









SQL Server中的哪些对象会占用磁盘空间? 看到标题的第一瞬间,让我想到的就是这个问题。下面我们就试着来讲一讲这个问题.
第一个磁盘空间使用大头肯定想到就是表。表只是一个逻辑对象,又没有想过表这个逻辑对象是怎么在磁盘上存储的呢? 《数据库系统实现原理》或者叫做《Database System implementation》一书中对表的存储方式应该有更详尽的描述。我们只讨论SQL SERVER的实现,所以不扯那么远。
SQL SERVER的空间分配,大的层面上来说,有file group, data file, log file之分。File group是逻辑上对data file和log file做分类。假设我们要新建一个database, 叫做lenistest。这个database 我们要分别将data file和log file归类到不同的file group里面,方便管理与维护。主要区别的是 primary file group和secondary file group,也就是 .mdf和.ndf的区别。
CREATE DATABASE [lenistest5]
ON
PRIMARY
( NAME = N'lenistest5',
FILENAME = N'E:\Data_BU\lenistest5.mdf' ,
SIZE = 10240KB ,
MAXSIZE = 102400KB ,
FILEGROWTH = 1024KB )
, filegroup maindatagroup
( NAME = N'lenistest5_data01',
FILENAME = N'E:\Data_BU\lenistest5_data01.ndf' ,
SIZE = 10240KB ,
MAXSIZE = 102400KB ,
FILEGROWTH = 1024KB )
, filegroup backupdatafg
( NAME = N'lenistest5_bk_data01',
FILENAME = N'E:\Data_BU\lenistest5_bk_data01.ndf' ,
SIZE = 10240KB ,
MAXSIZE = 10240KB ,
FILEGROWTH = 1024KB )
LOG ON
( NAME = N'lenistest5_log',
FILENAME = N'E:\Data_BU\lenistest5_log.ldf' ,
SIZE = 10240KB ,
MAXSIZE = 10240KB ,
FILEGROWTH = 1024KB )
GO用上面的这个SQL我们可以创建一个具有3个data file group, 和1个log file group的数据库 lenistest5 。.mdf全局唯一 ,不能有多个.mdf文件,但是可以有多个.ndf文件。我们是不是可以看到.mdf到底存储了什么?
select name
,recovery_model_desc
,is_auto_create_stats_on
,is_auto_create_stats_incremental_on
,is_auto_update_stats_on
,is_auto_update_stats_async_on
from sys.databases where name = 'lenistest5'这里可以看到刚创建的数据库有怎么样的恢复计划,这直接影响了日志的存储,还有统计信息更新计划,同样也会影响存储,更会影响执行计划的优劣,所以这也是需要创建数据后核实的。
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
select type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_filessys.filegroups, sys.database_files是归属于特定数据库的,所以运行的时候需要切换到特定的数据库底下。不象有些DMV是全局性的,不需要指定数据库,在任何数据库根目录下,都能查到一致性的数据,比如 sys.dm_tran_locks.
Is_default这里需要特别指出来 ,使因为如果在create table之后没有指定特别的file group,默认这个表就是存在这个file group之下。如果要更改这个default file group,我们可以这么做:
alter database lenistest5
modify filegroup maindatagroup defaultSize, max_size是以PAGE为单位来计算的。一个page的存储大小为8KB ,所以计算起来就是乘以8 ,再除以1024换成MB。
select
isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
order by f.data_space_id asc将 Filegroup 包含的所有 data file归纳起来,包括日志文件 。日志文件没有filegroup.
我们看看当新建一个表的时候,表结构及数据的存储:
create table dbo.sales(transactionDate datetime, amont int)看表数据存储需要借助 DBCC IND 和 DBCC PAGE. 默认情况下,我们执行这些 DBCC 命令, 输出文件不是我们的SSMS Console,所以需要将输出重定位,DBCC TraceOn(3604)可以帮我们把带输出的DBCC命令将结果输出到SSMS Console;DBCC TraceOn(3605)可以帮我们把带输出的DBCC命令将结果输出到SQL SERVER Error Log。这里我们选用DBCC TranceOn(3604). 命令的有效范围是当前session, 需要关掉的话用DBCC TraceOff(3604).
DBCC TraceOn(3604)
DBCC IND(lenistest5,'dbo.sales',0)当表里没有数据的时候,DBCC IND 是没有数据的,所以只显示:
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
DBCC IND 的语法是:
DBCC IND ( {dbname}, {table_name},{index_id} )
Index_id为0的时候,表示取的是堆表的信息,其他数值,等同于sys.indexes.index_id.
返回结果所包含的列有:
PageFID: page file Id. 数据页所在的数据文件的地址。也就是sys.database_files.file_id 的值。
PagePID: page id
IAMFID: index allocation MAP file id. 等同 sys.database_files.file_id.
IAMPID: Index allocation MAP page id
PageType : 注明了这个page的用途 :
1 - Data page
2 - Index page
3 - Large object page
4 - Large object page
8 - Global Allocation Map page
9 - Share Global Allocation Map page
10 - Index Allocation Map page
11 - Page Free Space page
13 - Boot page
15 - File header page
16 - Differential Changed Map page
17 - Bulk Changed Map page
其他字段比较容易理解。
既然知道了这一个页,比如IAMPID, 那我们就可以知道这个页到底存了哪些东西,还可以比较IAM page 与普通page的异同。 甚至还可以比较GAM, IAM, SGAM的不同,这放以后讨论。现在我们的表里暂时只有一条数据,所以总共才2个page. 一个IAM page,一个data page. 真好用来做比较。要想看一个page的存储内容,DBCC PAGE就该上场了。用法如下:
DBCC PAGE( {dbid|dbname}, pagenum [,print option] [,cache] [,logical] )
也有的是这么介绍的,毕竟这是非官方支持的命令,所以都试试
dbcc page ( {‘dbname’ | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])The filenum and pagenum parameters are taken from the page IDs that come from various system tables and appear in DBCC or other system error messages. A page ID of, say, (1:354) has filenum = 1 and pagenum = 354.
The printopt parameter has the following meanings:
0 – print just the page header
1 – page header plus per-row hex dumps and a dump of the page slot array (unless its a page that doesn’t have one, like allocation bitmaps)
2 – page header plus whole page hex dump
3 – page header plus detailed per-row interpretation
Filenum: 对应了DBCC IND结果集里的 pageFID, 数据文件的 ID
PAGENum:对应了 DBDD IND 结果集里的 pagePID, 数据页的 ID
PrintOpt:
0: page头文件信息
1: page头文件信息,加上每一行的16进制信息
2: page头文件信息,加上每一页的16进制信息
3: page头文件信息,加上详细的每一页的每一行的解释信息
似乎这里第二种写法比较靠谱:
DBCC PAGE (lenistest5, 3,9,3)
PAGE: (3:9)
BUFFER:
BUF @0x0000000484E524C0
bpage = 0x00000003F348C000 bhash = 0x0000000000000000 bpageno = (3:9)
bdbid = 35 breferences = 0 bcputicks = 0
bsampleCount = 0 bUse1 = 15680 bstat = 0xb
blog = 0x1212121c bnext = 0x0000000000000000
PAGE HEADER:
Page @0x00000003F348C000
m_pageId = (3:9) m_headerVersion = 1 m_type = 10
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x0
m_objId (AllocUnitId.idObj) = 120 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594045792256
Metadata: PartitionId = 72057594040549376 Metadata: IndexId = 0
Metadata: ObjectId = 245575913 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 90 m_slotCnt = 2 m_freeCnt = 6
m_freeData = 8182 m_reservedCnt = 0 m_lsn = (35:193:15)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (3:2) = ALLOCATED SGAM (3:3) = ALLOCATED
PFS (3:1) = 0x70 IAM_PG MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (3:6) =
CHANGEDML (3:7) = NOT MIN_LOGGED
IAM: Header @0x0000000012DFA064 Slot 0, Offset 96
sequenceNumber = 0 status = 0x0 objectId = 0
indexId = 0 page_count = 0 start_pg = (3:0)
IAM: Single Page Allocations @0x0000000012DFA08E
Slot 0 = (3:8) Slot 1 = (0:0) Slot 2 = (0:0)
Slot 3 = (0:0) Slot 4 = (0:0) Slot 5 = (0:0)
Slot 6 = (0:0) Slot 7 = (0:0)
IAM: Extent Alloc Status Slot 1 @0x0000000012DFA0C2
(3:0) - (3:1272) = NOT ALLOCATED
DBCC execution completed. If DBCC printed error messages, contact your
system administrator.
有这么一行需要特别注意的:
IAM: Single Page Allocations @0x0000000012DFA08E
Slot 0 = (3:8)
这是说明IAM PAGE 这一页记录了他所能管辖的数据页的分配,slot 0 =(3:8). 8就代表了data page id =8 .
而下面这一行,代表的就是IAM PAGE所在的page id
Page @0x00000003F348C000
m_pageId = (3:9)
比较下data page 与 IAM Page 的不同:
DBCC PAGE (lenistest5, 3,8,3)
PAGE: (3:8)
BUFFER:
BUF @0x0000000484E53D80
bpage = 0x00000003F34AA000 bhash = 0x0000000000000000 bpageno = (3:8)
bdbid = 35 breferences = 0 bcputicks = 0
bsampleCount = 0 bUse1 = 16691 bstat = 0xb
blog = 0x212121cc bnext = 0x0000000000000000
PAGE HEADER:
Page @0x00000003F34AA000
m_pageId = (3:8) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000
m_objId (AllocUnitId.idObj) = 120 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594045792256
Metadata: PartitionId = 72057594040549376 Metadata: IndexId = 0
Metadata: ObjectId = 245575913 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 16 m_slotCnt = 1 m_freeCnt = 8075
m_freeData = 115 m_reservedCnt = 0 m_lsn = (35:193:28)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (3:2) = ALLOCATED SGAM (3:3) = ALLOCATED
PFS (3:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (3:6) = CHANGED
ML (3:7) = NOT MIN_LOGGED
Slot 0 Offset 0x60 Length 19
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record
Size = 19Memory Dump @0x000000001AF5A060
0000000000000000: 10001000 bb7d7701 10a60000 01000000 020000
….»}w..¦………Slot 0 Column 1 Offset 0x4 Length 8 Length (physical) 8
transactionDate = 2016-05-24 22:47:07.290
Slot 0 Column 2 Offset 0xc Length 4 Length (physical) 4
amont = 1
这页存储的数据一目了然,而且数据类型,字节大小都明白的告诉我们了:
Slot 0 Column 1 Offset 0x4 Length 8 Length (physical) 8
transactionDate = 2016-05-24 22:47:07.290
Slot 0 Column 2 Offset 0xc Length 4 Length (physical) 4
amont = 1
到这里我们已经可以用脚本来归纳所有file group, data file,以及table ,index的对应关系了:利用 DBCC IND来获取整个数据库 表和索引的文件对应关系。还有一种方法,使用新增加的DMC来查询,这个DMV是 sys.dm_db_database_page_allocations.分清楚表和索引的存储关系,不仅仅是方便管理,更有利于性能的提高,表和索引分别存储在不同的硬盘驱动器上,有利于并行处理。
use lenistest4
go
declare @tablename varchar(200)
declare @index_Id int
declare @sqlstatement nvarchar(max)
declare @databasename varchar(200) ='lenistest4'
declare cur_tables cursor
for (select schema_name(schema_id) +'.'+name as tableName
from sys.tables )
open cur_tables
fetch next from cur_tables into @tablename
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;
create table #tempTabIndall(PageFID bigint, PagePID bigint, IAMFID bigint, IAMPID bigint, ObjectID bigint, IndexId bigint, PartitionNumber bigint, PartitionID bigint,
iam_chain_type varchar(500) , PageType bigint, IndexLevel bigint, NextPageFID bigint, NextPagePID bigint,PrevPageFID bigint, PrevPagePID bigint)
create index idx_pagefid on #tempTabIndall(PageFID) ;
while @@FETCH_STATUS = 0
begin
declare cur_indexes cursor for
(select index_id from sys.indexes where object_id = object_id(@tablename))
open cur_indexes
fetch next from cur_indexes into @index_Id
while @@FETCH_STATUS = 0
begin
set @sqlstatement = N'insert into #tempTabIndall
exec sp_executesql N''DBCC IND(' + @databasename + ','''''+@tablename+''''',' + convert(varchar(max),@index_Id)+')''' ;
print @sqlstatement
exec sp_executesql @sqlstatement
fetch next from cur_indexes into @index_Id
end
close cur_indexes
deallocate cur_indexes
fetch next from cur_tables into @tablename
end
close cur_tables
deallocate cur_tables
select distinct
object_name(t.ObjectID) as tablename
, t.IndexId
, ti.name as IndexName
, f.FileGroupName
, f.Filegroup_type_description
, f.DefaultFileGroup
, f.datafile_type_description
, f.fileName
, f.file_physical_name
from #tempTabIndall t
inner join (select distinct object_id,index_id,name from sys.indexes) ti on t.ObjectID = ti.object_id and t.IndexId = ti.index_id
left join (
select
isnull(data_file_id,0 ) as data_file_id
, isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select
file_id as data_file_id
,type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
)f on f.data_file_id = t.PageFID
order by f.file_physical_name asc ,object_name(t.ObjectID) asc, t.IndexId asc这里还顺带出来一个问题,就是我没有在脚本的最后用drop temporary table来丢弃临时表,结果导致很多temporary table剩下tempdb里面.问题来了,我们怎么丢弃一些别的session没有关闭的临时表呢? 这些临时表驻留的时间范围是什么, 是不是创建临时表的session已关闭,临时表就不存在了呢?
select * from tempdb.sys.tables
where upper(name) like upper('%TEMPTABIND%')查出来有两个临时表,不同名,但是类似,在非创建临时表的session中,没有办法访问这些临时表。尝试丢弃这些表,报错:
drop table #tempTabIndall______________________________________________________________________________________________________0000000032A4
Msg 3701, Level 11, State 5, Line 3
Cannot drop the table ‘#tempTabIndall______________________________________________________________________________________________________0000000032A4’, because it does not exist or you do not have permission.
所以创建临时表的时候,判断同名的临时表是否存在,还需要判断同名的临时表是不是本session创建的,如果不是,就需要重新改临时表名了
这样写,其实是有风险的:因为这个临时表并不一定是此session创建的
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;即使临时表是本session创建的,但是在本session中是不能被drop之后,再重新建的,比如下面这种做法是会出错的,我认为临时表的表变量名在一个batch中是固定的,重新创建的时候,相当于是给同一个变量在同一个session中变换两次数据类型,所以报错:
use lenistest5
go
IF OBJECT_ID('tempdb..#Results') IS NOT NULL
DROP TABLE #Results
CREATE TABLE #Results
(
Company CHAR(3),
StepId TINYINT,
FieldId TINYINT,
)
select Company, StepId, FieldId from #Results
--Works fine to this point
select * from tempdb.sys.tables where upper(name) like '%RESULTS%'
IF OBJECT_ID('tempdb..#Results') IS NOT NULL
DROP TABLE #Results
select * from tempdb.sys.tables where upper(name) like '%RESULTS%'
CREATE TABLE #Results
(
Company CHAR(3),
StepId TINYINT,
FieldId TINYINT,
NewColumn NVARCHAR(50)
)
select Company, StepId, FieldId, NewColumn from #ResultsMsg 2714, Level 16, State 1, Line 26
There is already an object named ‘#Results’ in the database.
参考同一个变量在同一个batch中两次更改数据类型的错误:
declare @temp int = 0
declare @temp varchar(20) = 'leis'Msg 134, Level 15, State 1, Line 36
The variable name ‘@temp’ has already been declared. Variable names
must be unique within a query batch or stored procedure.
那么解决方法就是分割batch,或者使用不同的变量名,或者针对上述的例子用Alter table. 对于变量,还可以用sql_variant,很神奇的一种数据类型,可以在运行时的同一个batch里面,装载不同的数据类型:
declare @temp sql_variant
set @temp = 0
select @temp
set @temp = 'lenis'
select @temp上面讨论了关于 data page, index page存储的问题,用的是sql server非文档化的两个dbcc函数, dbcc ind和dbcc page. 其实sql server为了支持这两个函数的功能,在SQL SERVER 2012中提供了一个DMV,叫做sys.dm_db_database_page_allocations。 下面我们讨论下这个DMV的用法:
sys.dm_db_database_page_allocations
(@DatabaseId , @TableId , @IndexId , @PartionID , @Mode)Parameters :
@DatabaseId :You need to pass the required database ID. This parameter is mandatory and data type of this argument is small integer.
@TableId:You need to pass the required table ID. This parameter is optional and data type of this argument is integer.
@IndexId:You need to pass the required Index ID. This parameter is optional and data type of this argument is integer.
@PartionID:You need to pass the required Partion ID. This parameter is optional and data type of this argument is integer.
@Mode:You need to pass the required Mode. This parameter is mandatory and data type of this argument is nvarchar(64). In this argument we must pass only ‘DETAILED’ OR ‘LIMITED’.
