







Hadoop目录结构
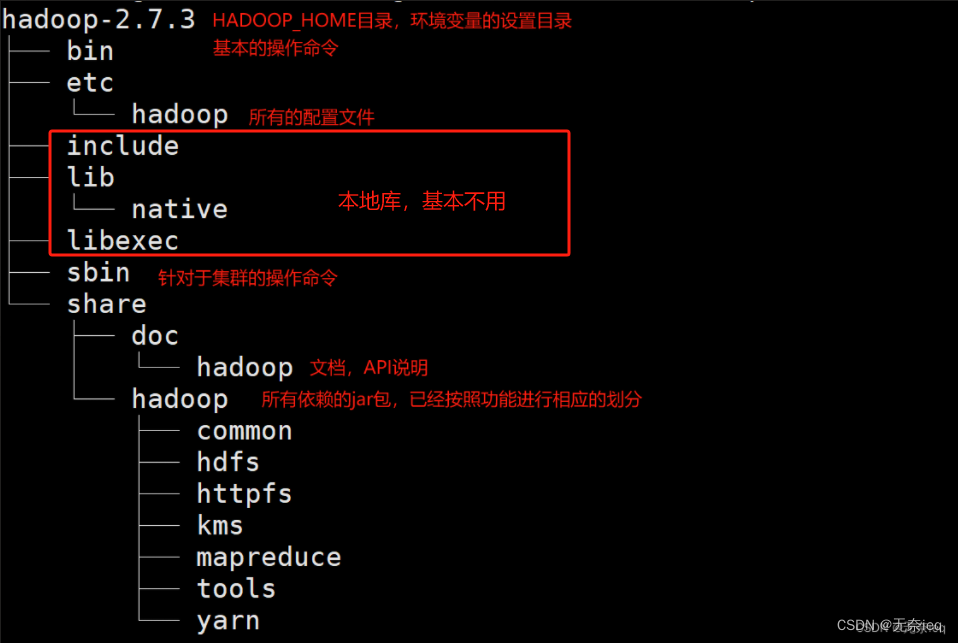
目前Hadoop已经升级到3.x版本,相比较于2.x版本,只是对性能进行了调优
Hadoop体系结构

一、HDFS体系结构
- NameNode :主节点/名称节点,相当于头部,操作整个HDFS
作用:1.管理整个HDFS;2.接收客户端请求,如数据上传和下载;3.维护HDFS,如edits文件(客户端操作日志),fsimage文件(元信息文件)
路径dfs路径下的name目录
edits文件:
路径:HADOOP_HOME/tmp/dfs/name/current
作用:记录客户端日志
描述:如图,日志文件都是二进制的形式,只能使用HDFS自带的日志查看器,将其转为xml文件进行查看
日志查看器:hdfs oev -i edits_inprogress_0000000000000000002 -o ~/out_log.xml


fsimage文件:
路径:HADOOP_HOME/tmp/dfs/name/current
作用:记录数据块位置信息,冗余信息
描述:如图,元信息文件都是二进制的形式,只能使用HDFS自带的元信息查看器,将其转为xml文件进行查看
元信息查看器:hdfs oiv -i fsimage_0000000000000000001 -o ~/fsimage_out.xml -p XML
- DataNode:从节点,主要用于保存数据
作用:1.按照数据块保存数据(hadoop版本:1.x 64M 2.x 128M);2.数据块位置(
find . -name blk*)
描述:设置数据块冗余度的一般原则:冗余度和数据节点个数一致(一般不超过3,不超过仅仅是因为存储空间极大的浪费,以及存储时间可能较长)
- SecondaryNameNode:第二主节点
作用:1.不是NameNode的热备;2.定期进行日志信息的合并(定期将edits文件合并为fsimage文件)
日志合并的过程:
1.NameNode生成edits日志和fsimage元信息文件(不含edits_inprogress文件)
2.SecondaryNameNode对齐进行下载拷贝到自身目录下
3.SecondaryNameNode对下载好的两个文件进行合并
4.SecondaryNameNode将合并好的文件上传至NameNode中
5.在下载与上传的过程中,NameNode可能产生新的文件(edits_inprogress文件,即正在编辑的文件),待编辑好,或是一个周期结束后,循环以上过程
注:
- 上传与下载的速度依赖于网络传输速度,因此为提高速度,通常将两者设置在同一机器上进行本地传输。
- 合并的时机:当HDFS发出检查点时触发(条件1:每60分钟;条件2:当edits文件达到64M;两个条件满足其一即可)
二、Yarn体系结构(待更新)
- ResourceManager:资源管理器
作用:1.接收客户端的请求(执行MapReduce的请求);2.资源的分配(CPU,网络,内存等);3.任务分配(分配给NodeManager进行执行)
- NodeManager:节点管理器
作用:1.从ResourceManager获取任务和资源;2.执行任务;
- Yarn调度MapReduce任务的过程
1.客户端发出任务请求(一般是
hadoop jar ******的命令,运行JobClient.java 或者JobSubmitter)
2.JobClient.java向ResourceManager发出请求(请求创建任务ID)ResourceManager,返回ID
3.JobClient.java将任务(jar文件)上传到HDFS中
4.JobClient.java获取元信息(数据的元信息和任务的元信息)
5.JobClient.java向ResourceManager提交任务(任务ID,数据元信息,任务元信息)
6.ResourceManager进行任务初始化(初始化过程一般包含执行任务的节点和分配的资源)
7.ResourceManager向节点(NodeManeger)进行任务分配,传输任务,资源信息,以及任务ID,数据元信息,任务元信息
8.NodeManager启动ApplicationContainer(任务运行的容器),进行任务执行
9.ApplicationContainer根据获取的任务元信息,数据元信息对HDFS中的DataNode(数据存储)进行访问,获取数据,任务
由于元信息存储的数据位置以及相关描述,而不是数据内容本身,因此ApplicationContainer在获取数据内容时,需要一定时间,所以通常将DataNode(数据存储的节点)和NodeManager(任务执行的节点)放置于同台机器上,以提高性能
- Yarn资源分配的方式
(1)FIFO(先来先服务)
(2)Capacity:容器管理调度,允许多个组织共享集群的资源,每个组织内部可能有队列进行分配
(3)Fair:公平调度,当任务具有相同优先级时,平均分配系统的资源
三、HBase
HBase定义:基于HDFS之上的NoSQL数据库
-
HMaster:主节点
-
RegionServer:从节点
-
ZooKeeper:分布式协调服务,作用相当于“数据库”

四、主从架构单点故障的问题
目标:实现HA的功能(High Availability 高度可用性)
方案:使用ZooKeeper进行实现,设置备用的主节点,当目前的主节点宕机时,激活备用节点
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











