






 本文详细介绍了如何在Linux上搭建Spark3.2.1的单机伪分布式集群,包括解压安装包、配置环境变量、启动集群、验证集群运行及使用SparkShell。
本文详细介绍了如何在Linux上搭建Spark3.2.1的单机伪分布式集群,包括解压安装包、配置环境变量、启动集群、验证集群运行及使用SparkShell。
搭建spark集群
解压Spark安装包
tar -zxf /opt/spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/
进入Spark安装目录的/bin目录,使用SparkPi计算Pi的值
cd /usr/local/spark-3.2.1-bin-hadoop2.7/bin/
./run-example SparkPi 2
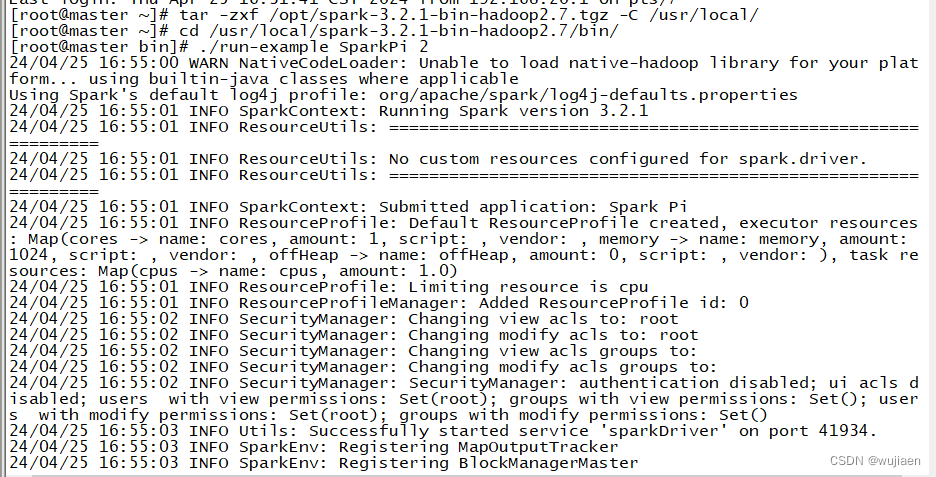
如果执行时输出非常多的运行日志信息,输出结果找不到,就使用grep命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中)
./bin/run-example SparkPi 2>&1 | grep "Pi is"
![]()
搭建单机伪分布式集群
将Spark安装包解压至Linux的/usr/local目录下
进入解压后的Spark安装目录的/conf目录下,复制spark-env.sh.template文件并重命名为spark-env.sh
cd /usr/local/spark-3.2.1-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh
准备好java环境
![]()
启动Spark集群
cd /usr/local/spark-3.2.1-bin-hadoop2.7/sbin/
./start-all.sh
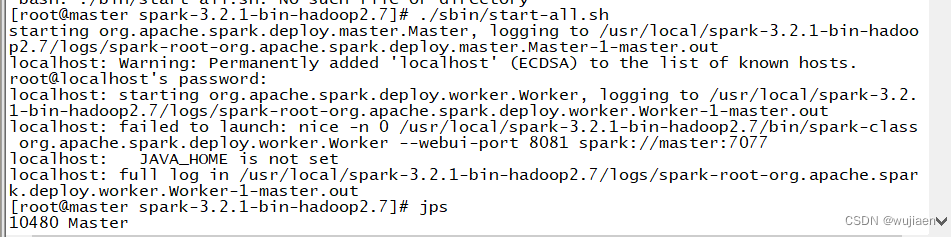
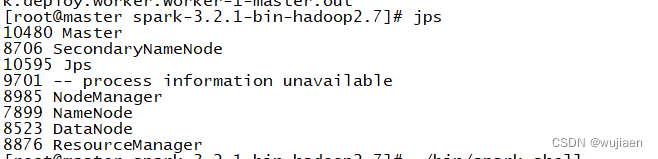
通过命令“jps”查看进程,如果既有Master进程又有Worker进程,那么说明Spark集群启动成功
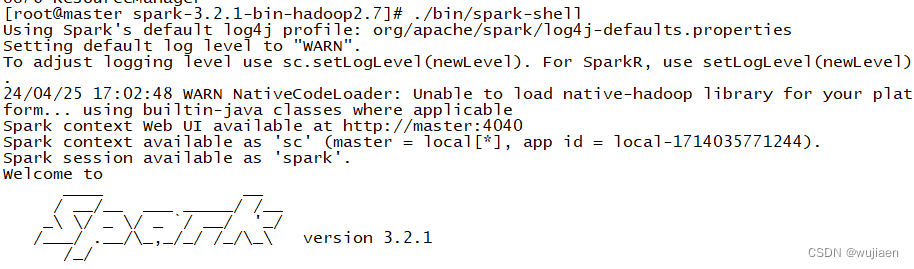
启动spark-shell
cd /usr/local/spark-3.2.1-bin-hadoop2.7/
./bin/spark-shell