下面是个简单的例子:
select object_name(object_id) as tableName
, index_id
,partition_id
,allocation_unit_id
,allocation_unit_type_desc
,extent_file_id
,extent_page_id
,allocated_page_iam_file_id
,allocated_page_iam_page_id
,allocated_page_file_id
,allocated_page_page_id
,is_allocated
,is_iam_page
,is_mixed_page_allocation
,page_free_space_percent
,page_type_desc
,is_page_compressed
from sys.dm_db_database_page_allocations(db_id(N'lenistest3'),object_id(N'dbo.FctSalesMonth'),0,NULL,'DETAILED')我们选取一张分区表作为测试,这表没有primary key,所以是个堆表(heap table),他有一个index(这儿有个问题:当我们为一个分区表创建一个索引的时候,这个新创建的索引是不是也会被自动分区,如果我们不需要这索引自动分区,我们该如何操作?) 。
在这个DMV的参数里面,@IndexId可以为null,结果是把所有的堆表和所有的index数据页都查询出来了.如果我们给@IndexId赋予一个值,那么0代表堆表,1代表聚合索引(clustered table), 2 以上代表其他索引。
@Mode这个参数只有两个值, Detailed和Limited. 两者的区别很小,limited将page_type, page_type_desc, page_level, is_page_compressed都置为NULL了。
对于分区表来说,每一个partition都会有一个IAM PAGE.所以一开始选分区表也是瞎猫碰倒死耗子,能得出这么个结论。
接下来我们看下如何用这个DMV 来实现 dbcc page, dbcc ind的功能:
use lenistest4
go
declare @tablename varchar(200)
declare @index_Id int
declare @sqlstatement nvarchar(max)
declare @databasename varchar(200) ='lenistest4'
declare cur_tables cursor
for (select schema_name(schema_id) +'.'+name as tableName
from sys.tables )
open cur_tables
fetch next from cur_tables into @tablename
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;
create table #tempTabIndall( ObjectID bigint, IndexId bigint, PartitionID bigint, allocation_unit_id bigint
,allocation_unit_type_desc varchar(500)
,extent_file_id bigint
,extent_page_id bigint
,IAMFID bigint, IAMPID bigint
,PageFID bigint, PagePID bigint
,is_allocated int, is_iam_page int, is_mixed_page_allocation int
,page_free_space_percent int
,Page_Type_Desc varchar(200)
,is_page_compressed int,IndexLevel bigint
,NextPageFID bigint, NextPagePID bigint,PrevPageFID bigint, PrevPagePID bigint)
create index idx_pagefid on #tempTabIndall(PageFID) ;
while @@FETCH_STATUS = 0
begin
declare cur_indexes cursor for
(select index_id from sys.indexes where object_id = object_id(@tablename))
open cur_indexes
fetch next from cur_indexes into @index_Id
while @@FETCH_STATUS = 0
begin
/*
set @sqlstatement = N'insert into #tempTabIndall
exec sp_executesql N''DBCC IND(' + @databasename + ','''''+@tablename+''''',' + convert(varchar(max),@index_Id)+')''' ;
*/
set @sqlstatement = N' insert into #tempTabIndall
select object_id as object_id
, index_id
,partition_id
,allocation_unit_id
,allocation_unit_type_desc
,extent_file_id
,extent_page_id
,allocated_page_iam_file_id
,allocated_page_iam_page_id
,allocated_page_file_id
,allocated_page_page_id
,is_allocated
,is_iam_page
,is_mixed_page_allocation
,page_free_space_percent
,page_type_desc
,is_page_compressed
,page_level
,next_page_file_id
,next_page_page_id
,previous_page_file_id
,previous_page_page_id
from sys.dm_db_database_page_allocations(db_id(N'''+@databasename+'''),object_id(N'''+@tablename+'''),'+ convert(nvarchar(max),@index_Id) +',NULL,''detailed'')';
print @sqlstatement
exec sp_executesql @sqlstatement
fetch next from cur_indexes into @index_Id
end
close cur_indexes
deallocate cur_indexes
fetch next from cur_tables into @tablename
end
close cur_tables
deallocate cur_tables
select distinct
object_name(t.ObjectID) as tablename
, t.IndexId
, ti.name as IndexName
, f.FileGroupName
, f.Filegroup_type_description
, f.DefaultFileGroup
, f.datafile_type_description
, f.fileName
, f.file_physical_name
from #tempTabIndall t
inner join (select distinct object_id,index_id,name from sys.indexes) ti on t.ObjectID = ti.object_id and t.IndexId = ti.index_id
left join (
select
isnull(data_file_id,0 ) as data_file_id
, isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select
file_id as data_file_id
,type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
)f on f.data_file_id = t.PageFID
order by f.file_physical_name asc ,object_name(t.ObjectID) asc, t.IndexId asc
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;刚才我们谈到分区表, 创建一个分区表大致的方法如下:先建立一个分区函数(partition function), 在建立分区表的时候,以分区字段调用分区函数。这里有必要谈下分区函数用到的分区字段,这里只允许依照分区字段的离散值来分区,而不能依据分区字段的值区间分区。相比oracle的三种分区函数,SQL SERVER仅支持了 list表分区。再建立分区 scheme(partition scheme), 按照某一个字段(比如时间字段,按照月份作分区)建立 scheme, 比如从 2010年 1月份开始建立到 2020年12月份的分区 scheme。scheme的作用就是将分区函数指定的分区值区间对应到不同的文件组file group 上。
语法:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]create partition function Monthly(datetime)
as range left
for values('20160101','20160201','20160301','20160401','20160501')
go
create partition scheme MonthlySch
as partition Monthly
all to ([PRIMARY])
go
CREATE TABLE dbo.FctSalesMonth (OrderMon datetime, OrderAmount int ) on MonthlySch(OrderMon)
go
insert into dbo.FctSalesMonth (OrderMon,OrderAmount) values('2016-01-01',200)
insert into dbo.FctSalesMonth (OrderMon,OrderAmount) values('2016-01-02',200)
insert into dbo.FctSalesMonth (OrderMon,OrderAmount) values('2016-02-01',200)
insert into dbo.FctSalesMonth (OrderMon,OrderAmount) values('2016-03-04',200)
go
select partition_id,object_name(object_id) as tableName,index_id,partition_number,row_count
from sys.dm_db_partition_stats where object_id = object_id(N'dbo.FctSalesMonth')
go这里要注意的地方就是 AS RANG LEFT|RIGHT 的区别:LEFT 表示以左边第一个值为基准,小于等于这个值的其他记录都放到第一个分区,大于第一个值且小于等于第二个值的记录都放在第二个分区。LEFT与RIGHT是非常绕的两个概念,我是这样理解的:上面列出的这些临界点,把整个平面划成了左右两部分,就是LEFT RANGE 和RIGHT RANGE。当我们需要把这些临界点放在左边的RANGE的时候,我们就用RANGE LEFT,相反我们需要把临界点放在右边这个RANGE的时候,我们就用RANGE RIGHT。
分区的目的无非就是把一张大表拆分成若干个小表存在不同的存储介质上,以减轻磁盘访问的压力,支持大并发。比如我服务器上有三块硬盘,每块1T,一张表有6亿条数据,如果将这一张表都存储在同一块硬盘上,磁盘访问的顺序肯定是按照一定顺序来的,要么是sequential read要么是random read,但如果分成2亿条数据存一块硬盘,那么同一时间可以访问原先3倍的数据。速度孰快一眼便知。
存储这块除了表之外,还有很多话题,比如index, Log file, Backup, Error Log等等。当然还包含分布式存储。
Index 的存储在表存储这块其实已经讨论的差不多了。主要的两块还没细讲,一是索引的选取规则,二是索引的碎片。 索引的选取规则,在查询优化这块已经有所涉及,我们一会儿看看是不失有什么补充,本节的内容主要看的是索引的锁片。
索引碎片的产生原理是什么,如何监控索引的碎片状态,遇到什么样的碎片状态需要采取行动,以及怎么样处理碎片的方法。
索引碎片产生的原因,是因为索引条目的增删改减,举个例子,删的情况容易理解,就是删掉了索引条目,但是原来的slot在page上还留着,而这个slot接下来的slot可能被移动到下一个index page里面去了,久而久之 ,空闲的slot越来越多,index scan的效率也就越来越慢了。这里有几个因素会影响索引碎片的: 一是page fillfactor,就是打算空多少给 update, insert用的空间。比如当一个page存满85%的时候,需要空余15%给update或者insert,而不至于更加一条记录或者更改稍微大一点的字段值,就把那一页给撑爆,而造成page split数据页的分割。数据页的分割会打乱排序,重新计算分配新数据页。二是刚提到的page split,数据页的分割,会造成很多page有很多空余空间。这里增删改都能造成page split了。
我们可以改变上面的SQL, 让他支持查询每一个表,每一个索引的Page页面顺序:
declare @tablename varchar(200)
declare @index_Id int
declare @sqlstatement nvarchar(max)
declare @databasename varchar(200) ='lenistest4'
declare cur_tables cursor
for (select schema_name(schema_id) +'.'+name as tableName
from sys.tables )
open cur_tables
fetch next from cur_tables into @tablename
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;
create table #tempTabIndall( ObjectID bigint, IndexId bigint, PartitionID bigint, allocation_unit_id bigint
,allocation_unit_type_desc varchar(500)
,extent_file_id bigint
,extent_page_id bigint
,IAMFID bigint, IAMPID bigint
,PageFID bigint, PagePID bigint
,is_allocated int, is_iam_page int, is_mixed_page_allocation int
,page_free_space_percent int
,Page_Type_Desc varchar(200)
,is_page_compressed int,IndexLevel bigint
,NextPageFID bigint, NextPagePID bigint,PrevPageFID bigint, PrevPagePID bigint)
create index idx_pagefid on #tempTabIndall(PageFID) ;
while @@FETCH_STATUS = 0
begin
declare cur_indexes cursor for
(select index_id from sys.indexes where object_id = object_id(@tablename))
open cur_indexes
fetch next from cur_indexes into @index_Id
while @@FETCH_STATUS = 0
begin
/*
set @sqlstatement = N'insert into #tempTabIndall
exec sp_executesql N''DBCC IND(' + @databasename + ','''''+@tablename+''''',' + convert(varchar(max),@index_Id)+')''' ;
*/
set @sqlstatement = N' insert into #tempTabIndall
select object_id as object_id
, index_id
,partition_id
,allocation_unit_id
,allocation_unit_type_desc
,extent_file_id
,extent_page_id
,allocated_page_iam_file_id
,allocated_page_iam_page_id
,allocated_page_file_id
,allocated_page_page_id
,is_allocated
,is_iam_page
,is_mixed_page_allocation
,page_free_space_percent
,page_type_desc
,is_page_compressed
,page_level
,next_page_file_id
,next_page_page_id
,previous_page_file_id
,previous_page_page_id
from sys.dm_db_database_page_allocations(db_id(N'''+@databasename+'''),object_id(N'''+@tablename+'''),'+ convert(nvarchar(max),@index_Id) +',NULL,''detailed'')';
print @sqlstatement
exec sp_executesql @sqlstatement
fetch next from cur_indexes into @index_Id
end
close cur_indexes
deallocate cur_indexes
fetch next from cur_tables into @tablename
end
close cur_tables
deallocate cur_tables
select distinct
object_name(t.ObjectID) as tablename
, t.IndexId
, ti.name as IndexName
, f.FileGroupName
, f.Filegroup_type_description
, f.DefaultFileGroup
, f.datafile_type_description
, f.fileName
, f.file_physical_name
, t. IAMFID allocated_page_iam_file_id
, t.IAMPID allocated_page_iam_page_id
, t.PageFID allocated_page_file_id
, t.PagePID allocated_page_page_id
, t.NextPageFID next_page_file_id
, t.NextPagePID next_page_page_id
, t.page_free_space_percent
, t.PrevPageFID previous_page_file_id
, t.PrevPagePID previous_page_page_id
from #tempTabIndall t
inner join (select distinct object_id,index_id,name from sys.indexes) ti on t.ObjectID = ti.object_id and t.IndexId = ti.index_id
Right join (
select
isnull(data_file_id,0 ) as data_file_id
, isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select
file_id as data_file_id
,type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
)f on f.data_file_id = t.PageFID
order by f.file_physical_name asc ,object_name(t.ObjectID) asc, t.IndexId asc
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;这里需要注意的是,当一个table仅仅被创建,但是还没有赋值的时候,是没有page被分配到这个表的,所以这个时候,sys.dm_db_database_page_allocations是没有相关表的记录的。我们只要insert一条记录就可以在sys.dm_db_database_page_allocations或者dbcc page,dbcc ind里面找到了。
create table dbo.FragementIndexTable (Ind int, IndText char(46)) ;
declare @int int = 0 ;
while (@int < 160)
begin
insert into dbo.FragementIndexTable(Ind,IndText) values(@int, 'data_'+ convert(varchar,@int)) ;
set @int = @int + 1
end我们新建一张表,往里面输入160条数据,每天数据的长度是50bytes,所以理论上160条数据才占8000bytes,小于一个page =8*1024 bytes。但是这160条数据被分配到了2个页面上。第一个页面占了131条数据。为什么一个页面8196bytes不能容下160条长度为50bytes的数据呢? 这还要从数据页的结构说起:结构包含了三部分,一是数据页头header, 可以用dbcc page(databasename|db_id, Data File Id, Page Id, 0) 察看,这部分数据是固定的,共占96bytes;第二部分就是数据记录,每条数据记录还附带7bytes的开销;第三部分是offset,每条数据会使用2bytes来记录每条记录的位置。
针对offset, 详细记录了记录的次序以及记录的起始物理地址:dbcc page(,,option = 2)
OFFSET TABLE:
Row - Offset
8 (0x8) - 552 (0x228)
7 (0x7) - 495 (0x1ef)
6 (0x6) - 438 (0x1b6)
5 (0x5) - 381 (0x17d)
4 (0x4) - 324 (0x144)
3 (0x3) - 267 (0x10b)
2 (0x2) - 210 (0xd2)
1 (0x1) - 153 (0x99)
0 (0x0) - 96 (0x60)
针对page header, 我们粗浅的解释下这里面的几个指标: 详细的可以看这篇文章:Inside the Storage Engine: Anatomy of a page
Page @0x00000003D9402000
m_pageId = (1:2227) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8200
m_objId (AllocUnitId.idObj) = 153 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594047954944
Metadata: PartitionId = 72057594042515456 Metadata: IndexId = 0
Metadata: ObjectId = 1525580473 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 54 m_slotCnt = 131 m_freeCnt = 367
m_freeData = 7563 m_reservedCnt = 0 m_lsn = (43:265188:2)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = -1895774294 DB Frag ID = 1
m_slotCnt = 131, 这一页总共有131条记录, m_freecnt = 367,这一页总共还有367bytes未被使用。既然有这么多的空余空间没有被使用,那么为什么他们没有被分配呢?我想这恰恰是因为碎片存在的理由的吧.如果把这些碎片都清理干净,那么scan, seek效率都会高很多。至于为什么会产生碎片,上面那个引用文章写得很清楚,我就尝试着翻译和解说下:关于data page,我们有很多误解的地方,比如数据在page上都是按照顺序从下到下写入的,比如空闲空间都是一大块。如果这些误解都是真正的机制,那么也就不存在碎片的问题了。数据在写入的时候,都是见缝插针,也就是有地方能容纳下这个长度的一行,就直接写进去了,而不是先去整理下空间,排序好,然后写入,这样一来性能开销不小,二来产生很多数据页的重新分配(data page flow)和数据页的分割(data page split)。所以最有效的方法就是维护好offset,然后迅速找空间或者申请空间写入到数据页。当我们执行删除操作的时候,数据页上的数据也不马上归档清零,而是等待下次执行写入新数据的时候,再归档清零。举个例子,当有序写入的时候,数据页上删除的slot就要清零重写。
从上面的例子看来,我们的table FragementIndexTable 在它的第一页上是有碎片存在的,我们是不是可以整理下,看看是不是能容纳下更多的数据呢? 我们看几个方法:
- 使用primary key或者 unique clustered来组织堆表?
create unique clustered index idx_ind_indtext on dbo.FragementIndexTable(Ind,IndText) ;结果发现原本只有 2个page的表存储,现在变成三个page了,中间有一个page还是另外两个page的parent page。
当然数据也更加存储的多了,因为有排序了,我们在第一个page里面看到, m_slotCnt = 137 , m_freeCnt = 13。 这里显然比前面的 m_slotcnt = 131, m_freecnt = 367 多存储了6条数据, 6*57共 342 bytes,加上每天数据2bytes offset, 共 6*2 =12 bytes, 342 加上 12得354,还剩下13bytes,即 m_freecnt = 13.
这儿多了一个page, 关联的是2个子page,这两个子page恰好是以136这个值为分界线,将2个page一左一右的分割开来, 小于索引值的分一个,大于索引值的分到另一个page。所以这就组成了一个树状结构的最小原型。这个page的数据条目数,跟分割的page总数一致,有2个数据页被分割,就有2条记录。看看当有三个page被分割的时候,是不是有3条记录? 在我们的例子里,我们重新插入137条数据,这样新建一个page,再看看:
declare @int int
select @int = max(Ind) from dbo.FragementIndexTable ;
declare @loop int = @int + 1
while (@loop <= @int + 137)
begin
insert into dbo.FragementIndexTable(Ind,IndText) values(@loop, 'data_'+ convert(varchar,@loop)) ;
set @loop = @loop + 1
end经过验证,这里确实只是在这个Level1级的数据页里面增加了一条记录。这里还要注意的是,为什么以一页里面最大值作为分割点? 我猜这里的目的是因为我们的索引是从小到大建立的,所以最大值确认的话,最小值就是上一页的最大值的后一条记录。这里必须用个图来解释一下:

上面的图告诉我们,这个page里面有3条记录,分别对应了三个page, 2235, 2237,2241. 我们这个page的Level是1,对应的3个page的Level是0. 索引, Ind + IndText,所有小于136, data_136的值都在page 2235里面,136 -272的数据都在page 2237。 所以照常推理, 应该达到137*137条记录的时候,会有level2的页面出现。137为一页,137页产生一个level.
declare @int int
select @int = max(Ind) from dbo.FragementIndexTable ;
declare @loop int = @int + 1
while (@loop <= 137*137)
begin
insert into dbo.FragementIndexTable(Ind,IndText) values(@loop, 'data_'+ convert(varchar,@loop)) ;
set @loop = @loop + 1
end每增加一个level, level字段就加1。凡是同一个level有2个page,那么会自动生成高一级的level.
