







参考博文:
2、PyTorch基础(五)-- 损失函数 有示例代码
3、PyTorch 中的损失函数 有示例代码
1 基本用法
criterion = LossCriterion() #构造函数有自己的参数
loss = criterion(x, y) #调用标准时也有参数
criterion = LossCriterion() #构造函数有自己的参数
loss = criterion(x, y) #调用标准时也有参数
2 损失函数
2-1 L1范数损失 L1Loss
计算 output 和 target 之差的绝对值。
torch.nn.L1Loss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-2 均方误差损失 MSELoss
计算 output 和 target 之差的均方差。
torch.nn.MSELoss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-3 交叉熵损失 CrossEntropyLoss
当训练有 C 个类别的分类问题时很有效. 可选参数 weight 必须是一个1维 Tensor, 权重将被分配给各个类别. 对于不平衡的训练集非常有效。
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
torch.nn.CrossEntropyLoss(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
ignore_index (int, optional) – 设置一个目标值, 该目标值会被忽略, 从而不会影响到 输入的梯度。
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-4 KL 散度损失 KLDivLoss
计算 input 和 target 之间的 KL 散度。KL 散度可用于衡量不同的连续分布之间的距离, 在连续的输出分布的空间上(离散采样)上进行直接回归时 很有效.
torch.nn.KLDivLoss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-5 二进制交叉熵损失 BCELoss
二分类任务时的交叉熵计算函数。用于测量重构的误差, 例如自动编码机. 注意目标的值 t[i] 的范围为0到1之间.
torch.nn.BCELoss(weight=None, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个 batch 元素的 loss 的权重. 必须是一个长度为 “nbatch” 的 的 Tensor
pos_weight(Tensor, optional) – 自定义的每个正样本的 loss 的权重. 必须是一个长度 为 “classes” 的 Tensor
2-6 BCEWithLogitsLoss
BCEWithLogitsLoss损失函数把 Sigmoid 层集成到了 BCELoss 类中. 该版比用一个简单的 Sigmoid 层和 BCELoss 在数值上更稳定, 因为把这两个操作合并为一个层之后, 可以利用 log-sum-exp 的 技巧来实现数值稳定.
torch.nn.BCEWithLogitsLoss(weight=None, reduction='mean', pos_weight=None)
参数:
weight (Tensor, optional) – 自定义的每个 batch 元素的 loss 的权重. 必须是一个长度 为 “nbatch” 的 Tensor
pos_weight(Tensor, optional) – 自定义的每个正样本的 loss 的权重. 必须是一个长度 为 “classes” 的 Tensor
2-7 MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, reduction='mean')
对于 mini-batch(小批量) 中每个实例的损失函数如下:
![]()
参数:
margin:默认值0
2-8 HingeEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, reduction='mean')
对于 mini-batch(小批量) 中每个实例的损失函数如下:
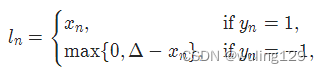
参数:
margin:默认值1
2-9 多标签分类损失 MultiLabelMarginLoss
torch.nn.MultiLabelMarginLoss(reduction='mean')
对于mini-batch(小批量) 中的每个样本按如下公式计算损失:
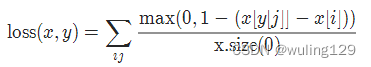
2-10 平滑版L1损失 SmoothL1Loss
也被称为 Huber 损失函数。
torch.nn.SmoothL1Loss(reduction='mean')
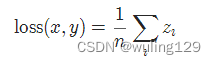
其中
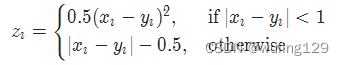
2-11 2分类的logistic损失 SoftMarginLoss
torch.nn.SoftMarginLoss(reduction='mean')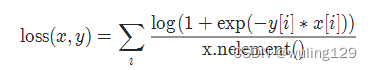
2-12 多标签 one-versus-all 损失 MultiLabelSoftMarginLoss
torch.nn.MultiLabelSoftMarginLoss(weight=None, reduction='mean')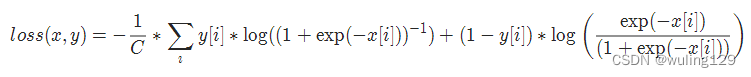
2-13 cosine 损失 CosineEmbeddingLoss
torch.nn.CosineEmbeddingLoss(margin=0.0, reduction='mean')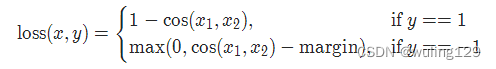
参数:
margin:默认值0
2-14 多类别分类的hinge损失 MultiMarginLoss
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, reduction='mean')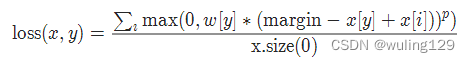
参数:
p=1或者2 默认值:1
margin:默认值1
2-15 三元组损失 TripletMarginLoss
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, reduction='mean')![]()
其中:![]()
2-16 连接时序分类损失 CTCLoss
CTC连接时序分类损失,可以对没有对齐的数据进行自动对齐,主要用在没有事先对齐的序列化数据训练上。比如语音识别、ocr识别等等。
torch.nn.CTCLoss(blank=0, reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-17 负对数似然损失 NLLLoss
负对数似然损失. 用于训练 C 个类别的分类问题.