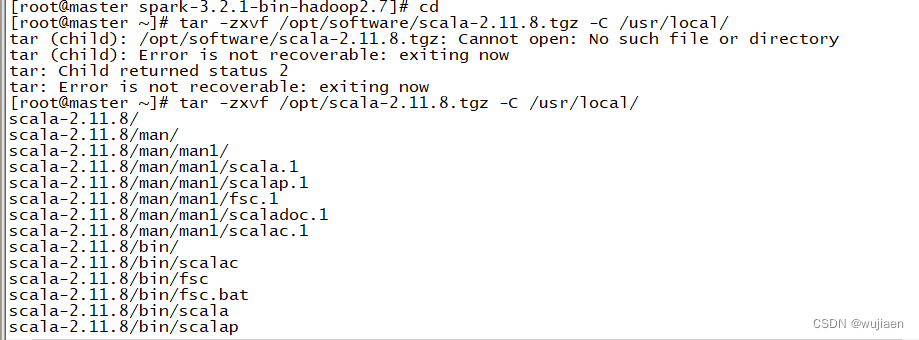
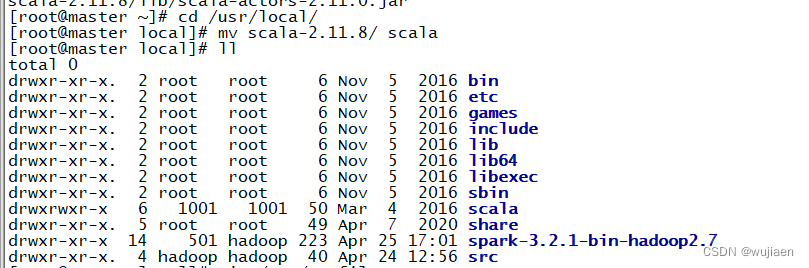

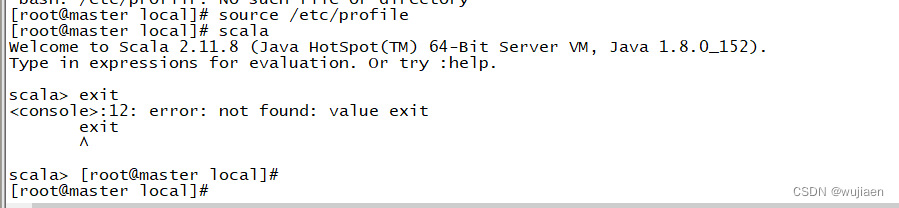
输入Scala命令检查是否能够进入Scala
scala
192.168.20.128:8080
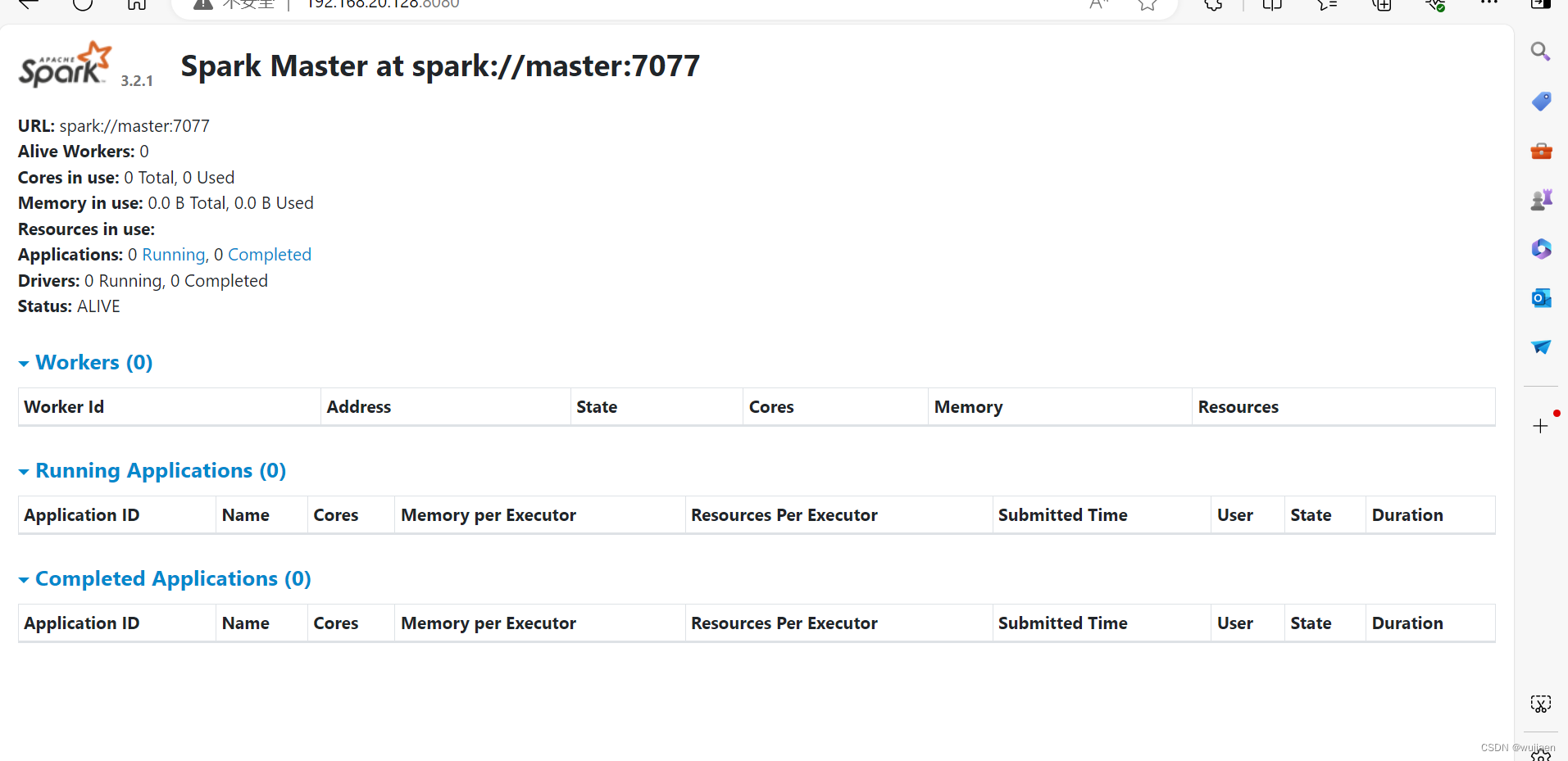
输入IP进入网页浏览
192.168.20.128:50070
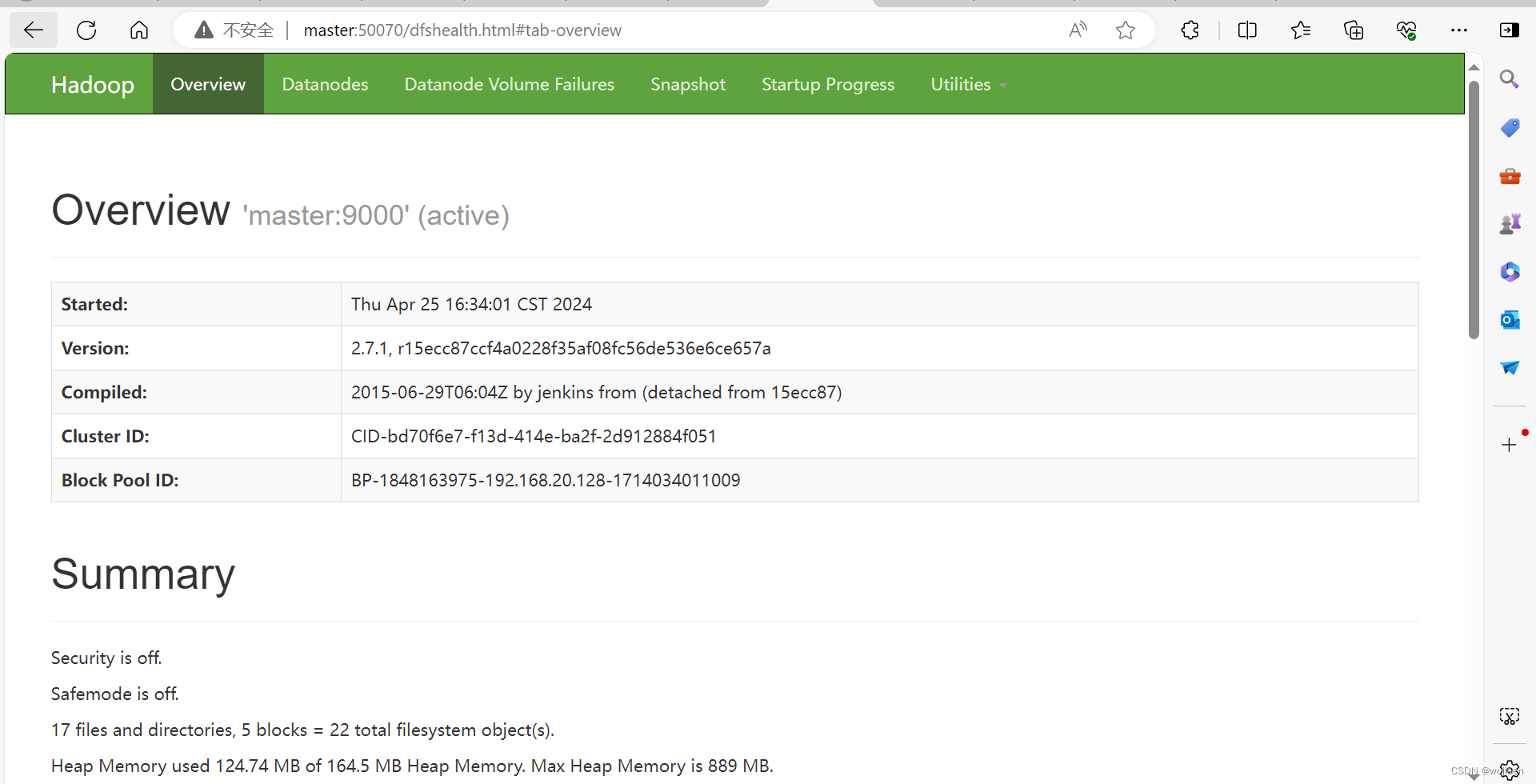















 3553
3553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