把page header的字段含义贴一下 ,同样还是引自上篇外文:
Here’s what all the fields mean (note that the fields aren’t quite stored in this order on the page):
· m_pageId
o This identifies the file number the page is part of and the position within the file. In this example, (1:143) means page 143 in file 1.
· m_headerVersion
o This is the page header version. Since version 7.0 this value has always been 1.
· m_type
o This is the page type. The values you’re likely to see are:
§ 1 – data page. This holds data records in a heap or clustered index leaf-level.
§ 2 – index page. This holds index records in the upper levels of a clustered index and all levels of non-clustered indexes.
§ 3 – text mix page. A text page that holds small chunks of LOB values plus internal parts of text tree. These can be shared between LOB values in the same partition of an index or heap.
§ 4 – text tree page. A text page that holds large chunks of LOB values from a single column value.
§ 7 – sort page. A page that stores intermediate results during a sort operation.
§ 8 – GAM page. Holds global allocation information about extents in a GAM interval (every data file is split into 4GB chunks – the number of extents that can be represented in a bitmap on a single database page). Basically whether an extent is allocated or not. GAM = Global Allocation Map. The first one is page 2 in each file. More on these in a later post.
§ 9 – SGAM page. Holds global allocation information about extents in a GAM interval. Basically whether an extent is available for allocating mixed-pages. SGAM = Shared GAM. the first one is page 3 in each file. More on these in a later post.
§ 10 – IAM page. Holds allocation information about which extents within a GAM interval are allocated to an index or allocation unit, in SQL Server 2000 and 2005 respectively. IAM = Index Allocation Map. More on these in a later post.
§ 11 – PFS page. Holds allocation and free space information about pages within a PFS interval (every data file is also split into approx 64MB chunks – the number of pages that can be represented in a byte-map on a single database page. PFS = Page Free Space. The first one is page 1 in each file. More on these in a later post.
§ 13 – boot page. Holds information about the database. There’s only one of these in the database. It’s page 9 in file 1.
§ 15 – file header page. Holds information about the file. There’s one per file and it’s page 0 in the file.
§ 16 – diff map page. Holds information about which extents in a GAM interval have changed since the last full or differential backup. The first one is page 6 in each file.
§ 17 – ML map page. Holds information about which extents in a GAM interval have changed while in bulk-logged mode since the last backup. This is what allows you to switch to bulk-logged mode for bulk-loads and index rebuilds without worrying about breaking a backup chain. The first one is page 7 in each file.
§ 18 – a page that’s be deallocated by DBCC CHECKDB during a repair operation.
§ 19 – the temporary page that ALTER INDEX … REORGANIZE (or DBCC INDEXDEFRAG) uses when working on an index.
§ 20 – a page pre-allocated as part of a bulk load operation, which will eventually be formatted as a ‘real’ page.
· m_typeFlagBits
o This is mostly unused. For data and index pages it will always be 4. For all other pages it will always be 0 – except PFS pages. If a PFS page hasm_typeFlagBits of 1, that means that at least one of the pages in the PFS interval mapped by the PFS page has at least one ghost record.
· m_level
o This is the level that the page is part of in the b-tree.
o Levels are numbered from 0 at the leaf-level and increase to the single-page root level (i.e. the top of the b-tree).
o In SQL Server 2000, the leaf level of a clustered index (with data pages) was level 0, and the next level up (with index pages) was also level 0. The level then increased to the root. So to determine whether a page was truly at the leaf level in SQL Server 2000, you need to look at the m_type as well as them_level.
o For all page types apart from index pages, the level is always 0.
· m_flagBits
o This stores a number of different flags that describe the page. For example, 0x200 means that the page has a page checksum on it (as our example page does) and 0x100 means the page has torn-page protection on it.
o Some bits are no longer used in SQL Server 2005.
· m_objId
· m_indexId
o In SQL Server 2000, these identified the actual relational object and index IDs to which the page is allocated. In SQL Server 2005 this is no longer the case. The allocation metadata totally changed so these instead identify what’s called the allocation unit that the page belongs to. This post explains how an allocation unit ID is calculated. Note that for databases upgraded from SQL Server 2000, they will still be the the actual object ID and index ID. Also for databases on all versions, many system tables still have these be the actual object and index IDs.
· m_prevPage
· m_nextPage
o These are pointers to the previous and next pages at this level of the b-tree and store 6-byte page IDs.
o The pages in each level of an index are joined in a doubly-linked list according to the logical order (as defined by the index keys) of the index. The pointers do not necessarily point to the immediately adjacent physical pages in the file (because of fragmentation).
o The pages on the left-hand side of a b-tree level will have the m_prevPage pointer be NULL, and those on the right-hand side will have the m_nextPage be NULL.
o In a heap, or if an index only has a single page, these pointers will both be NULL for all pages.
· pminlen
o This is the size of the fixed-length portion of the records on the page.
· m_slotCnt
o This is the count of records on the page.
· m_freeCnt
o This is the number of bytes of free space in the page.
· m_freeData
o This is the offset from the start of the page to the first byte after the end of the last record on the page. It doesn’t matter if there is free space nearer to the start of the page.
· m_reservedCnt
o This is the number of bytes of free space that has been reserved by active transactions that freed up space on the page. It prevents the free space from being used up and allows the transactions to roll-back correctly. There’s a very complicated algorithm for changing this value.
· m_lsn
o This is the Log Sequence Number of the last log record that changed the page.
· m_xactReserved
o This is the amount that was last added to the m_reservedCnt field.
· m_xdesId
o This is the internal ID of the most recent transaction that added to the m_reservedCnt field.
· m_ghostRecCnt
o The is the count of ghost records on the page.
· m_tornBits
o This holds either the page checksum or the bits that were displaced by the torn-page protection bits – depending on what form of page protection is turnde on for the database.
2 上面用的是clustered index来避免碎片,提高空间利用率。但是有时候也避免不了大数据量冲刷下的碎片。我们可以用sys.dm_db_index_physical_stats随时查看索引的碎片情况,开启索引碎片整理窗口。
sys.dm_db_index_physical_stats (
{ database_id | NULL | 0 | DEFAULT }
, { object_id | NULL | 0 | DEFAULT }
, { index_id | NULL | 0 | -1 | DEFAULT }
, { partition_number | NULL | 0 | DEFAULT }
, { mode | NULL | DEFAULT }
)Fragmentation of table and index:碎片会导致随机读(random read),都只知道顺序读(sequential read)是效率最高的。那么怎么去判断我们要执行碎片整理了呢,什么样的碎片整理方法有效呢?在DMV里面有张表,Sys.dm_db_index_physical_stats ,我们要关注的一个字段就是avg_fragmentation_in_percent。
当avg_fragmentation_in_percent 在5%和30%之间的时候,用Alter index Recoganize;当avg_fragmentation_in_percent 大于30%的时候,用Alter Index Rebuild。当然终极方法 drop index之后create index也是可以的,但是你想想会有什么后果。
ALTER INDEX { index_name | ALL } ON <object>
{
REBUILD {
[ PARTITION = ALL ] [ WITH ( <rebuild_index_option> [ ,...n ] ) ]
| [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> ) [ ,...n ] ]
}
| DISABLE
| REORGANIZE [ PARTITION = partition_number ] [ WITH ( <reorganize_option> ) ]
| SET ( <set_index_option> [ ,...n ] )
}
[ ; ]
<object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
}
<rebuild_index_option > ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| STATISTICS_INCREMENTAL = { ON | OFF }
| ONLINE = {
ON [ (
WAIT_AT_LOW_PRIORITY ( MAX_DURATION = <time> [ MINUTES ] ,
ABORT_AFTER_WAIT = { NONE | SELF | BLOCKERS } )
) ]
| OFF }
| ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| COMPRESSION_DELAY = {0 | delay [Minutes]}
| DATA_COMPRESSION = { NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( {<partition_number> [ TO <partition_number>] } [ , ...n ] ) ]
}
<single_partition_rebuild_index_option> ::=
{
SORT_IN_TEMPDB = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE} }
| ONLINE = { ON [ ( <low_priority_lock_wait> ) ] | OFF }
}
<reorganize_option>::=
{
LOB_COMPACTION = { ON | OFF }
| COMPRESS_ALL_ROW_GROUPS = { ON | OFF}
}
<set_index_option>::=
{
ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| COMPRESSION_DELAY= {0 | delay [Minutes]}
}
<low_priority_lock_wait>::=
{
WAIT_AT_LOW_PRIORITY ( MAX_DURATION = <time> [ MINUTES ] ,
ABORT_AFTER_WAIT = { NONE | SELF | BLOCKERS } )
}语法太复杂,我们简单举一两个例子:
alter index idx_ind_indtext on dbo.FragementIndexTable
rebuild ;
alter index idx_ind_indtext on dbo.FragementIndexTable
reorganize ;接下来我们尝试写段脚本,来监控索引的碎片情况,并根据碎片率来确定索引碎片整理计划:
sys.dm_db_index_physical_stats (
{ database_id | NULL | 0 | DEFAULT }
, { object_id | NULL | 0 | DEFAULT }
, { index_id | NULL | 0 | -1 | DEFAULT }
, { partition_number | NULL | 0 | DEFAULT }
, { mode | NULL | DEFAULT }
)主要用到的函数就是这个DMF,sys.dm_db_index_physical_stats. 我们已经接触到两个sys.dm_db_***的DMF了,另一个就是sys.dm_db_database_page_allocations. 开始写脚本之前,我们几个点是要注意一下的,脚本的功能就应该考虑到这些问题:
1 index_id 可以的选值是0(代表堆表),1代表clustered index, 2及以上是常规索引。所以我们要知道我们选择以0, 1 为参数的时候,会不会有结果,结果是不是和常规索引一样?
2 partition_number我们该怎么处理? Index建立在partition的表上时,索引是不是自动partition? 当一张表有partition index的时候,我们的脚本是不是要考虑到? 我们把partition参数设置为null, 0的时候,针对有partition的索引,结果是什么? Default(Null)的作用是显示所有的partition.
3 mode的处理? Mode这里的可选值有default, null, limited,sampled,detailed. Default(Null)对应的可选值是limited. 为了获取详细的统计信息,我们选detailed.
use lenistest4
go
select object_name(inds.object_id) as tableName
, inds.index_id
, isnull(ind.name , object_name(inds.object_id)) as index_name
, inds.partition_number
, inds.index_type_desc
, inds.index_depth
, inds.index_level
, inds.avg_fragmentation_in_percent
, case
when inds.avg_fragmentation_in_percent between 5 and 30 then 'Reorganize'
when inds.avg_fragmentation_in_percent > 30 then 'rebuild'
else 'NoActionRequired'
end as FragmentationResolution
, case
when inds.avg_fragmentation_in_percent between 5 and 30 then 'alter index ' + isnull(ind.name , object_name(inds.object_id)) + ' on ' + schema_name(tb.schema_id)+'.'+tb.name+ ' reorganize'
when inds.avg_fragmentation_in_percent > 30 then 'alter index ' + isnull(ind.name , object_name(inds.object_id)) + ' on ' + schema_name(tb.schema_id)+'.'+tb.name+ ' rebuild'
else 'NoActionRequired'
end as FragmentationCommandText
, inds.fragment_count
, inds.avg_fragment_size_in_pages
, inds.page_count
, inds.avg_page_space_used_in_percent
, inds.record_count
, inds.ghost_record_count
, inds.min_record_size_in_bytes
, inds.max_record_size_in_bytes
, inds.avg_record_size_in_bytes
, inds.compressed_page_count
from sys.indexes ind
cross apply (select * from sys.dm_db_index_physical_stats(db_id(N'lenistest4'), ind.object_id, ind.index_id, null, 'detailed') ) inds
inner join sys.tables tb on ind.object_id = tb.object_id
order by inds.object_id, inds.index_id看到这篇文章 Visualizing index Fragmentation (Visualizing Index Fragmenation) ,使得我想起我对碎片 Fragmentation的理解有些偏差。 我的理解就是一个数据页里面的数据之间有一些存储空间未被利用,当很多这样存储空间的时候,Fragmentation就越大,给scan ,seek造成不必要的寻址开销。但是物理读的时候,是一页一页读取数据页的,所以一个页中的空闲空间,应该造成不了影响。 只能从更大的空间单位来上讲碎片。当连续的index key对应的数据页,假如说有30%是分配到了其他的extent,那么去读数据页的时候,就不能执行顺序读了,只能随机的读取,这样才算增加读取开销;又比如我们有6个page, page 1,2,3,4,5,6. 这6个page里存储的索引值,是从小到大依次存储在这些page里面,并且page也是从小到大依次存储在extent里面。这个时候碎片率就是0。当执行完大量的数据修改,删除之后,我们又增加了6个page, page 7,8,9,10,11,12。 但是这里面的数据值发生了改变, page7存储的数据值,范围在page 1和page 2之间了,所以page 1的next page id就指向page 7了,Page7 的next page id指向 page 2了; 同样的,page8 存储的数据值,范围在page 2和page 3之间了,所以page 2的next page id就指向page 8了,Page8 的next page id指向 page 3了;大概的page存储顺序就变成了page 1,7,2,8,3,9,4,10,5,11,6,12. 这样读取page 1,2,3,4,5,6的时候,就变成了随机读。这种情况才叫碎片, Fragmentation. Page 7,8,9等的产生也好理解,page 1 -6 都已经分配好了,那么当要新增加一些数据值又恰好这些数据值的范围比page 1里面存储的最大值要大,而比page 2里面存储的最小值要小,那么只能新建一个page,page 7来存储这些值,并且page 1的next page id就指向page 7了。
当然我所理解的碎片也是存在的,如果数据页有太多的空闲空间没有被有效利用,那么回造成很多的物理数据页被创建,导致数据页的数据量增加,读取开销也增加。如果要解决这种问题,rebuild, reorganize, recreate数据页都可以解决。
这篇博文可以很好的总结我说的这两种碎片情况:Stop Worrying About SQL Server Index Fragmentation by Brent Ozar
文章中提到很有意思的一个测试,Toshiba对顺序读与随机读的速度作了一个评估报告,证明顺序读能达到200MB/sec, 而随机读只能达到2MB/Sec. Take this recent Toshiba enterprise drive review by StorageReview – it gets around 200MB/sec for large sequential reads, but under 2MB/sec for random reads.
从SQL Server 2012开始,加入了一些新的存储结构,比方说ColumnStored Index, Memory-Optimized table. 接下来我们谈谈这两个新存储结构。
列式存储索引, columnstored index. 常规的行式索引是怎么存数据的呢,索引值加上堆表的RID( data file id + data page id + Row Offset ),或者聚集索引表的键值。
先用DBCC PAGE来看行式索引存储堆表RID的情况 :
dbcc traceon(3604)
dbcc page(lenistest4, 1,499,3)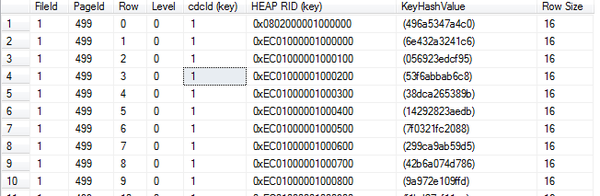
Heap RID(key)这个栏位,显示的就是堆表(heap table)的RID 。
然后再看下聚集索引表的索引数据页,是怎么存储索引键值的:
dbcc traceon(3604)
dbcc page(lenistest4, 1,2804,3)
这里的Ind(Key), IndText(Key)就是聚集索引表的主键值 。
可以确定的是,两种索引都采用了hash算法来存储键值与索引表的对应关系。
所以列式索引是怎么存储这种影射关系的呢? 存储结构,数据页存储内容,查询列式索引的元数据信息,创建列式索引等一系列主题都将讨论一下. 以下讨论均来自于这篇外文,加上自己的一些理解,如果需要看外文的,可以点这里:
Columnstore Indexes in SQL Server 2012
据说列式索引采用了独特的压缩方式。这种压缩方式叫xVelocity(前称VertiPaq),专门用于 Analysis Service和Power Pivot的数据存储,现将其移到relational database storage engine中来。
1) ColumnStore index data Structure: 从物理存储上来说,ColumnStore index 在page之上加了一层抽象,segment, segment在这里的概念是一个LOB(Large object), 与行索引不同,查询引擎读取columnstore index的时候以segment位单位读取而不是以page来读取。
一个segment就是一列索引的字段。如果我们新创建一个包含2列的ColumnStore Index,就会有两个segment。每个segment会有一个存储的上限,每一个segment都可以包含很多数据页(data page), 至多包含100万条数据,所以一旦超出这个数目,就需要重新建立一个segment,但是还隶属于这个字段。数据从磁盘抽取到内存,是抽取整个字段所有的segment, 这里就会有个疑问,全量抽取对于内存来说也是压力,所以不知道这里是怎么寻址的?
举个例子来讲一下:
create nonclustered columnstore index colind_objcntval on dbo.dimstatisticscounters(object_name,counter_name,cntr_value)
select object_name,counter_name,cntr_value from dbo.dimstatisticscounters where cntr_value > 1000
select object_name,counter_name,cntr_value from dbo.dimstatisticscounters with(index(1))
where cntr_value > 1000
第一个执行计划直接走columnstore index, 可以看到执行计划是先读取了columnstore index,然后做过滤(Filter)。可以猜想第一个执行计划是先读取整个columnstore index也就是有多少segments就先读取多少,这样来讲,如果很多segments,就对内存压力很大了。应该查询引擎有些优化?
