码不满足 “非前缀码”
}
}
delete(f);
if((count==len) && result) cout<<"Yes"<<endl; //改成flag可以吗?可以,一样的效果
else cout<<"No"<<endl;
}
return 0;
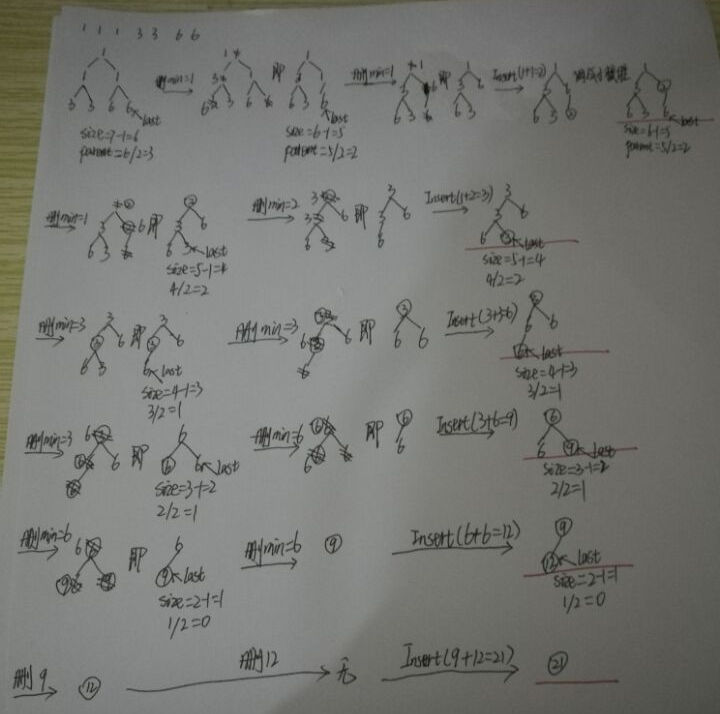
}如果把Huffman里每次删2插1后,打印下节点,效果如下
















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









