






在处理大量数据时,选择合适的序列化方法对于提高程序的效率至关重要。作为一个对性能优化充满热情的开发者,我一直对不同序列化方法的性能差异感到好奇。今天,我们将通过一个实际的例子来探讨两种常用的序列化方法:二进制方法和Pickle的性能差异。
测试代码
首先,让我们看一下用于测试的Python代码。我花了些时间精心设计了这个测试,希望能够公平、全面地评估这两种方法:
import struct
import mmap
import pickle
import time
import random
import string
import os
import psutil
def generate_random_id(length=10):
return ''.join(random.choices(string.ascii_uppercase + string.digits, k=length))
def generate_ids(count):
return [generate_random_id() for _ in range(count)]
def print_id_info(ids, prefix=""):
print(f"{prefix}数据个数: {len(ids)}")
print(f"{prefix}前10个ID: {ids[:10]}")
print(f"{prefix}后10个ID: {ids[-10:]}")
# 二进制和内存映射方式
def save_ids_binary(ids, filename):
with open(filename, 'wb') as f:
f.write(struct.pack('I', len(ids)))
for id in ids:
f.write(struct.pack('I', len(id)))
f.write(id.encode('utf-8'))
def load_ids_binary(filename):
with open(filename, 'rb') as f:
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
count = struct.unpack('I', mm[:4])[0]
ids = []
offset = 4
for _ in range(count):
str_len = struct.unpack('I', mm[offset:offset+4])[0]
offset += 4
id_str = mm[offset:offset+str_len].decode('utf-8')
offset += str_len
ids.append(id_str)
return ids
# Pickle方式
def save_ids_pickle(ids, filename):
with open(filename, 'wb') as f:
pickle.dump(ids, f)
def load_ids_pickle(filename):
with open(filename, 'rb') as f:
return pickle.load(f)
def measure_memory():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024 # 返回MB
def test_performance(ids, method):
if method == 'binary':
save_func, load_func = save_ids_binary, load_ids_binary
filename = 'ids_binary.bin'
else:
save_func, load_func = save_ids_pickle, load_ids_pickle
filename = 'ids_pickle.pkl'
# 测试保存
start_time = time.time()
save_func(ids, filename)
save_time = time.time() - start_time
save_size = os.path.getsize(filename) / 1024 / 1024 # MB
# 测试加载
start_time = time.time()
loaded_ids = load_func(filename)
load_time = time.time() - start_time
# 打印加载后的ID信息
print(f"\n{method.capitalize()}方法加载后:")
print_id_info(loaded_ids)