一个columnstore index的所有segment,按照表里数据的次序从上到下一一对应排序。也就是说,如果我们新建一个2列的columnstore index,第一个segment的第一个行,和第二个segment的第一个行,组成了堆表里面的第一行。如果有相同索引值的多行,那么这些行是怎么对应到相应的表行的? 存储了RID还是聚集表的索引值?
dbcc traceon(3604)
dbcc ind(lenistest3,'dbo.dimstatisticscounters',6)
dbcc ind(lenistest3,'dbo.dimstatisticscounters',1)
上图,表 dimstatisticscounters 有一个聚集索引,有一个columnstore索引。IAM_CHAIN_TYPE里显示的是LOB Data也就是对应了columnstore index。我们再看下这些columnstore page里面存了些什么:
dbcc page(lenistest3,3,2850226,1)PAGE: (3:2850226)
BUFFER:
BUF @0x0000000488731D40
bpage = 0x00000001FF108000 bhash = 0x0000000000000000 bpageno = (3:2850226)
bdbid = 27 breferences = 0 bcputicks = 0
bsampleCount = 0 bUse1 = 37028 bstat = 0x10b
blog = 0xb212121c bnext = 0x0000000000000000
PAGE HEADER:
Page @0x00000001FF108000
m_pageId = (3:2850226) m_headerVersion = 1 m_type = 3
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0xa000
m_objId (AllocUnitId.idObj) = 223 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594052542464
Metadata: PartitionId = 72057594046578688 Metadata: IndexId = 6
Metadata: ObjectId = 293576084 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 0 m_slotCnt = 1 m_freeCnt = 26
m_freeData = 8164 m_reservedCnt = 0 m_lsn = (92236:1544:257)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (3:2556160) = ALLOCATED SGAM (3:2556161) = NOT ALLOCATED
PFS (3:2846976) = 0x44 ALLOCATED 100_PCT_FULL DIFF (3:2556166) = CHANGED
ML (3:2556167) = NOT MIN_LOGGED
DATA:
Slot 0, Offset 0x60, Length 8068, DumpStyle BYTE
Record Type = BLOB_FRAGMENT Record Attributes = VERSIONING_INFORecord Size = 8068
Memory Dump @0x000000001D7FA060
0000000000000000: 4800761f 00007217 00000000 03000000 00000000 H.v…r………….
0000000000000014: 0000630c dfaacd1a 9cce72fa f395a9a6 a6d300b7 ..c.ߪÍ.œÎrú󕩦¦Ó.·
0000000000000028: 00000000 00000000 00000000 8e3167d9 32cab15e …………Ž1gÙ2ʱ^
000000000000003C: 720e09e3 9ed2c0b9 00000000 00000000 00000000 r. ãžÒÀ¹…………
0000000000000050: 18031adf 65e5e1e8 6b59746e f6ad265a 00000000 …ßeåáèkYtnö&Z….
0000000000000064: 00000000 00000000 6300531d 7ebee1d0 6b594e69 ……..c.S.~¾áÐkYNi
0000000000000078: d3f9005b 00000000 00000000 00000000 1803feec Óù.[…………..þì
有5个地方挺有意思,可以看下:
M_slotCnt = 1 , 整个page就一个记录;
PFS (3:2846976) = 0x44 ALLOCATED 100_PCT_FULL , 全满. PFS: Percent Free Space
Slot 0, Offset 0x60, Length 8068 一个slot 记录, 总长 8068 bytes
Record Type = BLOB_FRAGMENT, binary large object, 二进制大文件
每行显示的内容都是二进制乱码
是不是有可能columnstore index也可以和表结构存储在一起? 根据MSDN的描述,columnstore index也是可以和表结构聚集存储在一起的,但是并不支持同一个表上创建多个columnstore index语法如下:
Create a clustered columnstore index on disk-based table.
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON [database_name. [schema_name ] . | schema_name . ] table_name
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
[ ; ]Create a non-clustered columnstore index on a disk-based table.
CREATE [NONCLUSTERED] COLUMNSTORE INDEX index_name
ON [database_name. [schema_name ] . | schema_name . ] table_name
( column [ ,...n ] )
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
[ WHERE <filter_expression> [ AND <filter_expression> ] ]
[ ; ]<with_option> ::=
DROP_EXISTING = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| COMPRESSION_DELAY = { 0 | delay [ Minutes ] }
| DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( { partition_number_expression | range } [ ,...n ] ) ]
<on_option>::=
partition_scheme_name ( column_name )
| filegroup_name
| "default"
<filter_expression> ::=
column_name IN ( constant [ ,...n ]
| column_name { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< } constant如果尝试创建多个columnstore index,就会报错:
Msg 35339, Level 16, State 1, Line 18
Multiple nonclustered columnstore indexes are not supported.
2)按照列来存储,有3个好处:一来存储的都是同质化的(homogenous)数据,压缩采用的函数比较高效;二来针对重复值比较多的列,可以采用 dictionary的方式存储,key部分存储在索引上,value部分放在dictionary 里面,省下很多空间,查询产生的IO就更小了;再一个因为每一个segment存储了单一的值,减少了一些大字段的占用空间,很多预读的数据页就极大减少了不必要字段,IO更有效率。当然也不是所有的列都会以dictionary的方式存储,但是字符型数据都是的,并且还有可能有第二字典,有点类似hash方法。
3)Batch Mode Processing:SQL Server 有三种处理数据集的方式, 一种是 row-based, 一行一行处理,一种是 Batch mode, 一个batch包含了1000条数据,每一个列在这个batch里面被称之为vector,基于vector的处理方法,叫做batch processing。当然我们可以把row-based, batch mode合并起来应用,这是第三种方式。
针对 colunmstore index,借用Robert Sheldon的一张图,可以获得清晰的存储认识:

每一个ROW GROUP都存储了相同数目的行,并且都按相同的行位置排列。针对上面的列式索引,Make + Model + Color, 假设表里第一行的数据是, Audi + S + Red, 那么 Make Segment第一行存储的是Audi, Model Segment第一行存储的就是S,Color Segment第一行存储的就是Red。
如果我们对一张堆表做全表扫描,可以看到I/O Cost的标示

我们对一张表加 columnstore index, 可以看到默认的,执行计划就选择了columnstore index。
create nonclustered columnstore index idx_colstr_sts
on siebeldbTableSchema(object_id,column_id,column_name)
go
Estimated Operator Cost 从1.46 降到了0.27, 而Estimated I/O Cost 从1.25降到了0.06。 I/O这种重型处理一般在分析系统,BI或者数据仓库中大量存在,在这类系统中,维度相对来说相对固定,唯一值就比较固定,所以针对fact table或者大数据量的dimension table会比较适用。
上面我们是通过GUI来查看查询的运行时统计信息的,除此之外,我们还可以使用set statistics IO/TIME on来获取运行时的查询开销: 在每一次执行查询之前,最好清空数据库的缓存与编译过的执行计划缓存:
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHEset statistics io on
select object_name,counter_name,cntr_value from dimstatisticscounters
(2044 row(s) affected)
Table 'dimstatisticscounters'. Scan count 1, logical reads 116, physical reads 1, read-ahead reads 112, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)create nonclustered columnstore index colind_objcntval on dbo.dimstatisticscounters(object_name,counter_name,cntr_value) ;set statistics io on
select object_name,counter_name,cntr_value from dimstatisticscounters
(2044 row(s) affected)
Table 'dimstatisticscounters'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 31, lob physical reads 0, lob read-ahead reads 10.
(1 row(s) affected)4) columnstore index的维护也有说法,并不是跟行索引一样自动更新的。聚集列式索引,就是与表结构一起存储,当有新数据或者旧数据更新的时候,索引是自动更新的,但是非聚集列式索引,则是只读的。
5) 刚才我们提到有columnstore index优化的问题 , MSDN上有一篇文章,讲到这个columnstore index的调优: SQL Server Columnstore Performance Tuning
我们来尝试着理解,力量来自于理解 - 《黑麋鹿如是说》
Columnstore index的几大特色:
The columnstore index itself stores data in highly compressed format, with each column kept in a separate group of pages. This reduces I/O a lot for most data warehouse queries because many data warehouse fact tables contain 30 or more columns, while a typical query might touch only 5 or 6 columns. Only the columns touched by the query must be read from disk. Only the more frequently accessed columns have to take up space in main memory. The clustered B-tree or heap containing the primary copy of the data is normally used only to build the columnstore, and will typically not be accessed for the large majority of query processing. It’ll be paged out of memory and won’t take main memory resources during normal periods of query processing.
There is a highly efficient, vector-based query execution method called “batch processing” that works with the columnstore index. A “batch” is an object that contains about 1000 rows. Each column within the batch is represented internally as a vector. Batch processing can reduce CPU consumption 7X to 40X compared to the older, row-based query execution methods. Efficient vector-based algorithms allow this by dramatically reducing the CPU overhead of basic filter, expression evaluation, projection, and join operations.
Segment elimination can skip large chunks of data to speed up scans. Each partition in a columnstore indexes is broken into one million row chunks called segments. Each segment has metadata that stores the minimum and maximum value of each column for the segment. The storage engine checks filter conditions against the metadata. If it can detect that no rows will qualify then it skips the entire segment without even reading it from disk.
The storage engine pushes filters down into the scans of data. This eliminates data early during query execution, improving query response time.
5.1 高度压缩: 每一个列都包含很多个segment,这些segment存储了相同数据类型,压缩方法比不同数据类型的算法更加有效。查询的时候只装载需要的列,而不是抓取整个data page里面所有的列,较少了内存在缓存方面的开销。加上压缩和hash,整个columnstore index的page存储的数据量更精简但是更多。
5.2 vector-based(向量处理)模式,也叫batch processing,每1000条数据做一次batch processing。执行计划中 ,我们检查Actual Execution Mode,此时可能的值应该是Row或者Batch,或者Both. 这里我的理解应该是多个column同时做处理,每次1000条。
5.3 筛选segment,由于segment会记录自己管辖的数据最小最大值,所以不满足筛选条件的segment会直接过滤掉,这就回答了我上面的疑问,不相关的segment不会装载到内存里面去做缓存,也就是不读取全部的segment,那么上面的执行计划似乎是有误解的,先读取segment再做Filter.

这里就很难理解columnstore index scan 到Filter的过程了。
5.4 columnstore index 的最佳实践
5.4.1 在超大表上建立columnstore index, 一次全表扫描就花2ms的查询,建立columnstore index是多余的(当然这是极端例子)。最适合建立columnstore index的场景,就是在数据仓库中超大体量的事实表(Fact Table), 这类表通常包含了几十个甚至成千上万个维度,并且有很多的measures. 如果维度记录也达到了百万千万,columnstore index也是有利于提高性能的;
5.4.2 把表的所有列都放在columnstore index里面,保证这些所有的查询都能利用到columnstore index. 这样存储就扩量了,所以在存储吃紧的情况下,适当建立columnstore index了。举个例子:
create nonclustered columnstore index colind_objcntval on dbo.dimstatisticscounters(object_name,counter_name,cntr_value)
select object_name,counter_name,cntr_value from dbo.dimstatisticscounters where cntr_value > 1000 or instance_name = 'Buffer Pool'
select object_name,counter_name,instance_name,cntr_value from dbo.dimstatisticscounters where cntr_value > 1000我们创建了columnstore index,包含了其中的三个column, object_name, counter_name, cntr_value,当我们的查询用到了其它的列,columnstore index就失效了。
5.4.3 Structure your queries as star joins with grouping and aggregation as much as possible. Avoid joining pairs of large tables. Join a single large fact table to one or more smaller dimensions using standard inner joins. Use a dimensional modeling approach for your data as much as possible to allow you to structure your queries this way.
这段话的意思就是针对数据仓库来讲了,数据模型要按照维度模型中的星型模型(Star Modeling)来实现,这样在我们的查询中间就是一张事实表,join的都是各种维度表,这样的grouping或者aggregation就能利用到columnstore index。
5.4.4 最后是所有查询或者数据库管理中都需要注意的部分: 统计信息的及时更新以及查询语句的最优写法。统计信息的维护最佳用法,可以参考这篇文章: Statistics Used by the Query Optimizer in Microsoft SQL Server 2008
5.5 columnstore index的一些缺陷:在上面的文章中,也提到了一些缺陷
5.5.1 避免在clumnstore index的字段上做查询关联(Join On),也不要做字符串限制,匹配等筛选动作,因为这些判断条件是不会被用在columnstore index scan之前的,这就解释了刚才查询columnstore index的时候,先做scan再做Filter了。
但是貌似也不贴切,因为我们的查询判定条件就是用numeric数据类型,但是依然有Filter这么个操作。 如:
select object_name,counter_name,cntr_value from dbo.dimstatisticscounters d
where cntr_value = 100.025.5.2 避免在columnstore index的索引字段上使用outer join.这里倒不是不走columnstore index的问题而是不会做batch processing。
5.5.3 避免在columnstore index上使用NOT IN 。NOT IN 会使用 anti_semi_join导致将batch processing转换成row-based-processing。那么IN呢?
5.5.4 避免使用Union All.同样也是batch processing的限制。
5.6 上面提到了一些columnstore index的缺陷,那么有哪些措施可以帮助我们最大化columnstore index的应用,避免这些缺陷呢?
Ensuring Use of the Fast Batch Mode of Query Execution
Parallelism (DOP >= 2) is Required to Get Batch Processing
Use Outer Join and Still Get the Benefit of Batch Processing
Work Around Inability to get Batch Processing with IN and EXISTS
Perform NOT IN and Still Get the Benefit of Batch Processing
Perform UNION ALL and Still Get the Benefit of Batch Processing
Perform Scalar Aggregates and Still get the Benefit of Batch Processing
Maintaining Batch Processing with Multiple Aggregates Including one or More DISTINCT Aggregates
Using HASH JOIN hint to avoid nested loop join and force batch processing
Physical Database Design, Loading, and Index Management
Adding Data Using a Drop-and-Rebuild Approach
Adding Data Using Partition Switching
Trickle Loading with Columnstore Indexes
Avoid Using Nonclustered B-tree Indexes
Changing Your Application to Eliminate Unsupported Data Types
Achieving Fast Parallel Columnstore Index Builds
Maximizing the Benefits of Segment Elimination
Understanding Segment Elimination
Verifying Columnstore Segment Elimination
Ensuring Your Data is Sorted or Nearly Sorted by Date to Benefit from Date Range Elimination
Multi-Dimensional Clustering to Maximize the Benefit of Segment Elimination
Additional Tuning Considerations
Work Around Performance Issues for Columnstores Related to Strings
Force Use or Non-Use of a Columnstore Index
Workarounds for Predicates that Don’t Get Pushed Down to Columnstore Scan (Including OR)
Using Statistics with Columnstore Indexes
上面从MSDN上摘录了这些keypoints,接下来我们一个一个过:
1 使用option(maxdop N) :上面在讨论columnstore index缺陷的时候,注意点最多的就着重在Batch Processing上,我们有这些方法可以保证查询跑了batch processing.在讨论具体方法之前,首先要明白batch processing的概念以及表现形式:
我们先看下没有columnstore index的时候,执行一个聚合操作:
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 2 )
(15 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'fctdbsize'. Scan count 3, logical reads 489844, physical reads 0, read-ahead reads 344710, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)set statistics io on
set statistics time on
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 6 )
(15 row(s) affected)Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'fctdbsize'. Scan count 5, logical reads 489844, physical reads 2877, read-ahead reads 339983, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 75784 ms, elapsed time = 28316 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.set statistics io on
set statistics time on
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 10 )
(15 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'fctdbsize'. Scan count 5, logical reads 489844, physical reads 0, read-ahead reads 94794, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 62447 ms, elapsed time = 19230 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.这里可见,option(maxdop N) 随着N的增加我们的执行时间也相应减少了很多。
我们创建一个columnstore index,再看看查询的性能:
create nonclustered columnstore index ind_colstore on dbo.fctdbsize (record_date,type_desc,size) ;
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc注意我们在这里不加option(maxdop N) .
(15 row(s) affected)
Table 'fctdbsize'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 4066, lob physical reads 0, lob read-ahead reads 1856.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 33167 ms, elapsed time = 9765 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.时间上减少10秒哦。再加上option(maxdop 10):
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 10 )
(15 row(s) affected)Table 'fctdbsize'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 4054, lob physical reads 0, lob read-ahead reads 860.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 32854 ms, elapsed time = 9666 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.其实也一样,时间上并没有比没有option(maxdop 10)快多少。但是这两个查询,都用到了BATCH Mode. 注意Actual Execution Mode : Batch

再与行索引或者堆表扫描开销对比一下:
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize with(index(0))
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 20 )
(15 row(s) affected)Table 'fctdbsize'. Scan count 5, logical reads 489844, physical reads 0, read-ahead reads 204562, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 60356 ms, elapsed time = 20298 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
这里很明显的时间长了2倍 ,Actual Execution Mode也变为Row了。
很有意思的是option(maxdop 1)会影响Execution Mode的选择:
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 1 )
(15 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'fctdbsize'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 2405, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 60061 ms, elapsed time = 61101 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.虽然走了columnstore index,但是没有用到batch execution model导致时间增加了50秒。
既然option(maxdop N)会影响execution model,那么什么叫maxdop? MaxDop, maximum deep of parallelism . 微软的这篇文章解释的好,SQL Server 他是自动监测我们的查询计划可以动用多少core cpu来执行的,除非我们设置了option(maxdop 1)这样就限制了只用一个CPU,很显然我们不会么! 我们只会设置option(maxdop 0)来让查询优化引擎自动去选择,当然是有多少可用的core就用多少。详细的解释看这里:
max degree of parallelism Option
1.1 可以设置maxdop的方法: SQL Server版本以及服务器的CPU个数都对maxdop有直接的影响,虽然如此我们还是可以通过参数来配置maxdop的数值:
1.1.1 通过sp_configure来配置,maxdop属于高级用法,所以先要开启advanced options选项:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
sp_configure 'max degree of parallelism', 8;
GO
RECONFIGURE WITH OVERRIDE;
GO1.1.2 option(MAXDOP N): 最常用的查询选项参数,N=0,就是自动选择,N=1,不启动多线程并行, N>1启动多个线程来并行执行查询
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, type_desc, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),type_desc
option(maxdop 10 )1.2 maxdop影响到的范围,包含查询,index操作还有DBCC命令
1.2.1 index的maxdop用法:
IF EXISTS (SELECT name FROM sys.indexes
WHERE name = N'IX_ProductVendor_VendorID')
DROP INDEX IX_ProductVendor_VendorID ON Purchasing.ProductVendor;
GO
CREATE INDEX IX_ProductVendor_VendorID
ON Purchasing.ProductVendor (BusinessEntityID)
WITH (MAXDOP=8);
GO可以影响到的index操作:
CREATE INDEX
ALTER INDEX REBUILD
DROP INDEX (This applies to clustered indexes only.)