torch.nn.NLLLoss(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
ignore_index (int, optional) – 设置一个目标值, 该目标值会被忽略, 从而不会影响到 输入的梯度.
2-18 NLLLoss2d
对于图片输入的负对数似然损失. 它计算每个像素的负对数似然损失.
torch.nn.NLLLoss2d(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-19 PoissonNLLLoss
目标值为泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, eps=1e-08, reduction='mean')
参数:
log_input (bool, optional) – 如果设置为 True , loss 将会按照公 式 exp(input) - target * input 来计算, 如果设置为 False , loss 将会按照 input - target * log(input+eps) 计算.
full (bool, optional) – 是否计算全部的 loss, i. e. 加上 Stirling 近似项 target * log(target) - target + 0.5 * log(2 * pi * target).
eps (float, optional) – 默认值: 1e-8
原文链接:https://blog.csdn.net/shanglianlm/article/details/85019768
示例代码:
# -*- coding: utf-8 -*-
"""
# @brief :
5. nn.L1Loss
6. nn.MSELoss
7. nn.SmoothL1Loss
8. nn.PoissonNLLLoss
9. nn.KLDivLoss
10. nn.MarginRankingLoss
11. nn.MultiLabelMarginLoss
12. nn.SoftMarginLoss
13. nn.MultiLabelSoftMarginLoss
14. nn.MultiMarginLoss
15. nn.TripletMarginLoss
16. nn.HingeEmbeddingLoss
17. nn.CosineEmbeddingLoss
18. nn.CTCLoss
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
# hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__))
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
# ------------------------------------------------- 5 L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nL1 loss:{}".format(inputs, target, loss))
# ------------------------------------------------- 6 MSE loss ----------------------------------------------
loss_f_mse = nn.MSELoss(reduction='none')
loss_mse = loss_f_mse(inputs, target)
print("MSE loss:{}".format(loss_mse))
# ------------------------------------------------- 7 Smooth L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.linspace(-3, 3, steps=500)
target = torch.zeros_like(inputs)
loss_f = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f(inputs, target)
# loss_l1 = np.abs(inputs.numpy() - target.numpy()) # target 为零
loss_l1 = np.abs(inputs.numpy())
plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()
plt.grid()
plt.show()
# ------------------------------------------------- 8 Poisson NLL Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.randn((2, 2))
target = torch.randn((2, 2))
loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none')
loss = loss_f(inputs, target)
print("8 Poisson NLL Loss\n input:{}\ntarget:{}\nPoisson NLL loss:{}".format(inputs, target, loss))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = torch.exp(inputs[idx, idx]) - target[idx, idx]*inputs[idx, idx]
print("第一个元素loss:", loss_1)
# ------------------------------------------------- 9 KL Divergence Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
# pytorch函数计算公式不是原始定义公式,其对输入默认已经取log了,在损失函数计算中比公式定义少了一个log(input)的操作
# 因此公式定义里有一个log(y_i / x_i),在pytorch变为了 log(y_i) - x_i,
# inputs_log = torch.log(inputs)
inputs = F.log_softmax(inputs, 1)
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss_f_none = nn.KLDivLoss(reduction='none')
loss_f_mean = nn.KLDivLoss(reduction='mean')
loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean')
loss_none = loss_f_none(inputs, target)
loss_mean = loss_f_mean(inputs, target)
loss_bs_mean = loss_f_bs_mean(inputs, target)
print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = target[idx, idx] * (torch.log(target[idx, idx]) - inputs[idx, idx])
print("第一个元素loss:", loss_1)
# ---------------------------------------------- 10 Margin Ranking Loss --------------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[1], [2], [3]], dtype=torch.float)
x2 = torch.tensor([[2], [2], [2]], dtype=torch.float)
target = torch.tensor([1, 1, -1], dtype=torch.float)
loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none')
loss = loss_f_none(x1, x2, target)
print(loss)
# ---------------------------------------------- 11 Multi Label Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])
y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long)
loss_f = nn.MultiLabelMarginLoss(reduction='none')
loss = loss_f(x, y)
print(loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
x = x[0]
item_1 = (1-(x[0] - x[1])) + (1 - (x[0] - x[2])) # [0]
item_2 = (1-(x[3] - x[1])) + (1 - (x[3] - x[2])) # [3]
loss_h = (item_1 + item_2) / x.shape[0]
print(loss_h)
# ---------------------------------------------- 12 SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]])
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float)
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
inputs_i = inputs[idx, idx]
target_i = target[idx, idx]
loss_h = np.log(1 + np.exp(-target_i * inputs_i))
print(loss_h)
# ---------------------------------------------- 13 MultiLabel SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7, 0.8]])
target = torch.tensor([[0, 1, 1]], dtype=torch.float)
loss_f = nn.MultiLabelSoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("MultiLabel SoftMargin: ", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
i_0 = torch.log(torch.exp(-inputs[0, 0]) / (1 + torch.exp(-inputs[0, 0])))
i_1 = torch.log(1 / (1 + torch.exp(-inputs[0, 1])))
i_2 = torch.log(1 / (1 + torch.exp(-inputs[0, 2])))
loss_h = (i_0 + i_1 + i_2) / -3
print(loss_h)
# ---------------------------------------------- 14 Multi Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]])
y = torch.tensor([1, 2], dtype=torch.long)
loss_f = nn.MultiMarginLoss(reduction='none')
loss = loss_f(x, y)
print("Multi Margin Loss: ", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
x = x[0]
margin = 1
i_0 = margin - (x[1] - x[0])
# i_1 = margin - (x[1] - x[1])
i_2 = margin - (x[1] - x[2])
loss_h = (i_0 + i_2) / x.shape[0]
print(loss_h)
# ---------------------------------------------- 15 Triplet Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
anchor = torch.tensor([[1.]])
pos = torch.tensor([[2.]])
neg = torch.tensor([[0.5]])
loss_f = nn.TripletMarginLoss(margin=1.0, p=1)
loss = loss_f(anchor, pos, neg)
print("Triplet Margin Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1
a, p, n = anchor[0], pos[0], neg[0]
d_ap = torch.abs(a-p)
d_an = torch.abs(a-n)
loss = d_ap - d_an + margin
print(loss)
# ---------------------------------------------- 16 Hinge Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1., 0.8, 0.5]])
target = torch.tensor([[1, 1, -1]])
loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none')
loss = loss_f(inputs, target)
print("Hinge Embedding Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1.
loss = max(0, margin - inputs.numpy()[0, 2])
print(loss)
# ---------------------------------------------- 17 Cosine Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
print("Cosine Embedding Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 0.
def cosine(a, b):
numerator = torch.dot(a, b)
denominator = torch.norm(a, 2) * torch.norm(b, 2)
return float(numerator/denominator)
l_1 = 1 - (cosine(x1[0], x2[0]))
l_2 = max(0, cosine(x1[0], x2[0]))
print(l_1, l_2)
# ---------------------------------------------- 18 CTC Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C)
inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes)
target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(inputs, target, input_lengths, target_lengths)
print("CTC loss: ", loss)















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