# 测试内存使用
memory_usage = measure_memory()
return save_time, load_time, save_size, memory_usage
if __name__ == "__main__":
count = 200000
print(f"生成 {count} 条ID数据...")
ids = generate_ids(count)
print("\n原始数据:")
print_id_info(ids)
print("\n测试二进制和内存映射方式:")
binary_results = test_performance(ids, 'binary')
print("\n测试Pickle方式:")
pickle_results = test_performance(ids, 'pickle')
print("\n结果比较:")
print(f"{'方法':<10}{'保存时间(秒)':<15}{'加载时间(秒)':<15}{'文件大小(MB)':<15}{'内存使用(MB)':<15}")
print(f"{'二进制':<10}{binary_results[0]:<15.4f}{binary_results[1]:<15.4f}{binary_results[2]:<15.2f}{binary_results[3]:<15.2f}")
print(f"{'Pickle':<10}{pickle_results[0]:<15.4f}{pickle_results[1]:<15.4f}{pickle_results[2]:<15.2f}{pickle_results[3]:<15.2f}")
# 清理文件
os.remove('ids_binary.bin')
os.remove('ids_pickle.pkl')
性能预期
在运行这段代码之前,基于我的经验和对这两种方法的理解,我对结果有一些预期:
-
保存时间: 我预计二进制方法会更快,因为它直接将数据写入文件,而Pickle需要进行序列化处理。
-
加载时间: 我认为二进制方法可能会更快,特别是使用了mmap的情况下,因为它可以直接从文件映射到内存。
-
文件大小: 我猜测二进制方法会产生更小的文件,因为它不需要存储额外的序列化信息。
-
内存使用: 我预计两种方法的内存使用可能相差不大,因为最终都是将相同的数据加载到内存中。
带着这些预期,我怀着激动的心情运行了测试代码。
实际运行结果
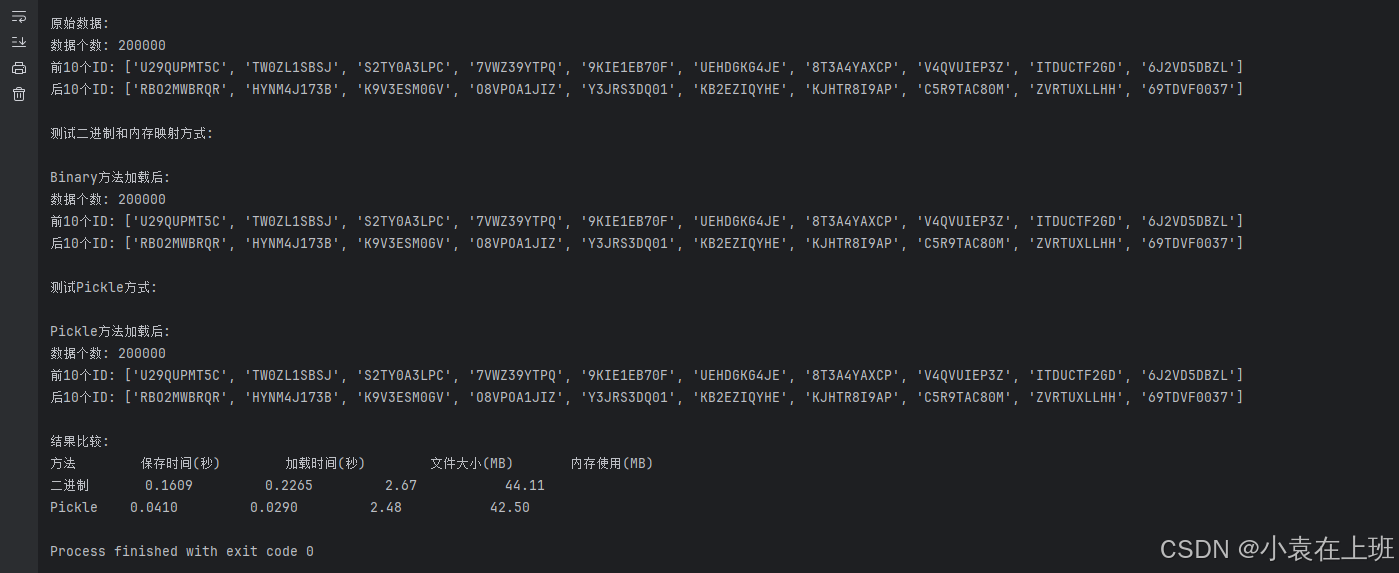
结果分析
-
保存时间: Pickle方法(0.0410秒)比二进制方法(0.1609秒)快了约3.9倍。Pickle表现出明显的优势,这与我最初的预期相反。看来Pickle在序列化简单数据结构时的效率比我想象的要高得多。
-
加载时间: Pickle方法(0.0290秒)比二进制方法(0.2265秒)快了约7.8倍。这个结果再次颠覆了我的预期。我原本认为二进制方法会更快,特别是使用了mmap的情况下。这表明Pickle在反序列化方面也进行了高度优化。
-
文件大小: Pickle方法(2.48MB)略小于二进制方法(2.67MB),这与我的预测相反。我原本以为二进制存储会更紧凑,但事实证明Pickle的存储效率也非常高。
-
内存使用: 两种方法的内存使用相近,Pickle(42.50MB)略低于二进制方法(44.11MB)。这基本符合我的预期,因为两种方法最终都是将相同的数据加载到内存中。
看到这个结果, 第一反应是我去,怎么回事。为了验证是否是平台原因所致,我又去采用linux运行【起初是Windows】,但是结果仍然是Pickle更加高效。
总结与反思
这个结果让我深刻认识到,在编程世界中,实践的重要性远超过理论推测。以下是我的一些思考:
-
Pickle的优化: 我低估了Python的Pickle模块。多年的优化使它在处理简单数据结构时异常高效。
-
数据特性的影响: 这提醒我,不同的数据类型可能会导致不同的性能表现。
-
二进制操作的开销: 使用
struct.pack和struct.unpack的开销比我想象的要大。 -
mmap的应用场景: 这次测试让我意识到,mmap可能更适合处理更大规模的数据。
-
环境因素: 不同的Python版本和运行环境可能会影响性能测试结果,这点值得注意。
作为开发者,我们应该始终保持好奇心,不断探索和验证。只有这样,我们才能在这个瞬息万变的技术世界中不断进步,创造出更优秀的软件。
最后很好奇各位读者大大的运行结果是否和我一致…


















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