ALTER TABLE ADD (index) CONSTRAINT
- ALTER TABLE DROP (clustered index) CONSTRAINT
1.2.2 DBCC 命令的maxdop用法:
DBCC CHECKTABLE, DBCC CHECKDB, and DBCC CHECKFILEGROUP
可以用Trace Flag 2528来禁止DBCC使用parallelism执行。
DBCC CHECKTABLE
(
table_name | view_name
[ , { NOINDEX | index_id }
|, { REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD }
]
)
[ WITH
{ ALL_ERRORMSGS ]
[ , EXTENDED_LOGICAL_CHECKS ]
[ , NO_INFOMSGS ]
[ , TABLOCK ]
[ , ESTIMATEONLY ]
[ , { PHYSICAL_ONLY | DATA_PURITY } ]
[ , MAXDOP = number_of_processors ]
}
] dbcc checktable ('dbo.dimstatisticscounters')SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
DBCC results for 'dimstatisticscounters'.
There are 2044 rows in 114 pages for object "dimstatisticscounters".
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
SQL Server Execution Times:
CPU time = 983 ms, elapsed time = 3139 ms.貌似DBCC CHECKTABLE, DBCC CHECKDB, DBCC CHECKFILEGROUP从SQL SERVER 2016版本开始才支持MAXDOP.
2 在执行 outer join的时候,仍然可以保持BATCH Execution Model.
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, name, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),name
option(maxdop 1 )
(25 row(s) affected)Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'fctdbsize'. Scan count 1, logical reads 489844, physical reads 2518, read-ahead reads 270871, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 69951 ms, elapsed time = 83528 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
上面的查询并没有用到columnstore index,就是平常的一条查询,只不过限制了maxdop=1,结果时间用了83秒. Execution Model就是Row
select cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar) as monthx, name, sum(size ) as size
from fctdbsize
group by cast(datepart(year,record_date) as varchar) + cast(datepart(month,record_date) as varchar),name
option(maxdop 20 )
(25 row(s) affected)Table 'fctdbsize'. Scan count 5, logical reads 489844, physical reads 3842, read-ahead reads 429322, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 67299 ms, elapsed time = 21836 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.结果我们设置了maxdop = 20的时候,时间便为21秒。 并且execution model也是采用了batch 模型:

可见,对于非列式索引,SQL SERVER也会有BATCH EXECUTION MODEL. 只不过是由maxdop = 1 限制了execution model为row.
假设我们有这么例子, dbo.fctdbsize上有一个columnstore index,索引列包含record_date,type_desc,size, 表 dbo.calendar,有字段 current_date, current_year,current_month,processingmonth,没有任何索引 。
select c.processingmonth, f.type_desc, sum(f.size) as size
from dbo.fctdbsize f
left join dbo.calendar c on f.record_date = c.[current_date]
group by c.processingmonth, f.type_desc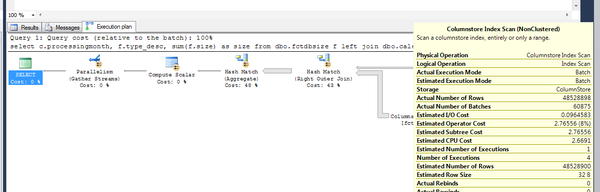
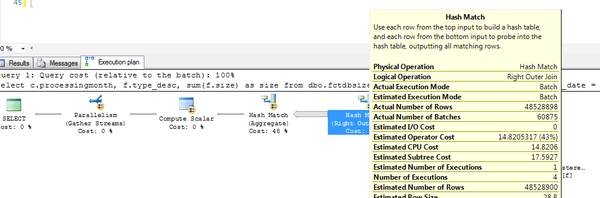
我们特意用了left join,但是在hash match上用的还是batch processing .
插播一条很有意思的消息,SQL Server历来都有codename来代表一个版本的习惯:
· 1993 – SQL Server 4.21 for Windows NT
· 1995 – SQL Server 6.0, codenamed SQL95
· 1996 – SQL Server 6.5, codenamed Hydra
· 1999 – SQL Server 7.0, codenamed Sphinx
· 1999 – SQL Server 7.0 OLAP, codenamed Plato
· 2000 – SQL Server 2000 32-bit, codenamed Shiloh (version 8.0)
· 2003 – SQL Server 2000 64-bit, codenamed Liberty
· 2005 – SQL Server 2005, codenamed Yukon (version 9.0)
· 2008 – SQL Server 2008, codenamed Katmai (version 10.0)
· 2010 – SQL Server 2008 R2, Codenamed Kilimanjaro (aka KJ)
· 2011 – SQL Server 2012, Codenamed Denali

回顾下上面的例子, dbo.fctdbsize上有一个columnstore index,索引列包含record_date,type_desc,size, 表 dbo.calendar,有字段 current_date, current_year,current_month,processingmonth,没有任何索引 。
select c.processingmonth, sum(f.size) as size
from dbo.fctdbsize f
inner join dbo.calendar c on convert(date,f.record_date) = c.[current_date]
group by c.processingmonth
order by sum(f.size) desc
这里我们在join条件上,加一个函数,居然也走了columnstore index。终于打破加函数不走索引的魔咒了。当然会有些性能开销。
select c.processingmonth, sum(f.size) as size
from dbo.fctdbsize f
left join dbo.calendar c on f.record_date = c.[current_date]
group by c.processingmonth
order by sum(f.size) desc
select c.processingmonth, sum(f.size) as size
from dbo.fctdbsize f
right join dbo.calendar c on f.record_date = c.[current_date]
group by c.processingmonth
order by sum(f.size) descdbo.fctdbsize数据量在千万级别, dbo.calendar数据量在万级别,但是都走了columnstore index 并且execution model都是batch. 所以上面的文章中提到的outer join不支持 batch execution model,在SQL SERVER 2014中已经不存在了 。 原文中是这样说道 Outer joins are not supported in batch mode in SQL Server Denali.
3 替代 IN和Exists不能获取batch processing的方法:
select convert(date,record_date) as dt, sum(size) as size
from dbo.fctdbsize
where convert(date,record_date) in (select [current_date] from dbo.calendar )
group by convert(date,record_date)
order by sum(size) desc
select convert(date,record_date) as dt, sum(size) as size
from dbo.fctdbsize f
where exists (select [current_date] from dbo.calendar
where [current_date] = convert(date,f.record_date) )
group by convert(date,record_date)
order by sum(size) desc同样, 我们没有重现在SQL SERVER 2012中, IN, Exists子句不支持batch processing的案例
4 替代NOT IN, NOT EXISTS不能获取batch processing的方法:
select convert(date,record_date) as dt, sum(size) as size
from dbo.fctdbsize
where convert(date,record_date) not in (select [current_date] from dbo.calendar )
group by convert(date,record_date)
order by sum(size) desc
select convert(date,record_date) as dt, sum(size) as size
from dbo.fctdbsize f
where not exists (select [current_date] from dbo.calendar
where [current_date] = convert(date,f.record_date) )
group by convert(date,record_date)
order by sum(size) desc事实上,SQL SERVER 2014中也是支持 batch execution model了。
5 union all不能获取batch processing的方法:
select dt,count(*) as rs from (
select convert(date,record_date) as dt
from dbo.fctdbsize
union all
select [current_date] as dt
from dbo.calendar
)tmp
group by dt似乎也不能重现
6 数据库设计,装载与索引管理
6.1 更新columnstore index的方法: 分两种情况, 一是聚集columnstore index(clustered columnstore index), 这类索引据说表都不能更新? 还是表既是索引也是表本身? 二是非聚集clumnstore index(non-clustered columnstore index). 这类索引在数据更新的时候不能被更新,只能通过drop-and-rebuild方法来更新。事实证明阿,只要有columnstore index存在的时候,表和索引都不能被更新: (但是可以交换分区,方法下面提到)
insert into dbo.fctdbsize (record_date,type_desc,name,size,size_mb,size_gb,x_flag )
Msg 35330, Level 15, State 1, Line 79INSERT statement failed because data cannot be updated in a table that
has a nonclustered columnstore index. Consider disabling the
columnstore index before issuing the INSERT statement, and then
rebuilding the columnstore index after INSERT has completed.
当创建clustered columnstore index的时候,不需要指定列名,指定了也会抱错:
create clustered columnstore index idx_cls on dbo.dimstatisticscounters
(object_name,counter_name,instance_name,cntr_value,cntr_type,row_id,par_row_id);Msg 35335, Level 15, State 1, Line 12 CREATE INDEX statement failed
because specifying a key list is not allowed when creating a clustered
columnstore index. Create the clustered columnstore index without
specifying a key list.
解决表上已经有聚集主键存在的情况,如何丢弃主键建立聚集columnstore index.
6.2 如何在columnstore index table上无缝添加数据? 使用partition switching.
说交换分区,我们还是要回顾下交换分区的用法:
交换分区的条件:
1) 在交换分区之前,两张分区表是不是应该有限制? 第二张表是不是有和第一张表一样的分区结构? 如果第一张表有主键索引,有聚集索引,那么第二张表是不是也应该有? 下面我们会用具体的例子来看下交换分区的执行过程,具体的交换分区的条件可以看这篇文章:
Transferring Data Efficiently by Using Partition Switching
General Requirements for Switching Partitions
When a partition is transferred, the data is not physically moved; only the metadata about the location of the data changes. Before you can switch partitions, several general requirements must be met:
· Both tables must exist before the SWITCH operation. The table from which the partition is being moved (the source table) and the table that is receiving the partition (the target table) must exist in the database before you perform the switch operation.
· The receiving partition must exist and it must be empty. Whether you are adding a table as a partition to an already existing partitioned table, or moving a partition from one partitioned table to another, the partition that receives the new partition must exist and it must be an empty partition.
· The receiving nonpartitioned table must exist and it must be empty.If you are reassigning a partition to form one nonpartitioned table, the table that receives the new partition must exist and it must be an empty nonpartitioned table.
· Partitions must be on the same column.If you are switching a partition from one partitioned table to another, both tables must be partitioned on the same column.
· Source and target tables must share the same filegroup.The source and the target table of the ALTER TABLE…SWITCH statement must reside in the same filegroup, and their large-value columns must be stored in the same filegroup. Any corresponding indexes, index partitions, or indexed view partitions must also reside in the same filegroup. However, the filegroup can be different from that of the corresponding tables or other corresponding indexes.
尝试着翻译下:
- 交换分区的两个表必须都事先存在;
- 接收分区的表必须有分区定义存在而且分区必须是空的;
- 如果我们要把分区表的数据全部移动到一张分区表里面去,这张表必须存在也必须是空的;
- 分区字段必须相同;
- 原表与目标表必须在同一个filegroup里面
2) 交换分区之后,第一张表的分区结构信息是不是已经被收回,并且没有占任何存储空间了? 如果表结构信息被破坏,那么分区再转换回来的时候,是不是需要重新建立表分区信息? 这两个问题的答案可以用下面的实验来回答,当分区表所有分区被转移之后,就不占有任何存储空间了,但是保留表结构分区信息
use lenistest3
go
/* swith table partition
1 switch partition on the table that has only one partition , obviously it's a heap table
2 switch partition on the table that has more than one partition
3 switch partition on the table that has more than one partition and also has clustered index
*/
/* monitors
1 table has its partitions swithced over has any storage occupied ?
2 any update can operated on the table which has columnstored index after its partition switched over
*//* SQL Statements syntac
1 partition swith syntax
ALTER TABLE database_name . [ schema_name ] . | schema_name . ] table_name
SWITCH [ PARTITION source_partition_number_expression ]
TO target_table
[ PARTITION target_partition_number_expression ]
[ WITH ( <low_lock_priority_wait> ) ]
2 table storage checking
dbcc traceon(3604)
dbcc ind('lenistest3','dbo.FctSalesMonth_s',0)
*/select distinct
schema_name(t.schema_id) as schemaname
, t.name as tablename
, ind.name as indexname
, p.partition_id
, p.partition_number
, p.rows
from sys.partitions p
inner join sys.tables t on t.object_id = p.object_id
inner join sys.indexes ind on t.object_id = ind.object_id and p.index_id = ind.index_id
where exists ( select ps.object_id,ps.index_id,count(ps.partition_id) as rs from sys.partitions ps
where ps.object_id = p.object_id and ps.index_id = p.index_id
group by ps.object_id, ps.index_id
having count(ps.partition_id) > 1 )
order by 1,2,3,5以上的脚本我们可以用来查看那些表是分区表,随便找一个分区表来做试验。
Alter table dbo.FctSalesMonth
Switch Partition 1 to dbo.FctSalesMonth_s Partition 1Warning: The specified partition 1 for the table
‘lenistest3.dbo.FctSalesMonth_s’ was ignored in ALTER TABLE SWITCH
statement because the table is not partitioned. Msg 4905, Level 16,
State 1, Line 50 ALTER TABLE SWITCH statement failed. The target table
‘lenistest3.dbo.FctSalesMonth_s’ must be empty.
上面的实验,我们新创建了一张空表,dbo.FctSalesMonth_s,结构与dbo.FctSalesMonth一样,但是没有分区,没有建立索引。但是建立这个表的时候,我们往里面插入了一条数据,接着又删除了这条数据。在交换分区的时候,提示报错信息: 表并没有建立分区。所以我们要给dbo.FctSalesMonth_s建立一个新的分区,或者直接把表改为分区表:
CREATE PARTITION FUNCTION [Monthly](datetime)
AS RANGE LEFT FOR VALUES
(N'2016-01-01T00:00:00.000'
, N'2016-02-01T00:00:00.000'
, N'2016-03-01T00:00:00.000'
, N'2016-04-01T00:00:00.000'
, N'2016-05-01T00:00:00.000')
GOCREATE PARTITION SCHEME [MonthlySch]
AS PARTITION [Monthly]
TO ([PRIMARY]
, [PRIMARY]
, [PRIMARY]
, [PRIMARY]
, [PRIMARY]
, [PRIMARY]
, [PRIMARY])
GO上面的脚本用来创建partition function 和partition scheme。
CREATE TABLE [dbo].[FctSalesMonth_s](
[OrderMon] [datetime] NULL,
[OrderAmount] [int] NULL
)
on [MonthlySch](OrderMon)
GO上面的脚本用来创建分区表。 然后执行分区转换:
declare @partN int = 1
while @partN <=6
begin
Alter table dbo.FctSalesMonth_s
Switch Partition @partN to dbo.FctSalesMonth Partition @partN
set @partN = @partN + 1 ;
end执行完毕之后,我们重新检测下两表的数据存储,会发现原表partition 1的数据已经转移到目标表了。但是原表的表分区结构都还在。因为数据全部移走了,原表的索引都丢失了,但是新表没有建立索引,索引不存在。总共6个分区,我们把分区全部移动到dbo.FctSalesMonth_s,再看下原表的存储空间.数据都不关联在原表上了,所以数据页上也就没有数据了。Dbcc ind无数据。
dbcc traceon(3604)
dbcc ind('lenistest3','dbo.FctSalesMonth',0)或者从sys.dm_db_database_page_allocations查询:
select * from sys.dm_db_database_page_allocations(db_id(N'lenistest3'),object_id(N'dbo.FctSalesMonth'),0,NULL,'DETAILED')也没有任何数据。
我们接着讨论下primary key与partition的关系,
alter table dbo.FctSalesMonth alter column TransactionId bigint not null ;
alter table dbo.FctSalesMonth add constraint pk_tranid primary key (TransactionId) ;
Msg 1908, Level 16, State 1, Line 51
Column 'OrderMon' is partitioning column of the index 'pk_tranid'. Partition columns for a unique index must be a subset of the index key.
Msg 1750, Level 16, State 0, Line 51
Could not create constraint or index. See previous errors.当primary key与表结构存储在一起的时候,称为聚集索引。这个时候如果有partition同时存在,那么执行partition的列必须包含在primary key中。
alter table dbo.FctSalesMonth add constraint pk_tran_month primary key (OrderMon,TransactionId) ;3)当目标分区表没有聚集索引存在,但是原表有聚集索引存在的时候,交换分区是会失败的:
CREATE TABLE [dbo].[FctSalesMonth_trans_s](
[TransactionId] bigint not null identity(1,1),
[OrderMon] [datetime] not NULL ,
[OrderAmount] [int] NULL
)
on [MonthlySch](OrderMon)
GO
declare @partN int = 1
while @partN <=6
begin
Alter table dbo.FctSalesMonth_trans
Switch Partition @partN to dbo.FctSalesMonth_trans_s Partition @partN
set @partN = @partN + 1 ;
end
Msg 4913, Level 16, State 1, Line 57
ALTER TABLE SWITCH statement failed. The table 'lenistest3.dbo.FctSalesMonth_trans' has clustered index 'pk_tran_month' while the table 'lenistest3.dbo.FctSalesMonth_trans_s' does not have clustered index.这里很明显,由于表dbo.FctSalesMonth_trans_s没有聚集索引存在的时候,交换分区会失败的。当我们加上 primary key的时候,就能顺利交换分区了:
alter table dbo.FctSalesMonth_trans_s add constraint pk_tran_month_s primary key (OrderMon,TransactionId) ;当目标表的交换分区有数据存在,不为空的情况下,交换分区也是会失败的:
declare @partN int = 1
while @partN <=6
begin
Alter table dbo.FctSalesMonth_trans_s
Switch Partition @partN to dbo.FctSalesMonth_trans Partition @partN
set @partN = @partN + 1 ;
end连续执行两边上面的脚本,我们会得到一个错误提示:
Msg 4904, Level 16, State 1, Line 57
ALTER TABLE SWITCH statement failed. The specified partition 1 of target table 'lenistest3.dbo.FctSalesMonth_trans' must be empty.4) 回到我们的问题上来,如果表上有columnstore index,那么怎么通过交换分区来更改数据呢? 整体思路就是先建立一张staging table,表结构,索引结构,分区结构都与目标表的结构信息一模一样,然后往staging table里面灌入数据,在staging table上建立一个columnstore index,这个时候因为数据量小,所以建立索引很快,完成装载数据之后,将这个partition转换到目标分区上。这个应用场景最适合新增加一些数据而不是更改旧数据,或者更新一段时间的旧数据,这样整个partition是都可以转移到一个建立有columnstore index的表分区上的。
insert into dbo.FctSalesMonth_trans_s
/* some ETL Logic to load data into the table */
create nonclustered columnstore index idx_col_tran_s on dbo.FctSalesMonth_trans_s(TransactionId,OrderMon,OrderAmount) ;
/* create columnstore index and make it aligned with the target table columnstore index */
alter table dbo.FctSalesMonth_trans_s
switch partition 1 to dbo.FctSalesMonth_trans partition 1所以当我们可以完全重建一个或者或者partition的时候,就用这种方法直接提高性能。
这里还有一个延伸版的装载columnstore index数据的情况: 当我们建立的columnstore index表上,有聚合字段的时候(分组聚合, sum()), 我们在装载这类表的时候,可以用一个逻辑表,分别收录有columnstore index表的聚合,和增量更新的临时表的聚合:
create table Fact(DateKey int, Measure numeric(18,2));
insert Fact values(20110908, 1);
insert Fact values(20110909, 2);
create nonclustered columnstore index cs on Fact(DateKey,Measure);
-- Find total sales by day
select DateKey, sum(Measure) from Fact group by DateKey;
-- Create table to hold trickle updates
create table FactDelta(DateKey int, Measure numeric(18,2));
-- Add a new row (a "trickle update" to Fact)
insert FactDelta values(20110909, 2); -- Find total sales by day from the fact data consisting of
-- Fact plus FactDelta.
with FirstLevelAgg (DateKey, Measure)
as (select DateKey, sum(Measure) from Fact group by DateKey
UNION ALL
select DateKey, sum(Measure) from FactDelta group by DateKey)
select DateKey, sum(Measure) from FirstLevelAgg group by DateKey上面的案例来自这篇文章,
主要讲的就是在原表有大量数据存在并且作了columnstore index的情况下,我们要加载这张表的增量更新。这表根据DateKey做了聚合计算,我们在做增量更新的时候,将增量的数据放在表结构一样的FactDelta表里面,然后union all原本的聚合,最后将这两部分的总和直接装载到目标表里。 这里可用到的性能提高特性,主要是保证execution mode是batch型的.
6.3 在使用columnstore index的时候,避免使用B-tree 索引,原因有这些:一是columnstore index会包含所有的列;二是B-tree索引可能会影响执行计划的产生;三是B-tree索引会占用过多的磁盘空间,拖慢大数量的表更改.
6.4 有些columnstore index不支持的字段类型必须从columnstore index里面去掉或者换成可以被支持的字段类型。这些不被支持的字段类型有: decimal or numeric with precision > 18, datetimeoffset with precision > 2, binary, varbinary, image, text, ntext, varchar(max), nvarchar(max), cursor, hierarchyid, timestamp, uniqueidentifier, sqlvariant, and xml.
6.5 最优化columnstore index的创建:
columnstore inex在创建的时候会消耗大量的内存,我们可以在一开始就将数据库的min server memory, max server memory都设置为一个大值。这样免去了从操作系统慢慢请求内存分配的消耗,也有利于自动化MAXDOP的时候分配更多的DOP。 当然加大物理内存也是种有效的方法。
精简结构: 只在columnstore index保留最简单常用的字段;表尽可能的拆分。
一种新的方式:(针对我个人而言,这个命令从来没有用过)
ALTER WORKLOAD GROUP [DEFAULT] WITH (REQUEST_MAX_MEMORY_GRANT_PERCENT=X)
ALTER RESOURCE GOVERNOR RECONFIGURE上面的脚本牵扯出来一个新的概念, Resource Governor. 我们可以限制分配给查询请求的CPU, 内存以及IO资源,这种限制功能主要由Resource Governor支持.资源的分配比例,通常有系统自动分配,手工分配,以及运行时占有三种值。
控制Resource Governor参数的命令:
启动resource governor服务:通过SSMS手工开启,或者T-SQL :
ALTER RESOURCE GOVERNOR RECONFIGURE
select * from sys.resource_governor_configuration察看DMV来检查resource governor服务是否启动.
建立一个resource pool :
CREATE RESOURCE POOL poolAdhoc
WITH (MAX_CPU_PERCENT = 20);
GO
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO建立一个workload group,让他使用新建的 poolAdhoc resource pool,这样凡是归类到新建的workload group的请求,都会在poolAdhoc限定的资源下运行:
CREATE WORKLOAD GROUP groupAdhoc
USING poolAdhoc;
GO
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO修改完任何的resource governor参数,都要使用 reconfigure来立即启用这些参数:
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO监控Resource Governor参数运行时刻值的方法:
涉及到resource governor的DMV 有这些:
sys.dm_resource_governor_configuration (Transact-SQL)
sys.dm_resource_governor_resource_pools (Transact-SQL)
sys.dm_resource_governor_external_resource_pool_affinity (Transact-SQL)
sys.dm_resource_governor_resource_pool_volumes (Transact-SQL)
sys.dm_resource_governor_resource_pool_affinity (Transact-SQL)
sys.dm_resource_governor_workload_groups (Transact-SQL)
sys.resource_governor_configuration (Transact-SQL)
sys.resource_governor_resource_pools (Transact-SQL)
sys.resource_governor_external_resource_pools (Transact-SQL)
sys.resource_governor_workload_groups (Transact-SQL)
最优化Resource Governor参数的配置:似乎没有,各种参数只能追求平衡,没有最好。在这段时间可能某一种比例很好,另外一段时间,这比例就不行了。

上面讲的是整个resource governor作用的过程:
- Session 1 请求服务器资源;
- 经过用户自定义的分类函数,将session 1分类到具体的workload group里面
- workload group分配了自己对应的resource pool
- session 1的请求占用resource pool来处理
MSDN上有篇很好的入门文章:
Create and Test a Classifier User-Defined Function
1)创建一个resource pool 和 workload group :
--- Create a resource pool for production processing
--- and set limits.
USE master
GO
CREATE RESOURCE POOL pProductionProcessing
WITH
(
MAX_CPU_PERCENT = 100,
MIN_CPU_PERCENT = 50
)
GO
--- Create a workload group for production processing
--- and configure the relative importance.
CREATE WORKLOAD GROUP gProductionProcessing
WITH
(
IMPORTANCE = MEDIUM
) --- Assign the workload group to the production processing
--- resource pool.
USING pProductionProcessing
GO
--- Create a resource pool for off-hours processing
--- and set limits.
CREATE RESOURCE POOL pOffHoursProcessing
WITH
(
MAX_CPU_PERCENT = 50,
MIN_CPU_PERCENT = 0
)
GO
--- Create a workload group for off-hours processing
--- and configure the relative importance.
CREATE WORKLOAD GROUP gOffHoursProcessing
WITH
(
IMPORTANCE = LOW
) --- Assign the workload group to the off-hours processing
--- resource pool.
USING pOffHoursProcessing
GO 2). 立即使resource governor参数更新有效:
ALTER RESOURCE GOVERNOR RECONFIGURE
GO3). 建一张表来记录workload执行情况:
USE master
GO
CREATE TABLE tblClassificationTimeTable
(
strGroupName sysname not null,
tStartTime time not null,
tEndTime time not null
)
GO
--- Add time values that the classifier will use to
--- determine the workload group for a session.
INSERT into tblClassificationTimeTable VALUES('gProductionProcessing', '6:35 AM', '6:15 PM')
go 4). 新建一个classfier函数,将各种session请求归类到不同的workload group里面:
CREATE FUNCTION fnTimeClassifier()
RETURNS sysname
WITH SCHEMABINDING
AS
BEGIN
DECLARE @strGroup sysname
DECLARE @loginTime time
SET @loginTime = CONVERT(time,GETDATE())
SELECT TOP 1 @strGroup = strGroupName
FROM dbo.tblClassificationTimeTable
WHERE tStartTime <= @loginTime and tEndTime >= @loginTime
IF(@strGroup is not null)
BEGIN
RETURN @strGroup
END
--- Use the default workload group if there is no match
--- on the lookup.
RETURN N'gOffHoursProcessing'
END
GO 5). 通过显式的使用classifier函数,归类具体的session请求到不同的workload group里面
ALTER RESOURCE GOVERNOR with (CLASSIFIER_FUNCTION = dbo.fnTimeClassifier)
ALTER RESOURCE GOVERNOR RECONFIGURE
GO 可以通过DMV来察看,哪些 session, request使用了哪个workload group:
SELECT s.group_id, CAST(g.name as nvarchar(20)), s.session_id, s.login_time, CAST(s.host_name as nvarchar(20)), CAST(s.program_name AS nvarchar(20))
FROM sys.dm_exec_sessions s
INNER JOIN sys.dm_resource_governor_workload_groups g
ON g.group_id = s.group_id
ORDER BY g.name
GO
SELECT r.group_id, g.name, r.status, r.session_id, r.request_id, r.start_time, r.command, r.sql_handle, t.text
FROM sys.dm_exec_requests r
INNER JOIN sys.dm_resource_governor_workload_groups g
ON g.group_id = r.group_id
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
ORDER BY g.name
GO 这里的classifier函数是很有艺术性的,不拘泥于上面写的这种方法,上面的写法是针对某段时间需要执行这种类型的请求来定义的, 我们还可以将各种数据库的请求分开来。方法多样。
6.6 Segment Elimination: 过滤segment。在有columnstore index存在的情况下, 如果数据量够大,会有很多segments建立起来,那么如果全部读取这些segments,时间开销和IO开销很大,性能受影响。有哪些方法可以帮助我们过滤掉这些不会查询到数据的segments? 根据这篇文章所说,sql server会自动帮我们过滤掉这些segments,并且在单表和多表join的情况下,毅然支持segment elimination.
[Understanding Segment Elimination]
(http://social.technet.microsoft.com/wiki/contents/articles/5651.understanding-segment-elimination.aspx)
6.7 验证columnstore index是不是做了segment elimination:
Verifying Columnstore Segment Elimination
You can determine what segments were eliminated during query processing using the sqlserver.column_store_segment_eliminate Xevent. The following script illustrates how to monitor this event:
-- find Xevent for segment elimination
select * from sys.dm_xe_objects x
where x.name like '%segment%'
go
create event session SegmentEliminationSession on server
add event sqlserver.column_store_segment_eliminate
(action (sqlserver.database_id,sqlserver.session_id,sqlserver.sql_text,
sqlserver.plan_handle))
add target package0.asynchronous_file_target
(set filename = 'c:\temp\filename.xel', metadatafile = 'c:\temp\filename.xem')
go alter event session SegmentEliminationSession on server state = start;
go
-- Run a query that causes segment elimination.
-- ... (put your own query here)
-- See event output
select * from sys.fn_xe_file_target_read_file('C:\temp\*.xel', 'C:\temp\metafile.xem', null, null)To get text output messages that show what segments (row groups) were eliminated during query processing, enable trace flag 646 at the global level. The following example illustrates how to do this.
use master
go
drop database SegElimTest
go
create database SegElimTest
go
use SegElimTest
go
create partition function pf(int) as range left for values (100, 200)
go
create partition scheme ps as partition pf all to ([primary])
go
create table t1(a int) on ps(a)
go
insert into t1 values(50)
insert into t1 values (150)
insert into t1 values(250)
go create columnstore index i1 on t1(a)
go
-- Turn on text output that shows when segments (row groups) are eliminated.
dbcc traceon(646, -1)
go
-- Direct trace flag text output to the SQL Server error log file.
dbcc traceon(3605, -1)
go
dbcc tracestatus
go
select * from t1 where a < 140
go The query above causes this output to be displayed in the error log:
Xact (xactid=389339632) skipped row group (dbid=7 rowsetid=72057594039304192 rowgroupid=0)
Trace flag 646 is not documented and is thus not supported, but it can be a useful tool to understand segment elimination.
6.8 为了达到segment elimination, 我们要在columnstore index的列上做好排序:
举个数据仓库事实表的例子,假设我们有一张事实表,表里有个Date字段,如果我们按照Date字段排好序,那么segment存储的最小最大值,在以Date做筛选的时候,就能起到segment elimination的作用了。达到排序的作用,我们可以用两种方法 :
· 建立聚集索引(clustered index), 将Date字段放在索引第一位;
· 建立partition,以Date字段作为分区字段;
本来无序的Date Segments,存储的最大最小值,可能有交叉重复,所以读取的时候往往做不到segment elimination. 现在变得非常明晰,如下图:
这样就可以很容易的选取值范围确定的segments了。当然每个segment存储的数据量必须到位,这样整个读取segment的时候才能发挥最大的page使用率,假设每个segment就1万多条数据,读了10个segment也就10万条,这不是很浪费IO消耗么!
上面讲的是一个列的条件查询,那么如果有两个列或者以上的时候,我们就需要重新考虑方法了:
· Order Clustering : 当两个以上的列需要在查询中作为条件查询,我们可以新建一个列,将这个新建的列映射到其他两个作为条件查询的列上:比如新建一个列ord_dt_rg int, 这个列的数据类型是 integer, 含义是region_id 加上 date的年月。然后依据这个ord_dt_rg建立聚集索引
· Partition Clustering: 和order clustering一样,将两列映射到一个新建的列,然后再新列上建立partition。
以上两种方法的前提都是要数据量够大,能够撑满一个segment 100百万条数据。这样才值得这样用法。
6.9 以字符串为索引列的columnstore index性能折中方法:
详细的原文可以看这里 : Work Around Performance Issues for Columnstores Related to Strings
- 单表字符串的columnstore index的条件查询:
前提我们在单个表上建立了一个columnstore index
select PriceWholesaleCurrency, count(*)
from dbo.Purchase
where PriceWholesaleCurrency like 'E%'
group by PriceWholesaleCurrency当PriceWholesaleCurrency唯一值不是很多,而数据量却很多的时候, 这个查询的like决定了查询性能不会很高。 Group by 在字符串列上的执行效率很高,所以我们可以改写如下:
select T.*
from (select PriceWholesaleCurrency, count(*) c
from dbo.Purchase
group by PriceWholesaleCurrency) as T
where T.PriceWholesaleCurrency like 'E%'如果我们用等于符号( equality checks)就不需要改写了:
select PriceWholesaleCurrency, count(*)
from dbo.Purchase
where PriceWholesaleCurrency = 'USD' or PriceRetailCurrency = 'EUR'
group by PriceWholesaleCurrency*多表查询的时候,以字符串为Join条件,达不到segment elimination的效果。所以尽量都以数值类型的代理键作为join条件,这样在clumnstore index scan的时候就能很好的去掉多余的segment,这个过程也叫做push down to columnstore index.
6.10 columnstore index调优:
* 强迫使用columnstore index和避免使用columnstore index:
这里主要使用 with(index(columnstored_index|B-tree_Index))或者optino(ignore_colunmstore_indx) query hint或者table index hint来达到效果.
*改写查询使得or字句也能将限定Push down到columnstore index scan里面去:
select p.Date, sum(p.PriceRetail) as PriceRetail
from dbo.Purchase p
where p.Date = 20071114 or PriceId = 6
group by p.Date这里or 前后两个限定条件都是基于不同的字段,所以并不能做到segment elimination
select p.Date, sum(p.PriceRetail)
from
(
select p.Date, sum(p.PriceRetail) as PriceRetail
from dbo.Purchase p with (index=ncci)
where p.Date = 20071114 and PriceId <> 6
group by p.Date
UNION ALL
select p.Date, sum(p.PriceRetail) as PriceRetail
from dbo.Purchase p with (index=ncci)
where p.Date <> 20071114 and PriceId = 6
group by p.Date
UNION ALL
select p.Date, sum(p.PriceRetail) as PriceRetail
from dbo.Purchase p with (index=ncci)
where p.Date = 20071114 and PriceId = 6
group by p.Date
) as p
group by p.Date改写完成后,就可以了。 这里or的前后限定是基于不同的字段,如果是相同字段就没有问题。
6.11 columnstore index的统计信息:
Using Statistics with Columnstore Indexes
· 保证所有的统计信息都及时更新,已经算是一条金科玉律了。可以自动创建也可以手工开启时间窗口创建,不赘述了
· Columnstore index的统计信息在索引创建时候不自动创建的。可以用DBCC SHOW_STATISTICS。 Columnstore index的统计信息是用在database克隆时候,用来分析生产环境的性能的。有意思,可以看看这篇文章 : Attach of the Clone (… Databases)
我们对columnstore index的原数据到底是怎么存储最大最小值也有兴趣:
select object_name(p.object_id) as tablename
, ind.name as indexname
, col.name as columnname
, sg.column_id
,sg.segment_id
,sg.row_count
,sg.min_data_id
,sg.max_data_id
from sys.column_store_segments sg
inner join sys.partitions p on sg.partition_id = p.partition_id
inner join sys.indexes ind on ind.index_id = p.index_id and ind.object_id = p.object_id
inner join sys.columns col on col.object_id = ind.object_id and col.column_id = sg.column_id最后总结下各种索引的创建:
1 clustered index :
Create culstered index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create nonunique clustered index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create unique clustered index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;2 nonclustered index:
Create index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create unique index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create nonunique index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create index idx_index_name on tablename( indexed_column_1, indexed_column_2) include (indexed_column_3, indexed_column_4)3 columnstored index
Create clustered columnstore index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;
Create nonclustered columnstore index idx_index_name on tablename( indexed_column_1, indexed_column_2) ;– SQL Server Syntax
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ]
[ ; ] <object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
} <relational_index_option> ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| STATISTICS_INCREMENTAL = { ON | OFF }
| DROP_EXISTING = { ON | OFF }
| ONLINE = { ON | OFF }
| ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE}
[ ON PARTITIONS ( { <partition_number_expression> | <range> }
[ , ...n ] ) ]
} <filter_predicate> ::=
<conjunct> [ AND <conjunct> ]
<conjunct> ::=
<disjunct> | <comparison>
<disjunct> ::=
column_name IN (constant ,...n)
<comparison> ::=
column_name <comparison_op> constant
<comparison_op> ::=
{ IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< }
<range> ::=
<partition_number_expression> TO <partition_number_expression>
Backward Compatible Relational Index
Important The backward compatible relational index syntax structure will be removed in a future version of SQL Server. Avoid using this syntax structure in new development work, and plan to modify applications that currently use the feature. Use the syntax structure specified in <relational_index_option> instead. CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column_name [ ASC | DESC ] [ ,...n ] )
[ WITH <backward_compatible_index_option> [ ,...n ] ]
[ ON { filegroup_name | "default" } ]
<object> ::=
{
[ database_name. [ owner_name ] . | owner_name. ]
table_or_view_name
}
<backward_compatible_index_option> ::=
{
PAD_INDEX
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB
| IGNORE_DUP_KEY
| STATISTICS_NORECOMPUTE
| DROP_EXISTING
} – SQL Database Syntax
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
}
<relational_index_option> ::=
{
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| DROP_EXISTING = { ON | OFF }
| ONLINE = { ON | OFF }
| DATA_COMPRESSION = { NONE | ROW | PAGE}
} <filter_predicate> ::=
<conjunct> [ AND <conjunct> ]
<conjunct> ::=
<disjunct> | <comparison>
<disjunct> ::=
column_name IN (constant ,…)
<comparison> ::=
column_name <comparison_op> constant
<comparison_op> ::=
{ IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< }
-- Azure SQL Data Warehouse syntax
-- Parallel Data Warehouse syntax
CREATE [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON [ database_name . [ schema ] . | schema . ] table_name
( { column [ ASC | DESC ] } [ ,...n ] )
WITH ( DROP_EXISTING = { ON | OFF } )
[;] 4 Indexed Views:
创建Indexed Views是有限制的,Indexed View的第一个索引必须是unique clusterd index,之后才能继续建立其他的nonunique ,nonclustered index. 在创建indexed view的索引时,必须注意set options的值:
Verify the SET options are correct for all existing tables that will be referenced in the view.
Verify that the SET options for the session are set correctly before you create any tables and the view.
Verify that the view definition is deterministic.
Create the view by using the WITH SCHEMABINDING option.
Create the unique clustered index on the view.
引自: Create Indexed Views
需要着重注意修改的option的值,这些值会影响查询结果集,比如 CONCAT_NULL_YIELDS_NULL , 假如设置为On, ‘ABC’ + NULL 就等于NULL, 假如设置为off, 则结果等于’ABC’:
上面的表格中列出来几个set options的值,在遇到以下的几种情况,必须设置为Required Value这个栏中的值:
1. The view and subsequent indexes on the view are created. 视图及其索引在创建的时候 ; 这是自个儿翻译的,大意是在试图创建indexed view及其索引的时候,我们要适当设置这些options;
2. The base tables referenced in the view at the time the table is created : 视图中引用到的基础表在创建视图时已经建立好了? 难道视图还能先于其引用表创建?
3. There is any insert, update, or delete operation performed on any table that participates in the indexed view. This requirement includes operations such as bulk copy, replication, and distributed queries. 当我们要对indexed view用到的任何基础表做insert, update, delete包括bulk copy, replication, 分布式查询的时候,我们需要设置这些set options;
4. The indexed view is used by the query optimizer to produce the query plan. 当视图被查询优化器用在执行计划里面的时候。
以上是引用了这个文档中的说明 :
Create Indexed Views
但是从目前来看,似乎解释并不可靠,因为针对2中提到的视图先于引用表而创建就不对,我们尝试创建类似地视图 ,
use lenistest3
go
create view dbo.v_fctdbsize as
select db_id, db_file_id, size
from dbo.fctdbfilesize ;
Msg 208, Level 16, State 1, Procedure v_fctdbsize, Line 6
Invalid object name 'dbo.fctdbfilesize'.所以符合set options之后,我们就可以创建indexed view了。参考实例:
SET NUMERIC_ROUNDABORT OFF;
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT,
QUOTED_IDENTIFIER, ANSI_NULLS ON;有关set options这里有非常有趣的内幕: 参考了这篇外文,就差不多能知道所有有关option的可能值了:
Get the current value of SET options using @@OPTIONS
这篇文章主要讲的是如何查看set options的值,查看某一个option是否开启或者关闭:
use lenistest3
go
select @@OPTIONS
-----------
5496
use lenistest3
go
set nocount on
select @@OPTIONS
-----------
6008上面这个例子就讲述了开启一个option之后 , @@options的变化。而这里set nocount on给@@options的值增加了512. 5496用二进制表示就是1010101111000。 6008用二进制表示就是1011101111000. 增加的512正好是将第十位置为1. 其他的set options也类似,在相应的位置更改bit.
if @@OPTIONS & 1 = 0 Print 'DISABLE_DEF_CNST_CHK is OFF' else Print 'DISABLE_DEF_CNST_CHK is ON'
If @@OPTIONS & 2 = 0 Print 'IMPLICIT_TRANSACTIONS is OFF' else Print 'IMPLICIT_TRANSACTIONS is ON'
If @@OPTIONS & 4 = 0 Print 'CURSOR_CLOSE_OFF_COMMIT is OFF' else Print 'CURSOR_CLOSE_ON_COMMIT is ON'
If @@OPTIONS & 8 = 0 Print 'ANSI_WARNINGS is OFF' else Print 'ANSI_WARNINGS is ON'
If @@OPTIONS & 16 = 0 Print 'ANSI_PADDING is OFF' else Print 'ANSI_PADDING is ON'
If @@OPTIONS & 32 = 0 Print 'ANSI_NULLS is OFF' else Print 'ANSI_NULLS is ON'
If @@OPTIONS & 64 = 0 Print 'ARITHABORT is OFF' else Print 'ARITHABORT is ON'
If @@OPTIONS & 128 = 0 Print ' ARITHIGNORE is OFF' else Print ' ARITHIGNORE is ON'
If @@OPTIONS & 256 = 0 Print 'QUOTED_IDENTIFIER is OFF' else Print 'QUOTED_IDENTIFIER is ON'
If @@OPTIONS & 512 = 0 Print 'NOCOUNT is OFF' else Print 'NOCOUNT is ON'
If @@OPTIONS & 1024 = 0 Print 'ANSI_NULL_DFLT_OFF is OFF'else Print 'ANSI_NULL_DFLT_ON is ON'If @@OPTIONS & 2048 = 0 Print 'ANSI_NULL_DFLT_OFF is OFF' else Print 'ANSI_NULL_DFLT_OFF is ON'
If @@OPTIONS & 4096 = 0 Print 'COFFCAT_NULL_YIELDS_NULL is OFF' else Print 'CONCAT_NULL_YIELDS_NULL is ON'
If @@OPTIONS & 8192 = 0 Print 'NUMERIC_ROUNDABORT is OFF' else Print 'NUMERIC_ROUNDABORT is ON'
If @@OPTIONS & 16384 = 0 Print 'XACT_ABORT is OFF' else Print 'XACT_ABORT is ON'上面的脚本用到了bitwise And操作,对位做逻辑与判断,[0,1],[1,0],[0,0]得0,[1,1]得1。只有当结果是1的时候,表示对应的option是开启的。
SET DISABLE_DEF_CNST_CHK is included for backward compatibility only. The functionality of this statement is now built into Microsoft SQL Server 2000. In a future version of SQL Server, SET DISABLE_DEF_CNST_CHK may not be supported.
SET IMPLICIT_TRANSACTIONS : On表示在每一个语句一开头加上begin transaction,如果是off, 表示自动提交autocommit .
Cursor_Close_On_Commit:当事务提交后,cursor是不是会被自动关闭。这里有讲究,这个要靠transaction的状态来自动关闭的cursor必须声明在transaction里面 :
set nocount on
If @@OPTIONS & 4 = 0 select 'CURSOR_CLOSE_OFF_COMMIT is OFF' else select 'CURSOR_CLOSE_ON_COMMIT is ON'
if @@OPTIONS & 4 = 0
set CURSOR_CLOSE_ON_COMMIT on ;
If @@OPTIONS & 4 = 0 select 'CURSOR_CLOSE_ON_COMMIT is OFF' else select 'CURSOR_CLOSE_ON_COMMIT is ON'
declare my_cur cursor for select top 1 name from sys.tables
declare @tabelname varchar(200)
open my_cur
fetch next from my_cur into @tabelname ;
begin transaction
select ltrim(rtrim(convert(varchar(20),@tabelname )))
commit transaction ;
fetch next from my_cur into @tabelname ;
select cursor_status('global','my_cur')
close my_cur
deallocate my_cur这个脚本里,我们将cursor定义在transaction的外面,结果顺顺利利的跑下来了.
set nocount on
If @@OPTIONS & 4 = 0 select 'CURSOR_CLOSE_OFF_COMMIT is OFF' else select 'CURSOR_CLOSE_ON_COMMIT is ON'
if @@OPTIONS & 4 = 0
set CURSOR_CLOSE_ON_COMMIT on ;
If @@OPTIONS & 4 = 0 select 'CURSOR_CLOSE_ON_COMMIT is OFF' else select 'CURSOR_CLOSE_ON_COMMIT is ON'
begin transaction
declare my_cur cursor for select top 1 name from sys.tables
declare @tabelname varchar(200)
open my_cur
fetch next from my_cur into @tabelname ;
select ltrim(rtrim(convert(varchar(20),@tabelname )))
commit transaction ;
fetch next from my_cur into @tabelname ;
select cursor_status('global','my_cur')
close my_cur
deallocate my_cur
Msg 16917, Level 16, State 2, Line 18
Cursor is not open.
Msg 16917, Level 16, State 1, Line 20
Cursor is not open.这个脚本里,我们在transaction里面定义了cursor,发现出错了,错误提示是cursor已经关闭。而且cursor_status返回的值也是 -1,而不是 1。
关于函数cursor_status的返回值:
1 表示至少有一条记录
0表示没有记录
-1表示关闭
-2 不可用
-3 指定的cursor不存在
SET ANSI_WARNINGS :
When set to ON, if null values appear in aggregate functions, such as
SUM, AVG, MAX, MIN, STDEV, STDEVP, VAR, VARP, or COUNT, a warning
message is generated. When set to OFF, no warning is issued. When set
to ON, the divide-by-zero and arithmetic overflow errors cause the
statement to be rolled back and an error message is generated. When
set to OFF, the divide-by-zero and arithmetic overflow errors cause
null values to be returned. The behavior in which a divide-by-zero or
arithmetic overflow error causes null values to be returned occurs if
an INSERT or UPDATE is tried on a character, Unicode, or binary column
in which the length of a new value exceeds the maximum size of the
column. If SET ANSI_WARNINGS is ON, the INSERT or UPDATE is canceled
as specified by the ISO standard. Trailing blanks are ignored for
character columns and trailing nulls are ignored for binary columns.
When OFF, data is truncated to the size of the column and the
statement succeeds.
这个option主要是处理NULL, 分母为0的计算,开启这个开关,处理null, 分母为0的计算时,就报错。当为computed column, indexed view创建索引,这个开关一定要开启。MSDN上有更细的解说 ,我们可以通过这篇文章来学习:
Configure the user options Server Configuration Option
Value
Configuration
Description
1
DISABLE_DEF_CNST_CHK
Controls interim or deferred constraint checking.
2
IMPLICIT_TRANSACTIONS
For dblib network library connections, controls whether a transaction is started implicitly when a statement is executed. The IMPLICIT_TRANSACTIONS setting has no effect on ODBC or OLEDB connections.
4
CURSOR_CLOSE_ON_COMMIT
Controls behavior of cursors after a commit operation has been performed.
8
ANSI_WARNINGS
Controls truncation and NULL in aggregate warnings.
16
ANSI_PADDING
Controls padding of fixed-length variables.
32
ANSI_NULLS
Controls NULL handling when using equality operators.
64
ARITHABORT
Terminates a query when an overflow or divide-by-zero error occurs during query execution.
128
ARITHIGNORE
Returns NULL when an overflow or divide-by-zero error occurs during a query.
256
QUOTED_IDENTIFIER
Differentiates between single and double quotation marks when evaluating an expression.
512
NOCOUNT
Turns off the message returned at the end of each statement that states how many rows were affected.
1024
ANSI_NULL_DFLT_ON
Alters the session’s behavior to use ANSI compatibility for nullability. New columns defined without explicit nullability are defined to allow nulls.
2048
ANSI_NULL_DFLT_OFF
Alters the session’s behavior not to use ANSI compatibility for nullability. New columns defined without explicit nullability do not allow nulls.
4096
CONCAT_NULL_YIELDS_NULL
Returns NULL when concatenating a NULL value with a string.
8192
NUMERIC_ROUNDABORT
Generates an error when a loss of precision occurs in an expression.
16384
XACT_ABORT
Rolls back a transaction if a Transact-SQL statement raises a run-time error.
前面说了一堆在indexed view之前预先处理的一些操作,接下来我们看看怎么新建一个indexed view,并在这个view上面再建立有几个索引:
首先,我们要新建一个view, 并且业务上一定要使这个view 有唯一可识别的字段或者字段组合,然后给view新建一个unique clustered index。
create view dbo.v_orderamount
as
select row_number() over(partition by c.processingmonth order by c.processingmonth) as rnm, c.processingmonth, o.OrderAmount
from dbo.FctSalesMonth o
inner join calendar c on o.OrderMon = c.[current_date]
go
create unique clustered index idx_view_index on v_orderamount(rnm)
Msg 1939, Level 16, State 1, Line 18
Cannot create index on view 'v_orderamount' because the view is not schema bound.什么叫做schema bound? 我们加上with schemabinding,还是有错:
create view dbo.v_orderamount
with schemabinding
as
select row_number() over(partition by c.processingmonth order by c.processingmonth) as rnm, c.processingmonth, o.OrderAmount
from dbo.FctSalesMonth o
inner join calendar c on o.OrderMon = c.[current_date]
go
Msg 4512, Level 16, State 3, Procedure v_orderamount, Line 15
Cannot schema bind view 'dbo.v_orderamount' because name 'calendar' is invalid for schema binding. Names must be in two-part format and an object cannot reference itself.create view dbo.v_orderamount
with schemabinding
as
select row_number() over(partition by c.processingmonth order by c.processingmonth) as rnm, c.processingmonth, o.OrderAmount
from dbo.FctSalesMonth o
inner join dbo.calendar c on o.OrderMon = c.[current_date]
go
create unique clustered index idx_view_index on v_orderamount(rnm)
Msg 10143, Level 16, State 1, Line 21
Cannot create index on view "lenistest3.dbo.v_orderamount" because it contains a ranking or aggregate window function. Remove the function from the view definition or, alternatively, do not index the view.我们把所有的对象加上schema, 这类schemabinding的问题就没有了。但是 有新的问题出现,在view里面如果有聚合窗口函数存在,是不允许建立indexed view.
create view dbo.v_orderamount
with schemabinding
as
select salesid as rnm, c.processingmonth, o.OrderAmount
from dbo.FctSalesMonth o
inner join dbo.calendar c on o.OrderMon = c.[current_date]
go
create unique clustered index idx_view_index on v_orderamount(rnm)最后我们给dbo.FctSalesMonth这个表上了一个自增列,基于这个自增列我们对新建view做unique clustered index,一切顺利。
接着我们就可以给indexed view加索引了
create index idx_ordermonth on v_orderamount(processingmonth) ;如果先建立普通索引而不是唯一聚集索引会发生什么事情呢?
Msg 1940, Level 16, State 1, Line 23
Cannot create index on view 'v_orderamount'. It does not have a unique clustered index.在数据库引擎中,indexed view是被当作表来处理了:
select * from sys.objects where name = 'v_orderamount'
select * from sys.indexes where object_id = object_id(N'dbo.v_orderamount');Indexed View是自动更新的,当indexed view引用的基础表有数据更新,这个view也就自动更新了。
delete FctSalesMonth where salesid = 1
select * from dbo.v_orderamount除了表,索引,索引视图等,占用磁盘最大的莫过于日志文件与备份文件了。其实日志文件在某功能上来说,相当于是备份文件。在还原与恢复数据库的时候,我们总需要日志文件来保证最后一秒钟的数据一致性,所以可以看做是备份文件。这里要严格区分的是还原与恢复的关系,他俩有着不同的概念。 在还原数据库的时候,还原做的事情,仅仅是把备份文件重新构建一个数据库出来。基于备份文件存储的内容不同,还原出来的数据库也有不同的状态:如果备份文件是一份全备份文件,这个全备份文件会保留当时所有的数据文件中的数据,也同时包含了日志文件中没有提交的事务,当这么一个全备份文件被还原的时候,构建出来的新数据库是可以被立即访问与使用的;如果备份文件仅仅是个差异备份或者日志备份,在还原的时候, 还需要先还原一个全备份的文件,当这个全备份还原之后,新构建的这个数据库是不能立即被使用的,还要将差异备份或者日志备份恢复到这个新建的数据库上。所以整个还原过程会有还原与恢复两个阶段。
SQL Server 有三种备份方式: 全备份-full backup, 差异备份 differiate backup, 日志备份 log backup,有两种备份内容: 数据文件与日志文件,有三种还原模式: Full Recovery, Bulk-log Recovery, Simple Recovery. 还原模式决定了日志文件是如何存储的,日志文件的存储决定了怎么去还原和恢复一个数据库。
所以我们先看还原模式: Simple Recovery是最简单的模式,日志文件都不保存,所以还原过后容易丢失数据,比如tempdb就采取这种模式,数据内容不会被复用。日志文件限定文件大小,日志会被重写;日志文件不限定大小,日志就会无限制的扩张。Full Recovery, 是最常用的一种模式,这种模式下的日志,如果不做备份或者压缩,也是无限制的扩张;如果作了日志大小限制,就会限制事务的大小(更改数据量大小或者并发的容量大小). Bulk Logged, 只对大数据量操作作日志,这种模式适应范围不普及。虽然我们对日志也会做备份,但是业务系统都是7*24运行的,作为一个连续运营的模式,备份日志与日志文件之间总会存在一定的延迟,所以备份策略中还需要考虑日志文件的备份,万一日志文件被损毁,就不能还原到故障前时间点。Oracle对于日志文件是做多备的,可以指定任意(必须大于等于3)数量的日志文件作冗余,一旦其中一个日志文件损毁,其他文件都能用。这就有点像RAID 1 模式,把相同的文件复制同样的几分,分别放到不同的存储硬件上,当一个硬件不可用,还有其他几个硬件上的文件可用。所以把日志文件放在RAID上做好多备份,也算是一种日志文件的备份策略。
日志文件的存储也是很有意思的。我们可以限定日志文件大小,也可以使其无限制的扩展。如果无限制的扩展,有个坏处,如果我们不对磁盘大小与日志文件同时做好监控的话,很容易让日志文件扩展到撑爆硬盘,这个时候再想着去挽救恐怕就不容易了。所以最好的方法还是限制下文件大小,做好监控(包括对物理磁盘和日志文件),等到超过警戒线,就采取措施,调查故障。
假定我们限制了一个日志文件的大小为10GB。那么这个日志文件里可能有这几种类型的存储段:已经被备份过的日志,但是还没有被shrink,所以依然占用空间;继上次日志备份后,新生成的一系列日志;在这新生成的日志之后,可能是上次shrink之前到达过的最大的日志文件位置,这也是 最大的被分配过的日志空间,比如每到8GB,就被备份和shrink了;最后一段就是从来没有被使用过的日志空间,比如8GB之后的空间,仅仅是用来做紧急备用的,仅支持突发的大事务。
用下面的图来表示:黑色的部分就是使用过的日志但是没有被备份,这部分日志在备份后而并没有执行shrink时候,依然占用日志空间;红色的部分就是当前使用的日志,这部分日志没有被备份;绿色部分就是继上次shrink之前,日志曾经到达的最大空间位置;白色部分就是最大日志可用空间。这些日志段(除了正在使用的日志段)在backup之后,都会被清空,变成可用的日志空间,但是这时的日志文件大小(在操作系统级)并没有改变,10GB 还是10GB;经过shrink之后,这些空间才被操作系统回收,仅仅剩下当前正在使用的日志,可能就只有2G ,此时日志文件大小就是 2G.但是shrink并不总是好事,因为文件的再次分配磁盘也是需要消耗系统资源的。所以保证可用空间足够大,及时清空已经备份的日志段就可以了。
Shrink对数据库大小 的影响:
日志文件的shrink只有在transaction log file被备份完之后,执行checkpoint命令,接着shrink才有用(这是负责任的用法,如果不考虑数据的丢失,则不需要这么多限制). Checkpoint的作用是将没有完成提交的事务也写到transaction log里面去,确保能还原到最新的数据记录时间点,在恢复数据库的时候,这些没有提交的事务就会回滚。假设在transaction log备份完之后,系统(database storage engine)也会马上做一次checkpoint,以确定一个备份完成时时间点A,这样在下一次执行checkpoint之后,标记一个时间点B, A之前的日志空间会被shrink给收回,只留下A与B之间的日志空间.
试验 0: 把日志文件限定成一个100MB的文件,然后不停的输入数据.
这个试验中发现了一个有趣的现象: 当我以batch的形式往数据库插入数据的时候,数据文件增大而日志文件并不增大,也就是说只要一个小batch执行完立即提交,日志文件并不增加;而当我写了很大的一段事务而久久不提交的时候,日志文件很快就撑爆了。
use master
go
use lenistest
goCREATE DATABASE [lenistest]
ON
PRIMARY
( NAME = N'lenistest5',
FILENAME = N'E:\Data_BU\lenistest5.mdf' ,
SIZE = 10240KB ,
MAXSIZE = 1024000KB ,
FILEGROWTH = 1024KB )
LOG ON
( NAME = N'lenistest5_log',
FILENAME = N'E:\Data_BU\lenistest5_log.ldf' ,
SIZE = 10240KB ,
MAXSIZE = 102400KB ,
FILEGROWTH = 1024KB )GO
create table ##loopControl(controlprocessing bit) ;
insert into ##loopControl(controlprocessing) values(1);
go
create table dbo.dataloading(object_id bigint, object_name varchar(200)) ;
gobegin transaction
while (exists (select 1 from ##loopControl where controlprocessing = 1 ))
begin
insert into dbo.dataloading(object_id,object_name)
select object_id, name as object_name
from sys.objects
end
commit transactionMsg 9002, Level 17, State 4, Line 46
The transaction log for database 'lenistest' is full due to 'ACTIVE_TRANSACTION'.在上面的脚本中,我们首先将数据库的Recovery Model设置成Full Recovery. 一开始的时候,我们没有加事务控制,所以在数据库文件增大到200MB的时候,日志文件还是10MB. 后来加了事务控制,在很短时间内就把日志文件给撑爆了。 这个时候我们需要做些空间回收的动作,那就是shrink。
Shrink有很多种方式,可以有一次性shrink数据文件与日志文件(DBCC SHRINKDATABASE);分别针对数据文件,日志文件做shrink, DBCC SHRINKFILE, DBCC SHRINKLOG(适用SQL Data Warehouse和 Parallel Data Warehouse)
DBCC SHRINKDATABASE
( database_name | database_id | 0
[ , target_percent ]
[ , { NOTRUNCATE | TRUNCATEONLY } ]
)
[ WITH NO_INFOMSGS ]上面是一次性shrink数据文件与日志文件。
Target_percent就是压缩数据库总体体积,保留特定比例的空闲的数据空间;
NOTRUNCATE: 只压缩空间而不回收空间给操作系统,会把文件尾部分配的空间往文件前部没分配的空间移动;所以数据库文件看起来是一样大小的,实际上分配空间与空闲空间已经发生了移动。这个选项只是用于数据文件而非日至文件。实际上执行这个命令的时候非常耗时间,300MB的数据文件5分钟都做不完。进一步的检查发现不是非常耗时而是被block了,在shrink过程中,如果有数据页锁住,shrink执行就被挂起。
TRUNCATEONLY:不会把没有分配的空间往文件前段移动,而仅仅是将没有分配使用的空间直接丢掉。只是用于日志文件。
use master
go
alter database lenistest
set recovery simple ;ALTER DATABASE { database_name | CURRENT }
SET
{
<optionspec> [ ,... n ] [ WITH <termination> ]
}<optionspec> ::=
{
<recovery_option>
}
<recovery_option> ::=
{
RECOVERY { FULL | BULK_LOGGED | SIMPLE }
| TORN_PAGE_DETECTION { ON | OFF }
| PAGE_VERIFY { CHECKSUM | TORN_PAGE_DETECTION | NONE }
}修改recovery model为simple之后,执行shrink,日志文件就即可清空了。事实上并不需要切换recovery model。也能达到shrink log file的作用。
dbcc shrinkdatabase (lenistest ,10 )
dbcc shrinkdatabase (lenistest ,truncateonly )上面两个命令都可以执行shrink. 日志文件都能重新清空。
DBCC SHRINKLOG
[ ( SIZE = { target_size [ MB | GB | TB ] } | DEFAULT ) ]
[ WITH NO_INFOMSGS ]
[;]
DBCC SHRINKLOG (SIZE = 10 MB ) ;这种shrink方式只能用于SQL Data Warehouse, Parallel Data Warehouse
DBCC SHRINKFILE
(
{ file_name | file_id }
{ [ , EMPTYFILE ]
| [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ]
}
)
[ WITH NO_INFOMSGS ]
dbcc shrinkfile (lenistest5_log, 10) ;上面三种shrink方式都不需要切换recovery model,这是我曾经的误区。都直接可以达到压缩数据库的大小。
上面我们提到一个有趣的问题,就是在transaction耗时很长的时候,就会充满整个日志文件,导致接下来细小的事务都不能顺利完成;而立即提交的事务哪怕运行的次数很多也不会占用很多日志文件。那么在这个写日志的过程中,到底是什么样的一个原理呢?
当数据页(总是读取数据页而非数据行)从磁盘读到内存的时候,经过一段时间,有的数据页没有被修改,我们称之为干净的缓存(clean buffer);有的数据页中部分的数据行被修改了或者删除了,这种数据缓存我们称之为脏数据页(dirty buffer). 脏数据页在checkpoint执行之后,会被写回到数据库磁盘中去,哪怕这个时候脏数据页上的数据事务还没有被提交。假设这个时候数据库发生了故障,服务终止了,那么磁盘上的数据就是脏数据,再次启动数据库的时候,这些数据就变成了一些不完整的,缺乏逻辑一致性的数据(假设这个事务就是你在ATM上汇款的时候, 刚扣完款数据库就终止,再次启动的时候你会发现你的帐户被扣款,但是对方还没有收到帐款), 那么怎么保证数据库的这种一致性问题,SQL Server会使用Write-Ahead log机制,在更改数据页的时候,同时也往缓存中写入一些日志,等到事务提交或者checkpoint执行,这些日志缓存先写入磁盘日志文件,再写数据文件,这个时候即使数据库服务终止,数据库还可以根据日志文件找到当机时候事务的提交状态再采取恢复策略。
当事务耗时很长的时候,会占用很多内存来做缓存,这其中会包含数据缓存也包含日志缓存,如果不及时写入硬盘,一旦内存异常,整个操作就跟没有发生一样。所以为了保障数据操作持续,完整,SQL Server采用了checkpoint的方式,每过一段时间就把缓存(数据缓存和日志缓存)都写入到磁盘中去。这个地方我们要考虑的事情就是:
1 checkpoint的频率以及如何维护这个频率:SQL Server数据库中有4种checkpoint:
自动式:在某一段时间内,SQL Server Storage会自动执行一次checkpoint. 默认的频率是根据当时的服务器负载情况而自动调整的。目的就是了恢复的时候尽可能的保证数据一致性与即时性,当然checkpoint会有占用一定的服务器资源,太频繁的checkpoint会给性能造成一定影响。我们可以通过察看服务器的参数来检查checkpoint的频率,也可以修改这个参数来更改自动化checkpiont事件的频率.
declare @serverconfigoption nvarchar(200) = '%RECOVER%'
if exists(select 1 from tempdb.sys.tables where upper(name) like '%SERVERCONFIG%')
drop table #serverconfigures;
create table #serverconfigures(name nvarchar(2000), minimum bigint, maximum bigint, config_value bigint, run_value bigint)
insert into #serverconfigures(name,minimum,maximum,config_value,run_value)
exec sp_configure;
select * from #serverconfigures
where upper(name) like @serverconfigoption通过下面的脚本可以修改checkpoint的频率:
EXEC sp_configure'recovery interval','seconds'手动式:手动执行checkpoint [checkpoint_duration]. Checkpoint_duration是以秒为单位,目的是控制checkpoint过程要在多少时间内完成。手工执行checkpoint可以跑在指定的数据库上,而不像数据库自动的checkpoint是跑在每一个数据库上。
间接式:这里的理解稍微绕个弯,并不是直接或者间接执行checkpoint命令,而是设置一个影响checkpiont自动执行频率参数。刚才我们看了服务器关于自动checkpoint参数的查询,提供了一种修改频率的方法。这里再提供一种方法来修改这个参数:
Alter Database … Set Target_Recovery_Time = target_recovery_time {seconds|minutes}如果我们将这个频率设置成5分钟,那么每5分钟就会执行一次checkpoint,如果这个时候再执行一次backup log, 那么我们的数据库在恢复的时候顶多就差5分钟的日志需要重新恢复。
内部式:这种方式就可以认为间接的运行了checkpoint,因为是在执行其他操作的时候,顺便执行了checkpiont的功能,比如 backup , create database snapshot的时候,都会做一次checkpoint,以确保数据文件与日志文件的一致性。
2 如何回收脏数据页的缓存:checkpoint之后所有的缓存都被写到磁盘了, 但是这些缓存还是存在于内存中的,并不会被清空,这个时候如果我们考察数据库内存的使用量应该还是很高的,直到我们用dbcc dropcleanbuffer来回收这些缓存? 当脏数据涉及到的事务还没有被提交的时候,我们做了手工的checkpoint,这个时候脏数据缓存会被写到磁盘里面去,那么这个时候的脏数据页是否还是标示为脏数据呢? 怎么察看? 如果脏数据页被标示为干净数据页了,那么dbcc dropcleanbufer就能回收这些曾经由脏数据占领的数据页了。
这里做个小实验,就可以很明了,一旦数据库被执行了checkpoint, 数据页缓存还是存在于内存中,直到我们执行dbcc dropcleanbuffers, 这些数据页无论是干净还是脏,都被回收了。我们对Memory这个performance Counter进行一段时间的监控,并且将每20秒的性能计数器(performance counters)记录下来 :
while(1=1)
begin
insert into dbo.FctPerformanceCounters (object_name,counter_name,instance_name,cntr_value,cntr_type)
select object_name,counter_name,instance_name,cntr_value,cntr_type
from sys.dm_os_performance_counters
where upper(object_name) like '%MEMORY MANAGER%'
WAITFOR DELAY '00:00:20' ;
end
declare @sql_header nvarchar(200) = 'use ' ;
declare @sql_body nvarchar(2000) = 'checkpoint 10' ;
declare @use_databasename nvarchar(200) ='' ;
declare my_cur cursor
for
select name from sys.databases where upper(name) not in ('MASTER','MSDB','TEMPDB','DISTRIBUTION','MODEL') ;
open my_cur
fetch next from my_cur into @use_databasename ;
while (@@FETCH_STATUS = 0)
begin
set @sql_header = 'use '+ @use_databasename ;
set @sql_body = @sql_header + char(13) +char(10)+'go' + char(13) +char(10)+' checkpoint' ;
print @sql_body ;
fetch next from my_cur into @use_databasename ;
end
close my_cur
deallocate my_cur ;
当我们只是做checkpoint的时候,一段长时间内Free Memory还是很低,一旦执行DBCC DROPCLEANBUFFERS之后,立马就多出来了。
我们再看下Database Cache Memory在这段时间 内的变化;

Free Memory和Database Cache Memory此长彼伏正是DBCC DROPCLEANBUFFERS的效果。当然这个里面也包含了SQL Cache Memory, 这个就需要DBCC FREEPROCCACHE来调节了。虽然SQL Cache Memory只是动态SQL Plan Cache,更详细的还要看SQL Server: plan cache。

关于transaction log: transaction log反应的是数据库数据的更改。如果数据的更改对应的事务还没有提交,这个时候数据是没有保存到数据库中的,数据页上的数据无论是在缓存中,还是经由checkpoint暂时写到磁盘上了,这份数据还是脏的,记录这份数据更改的transaction log被称为active log, 这份log占用了一定的日志文件VLF(Virtual Log File), 只要这个事务不提交,这active log就始终占用日志文件的容量,且随着操作的增加,日志也相应增加;如果事务提交了,这段事务占用的log就被标示上unactive,就可以被清空循环利用了。
回到我们前面提到的事务占用大量日志文件的例子,原因也就找到了。一旦开启一段事务但不结束,就能引起日志文件撑满。如果开启一段事务并及时提交,始终能循环利用。
begin transaction
while (exists (select 1 from ##loopControl where controlprocessing = 1 ))
begin
insert into dbo.dataloading(object_id,object_name)
select object_id, name as object_name
from sys.objects
end
commit transaction
while (exists (select 1 from ##loopControl where controlprocessing = 1 ))
begin
begin transaction
insert into dbo.dataloading(object_id,object_name)
select object_id, name as object_name
from sys.objects
commit transaction
end上面两段脚本,一是开启了一段超常耗时的事务,结果不一会儿就能撑爆日志,原因就是这段事务占用的日志始终是活动的,并且越来越大;第二段事务就及时提交了,这样事务占用的日志文件在提交完之后就标记为unactive了,如果需要的时候,随时可以被回收重利用。
欢迎关注微信公众号【有关SQL】



















 3199
3199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











