






“ RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。”
01
—
Rabbitmq的特点
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
1、可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。
2、灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
3、消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。
4、高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
5、多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
6、多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。
7、管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
8、跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。
9、插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
02
—
Rabbitmq服务搭建
1、安装Erlang编程语言环境
进入官网https://www.erlang.org/下载对应的客户端并进行安装
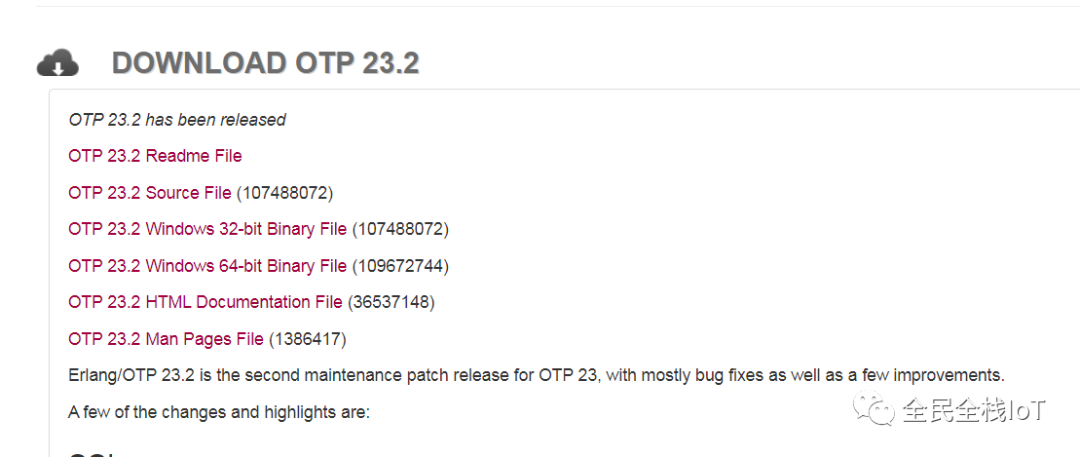
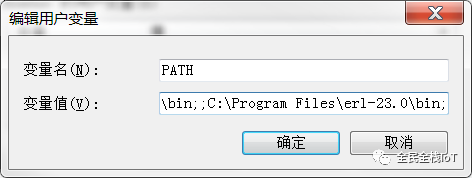
2、配置环境变量,这边以windows为例
3、在cmd中输入erl,如果出现以下提示,表示安装成功

4、进入Rabbitmq官网https://www.rabbitmq.com/install-windows.html下载对应的版本。然后进行安装,同样添加环境变量
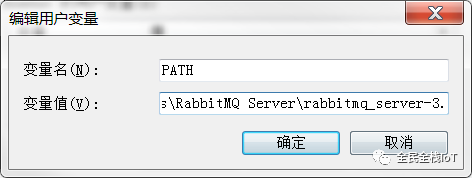
5、在cmd命令界面运行rabbitmq-plugins enable rabbitmq_management来添加可视化插件,然后进入安装目录sbin文件夹下面有很多运行脚本。
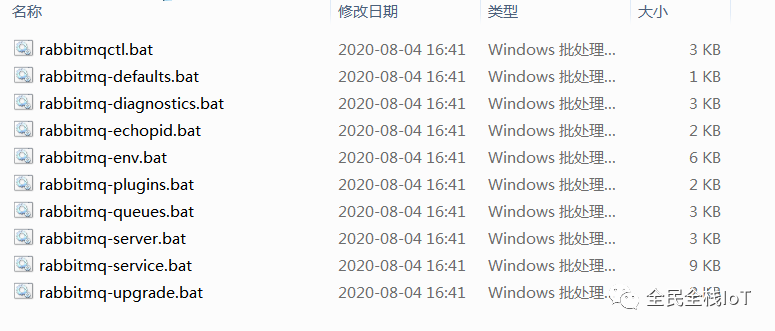
双击rabbitmq-server.bat进行服务重启,然后启动rabbitmq
rabbitmq启动方式有2种
1、以应用方式启动
rabbitmq-server -detached 后台启动
Rabbitmq-server 直接启动,如果你关闭窗口或者需要改窗口时使用其他命令时应用就会停止
关闭:rabbitmqctl stop
2、以服务方式启动(安装完之后在任务管理器中服务一栏能看到RabbtiMq)
rabbitmq-service install 安装服务
rabbitmq-service start 开始服务
Rabbitmq-service stop 停止服务
Rabbitmq-service enable 使服务有效
Rabbitmq-service disable 使服务无效
当rabbitmq-service install之后默认服务是enable的,如果这时设置服务为disable的话,rabbitmq-service start就会报错。
当rabbitmq-service start正常启动服务之后,使用disable是没有效果的
关闭:rabbitmqctl stop
3、Rabbitmq 管理插件启动,可视化界面
rabbitmq-plugins enable rabbitmq_management 启动
rabbitmq-plugins disable rabbitmq_management 关闭
03
—
Rabbitmq消息生产和消费示例
producer.py
import pika
# 建立一个实例
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost',5672) # 默认端口5672,可不写
)
# 声明一个管道,在管道里发消息
channel = connection.channel()
# 在管道里声明queue
channel.queue_declare(queue='test',durable=True)
# RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='test', # queue名字
body='Hello 物联全栈!'.encode('utf-8')) # 消息内容
print("Send 'Hello 物联全栈!'")
connection.close() # 队列关闭
登录RabbitMQ可视化界面可以看到Queues里面有一个test的队列,然后getmessages,可以看到我们生产的消息:

然后我们现在要读取队列里的消息,也就是消费消息,在这里我们每隔5秒去获取一下对应管道里的消息
import pika
# 建立一个实例
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost',5672) # 默认端口5672,可不写
)
# 声明一个管道,在管道里发消息
channel = connection.channel()
# 在管道里声明queue
channel.queue_declare(queue='test',durable=True)
# RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='test', # queue名字
body='Hello 物联全栈!'.encode('utf-8')) # 消息内容
print("Send 'Hello 物联全栈!'")
connection.close() # 队列关闭

03
—
Rabbitmq的绑定和路由
绑定(binding)是指交换机(exchange)和队列(queue)的关系。可以简单理解为:这个队列(queue)对这个交换机(exchange)的消息感兴趣。
绑定的时候可以带上一个额外的routing_key参数。为了避免与basic_publish的参数混淆,我们把它叫做绑定键(binding key)。绑定键的意义取决于交换机(exchange)的类型。
我们将会使用直连交换机(direct exchange)来进行试验。路由的算法很简单 —— 交换机将会对绑定键(binding key)和路由键(routing key)进行精确匹配,从而确定消息该分发到哪个队列。
下图能够很好的描述这个场景:
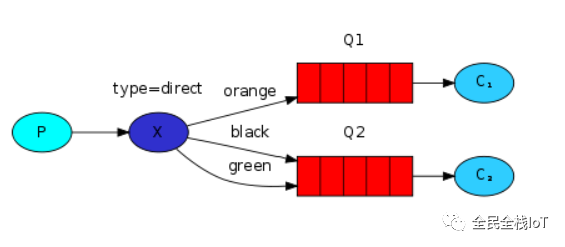
在这个场景中,我们可以看到直连交换机 X和两个队列进行了绑定。第一个队列使用orange作为绑定键,第二个队列有两个绑定,一个使用black作为绑定键,另外一个使用green。
这样一来,当路由键为orange的消息发布到交换机,就会被路由到队列Q1。路由键为black或者green的消息就会路由到Q2。其他的所有消息都将会被丢弃。
多个队列使用相同的绑定键是合法的。下图中,我们可以添加一个X和Q1之间的绑定,使用black绑定键。这样一来,直连交换机就和扇型交换机的行为一样,会将消息广播到所有匹配的队列。带有black路由键的消息会同时发送到Q1和Q2。

生产消息到路由
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
#声明一个路由
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
#定义一个绑定键
route_key = 'exchange_test'
message = 'Hello 物联全栈!'
channel.basic_publish(exchange='direct_logs',
routing_key=route_key,
body=message.encode('utf-8'))
print ("Producer Sent to Exchange {}{}".format(route_key, message))
connection.close()

从路由消费消息
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result = channel.queue_declare(exclusive=True,queue='test_exchange')
queue_name = result.method.queue
route_key = 'exchange_test'
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=route_key)
print( 'Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print ("The message from routing_key {} is {}" .format (method.routing_key, body.decode('utf-8'),))
channel.basic_consume(queue_name,callback,auto_ack=True)
channel.start_consuming()

03
—
远程过程调用RPC
如果我们需要将一个函数运行在远程计算机上并且等待从那儿获取结果时,该怎么办呢?这种模式通常被称为远程过程调用(Remote Procedure Call)或者RPC。使用RabbitMQ来构建一个RPC系统:包含一个客户端和一个RPC服务器。现在的情况是,我们没有一个值得被分发的足够耗时的任务,所以接下来,我们会创建一个模拟RPC服务来返回一个字符串,当然这有点大材小用,当然还是能起到演示的效果。
AMQP协议给消息预定义了几个属性可以用来构建RPC系统:
delivery_mode(投递模式):将消息标记为持久的(值为2)或暂存的(除了2之外的其他任何值)。第二篇教程里接触过这个属性,记得吧?
content_type(内容类型):用来描述编码的mime-type。例如在实际使用中常常使用application/json来描述JOSN编码类型。
reply_to(回复目标):通常用来命名回调队列。
correlation_id(关联标识):用来将RPC的响应和请求关联起来。
上边介绍的方法中,我们建议给每一个RPC请求新建一个回调队列。这不是一个高效的做法,幸好这儿有一个更好的办法 —— 我们可以为每个客户端只建立一个独立的回调队列。
这就带来一个新问题,当此队列接收到一个响应的时候它无法辨别出这个响应是属于哪个请求的。correlation_id 就是为了解决这个问题而来的。我们给每个请求设置一个独一无二的值。稍后,当我们从回调队列中接收到一个消息的时候,我们就可以查看这条属性从而将响应和请求匹配起来。如果我们接收到的消息的correlation_id是未知的,那就直接销毁掉它,因为它不属于我们的任何一条请求。

我们的RPC如此工作:
1、当客户端启动的时候,它创建一个匿名独享的回调队列。
2、在RPC请求中,客户端发送带有两个属性的消息:一个是设置回调队列的 reply_to 属性,另一个是设置唯一值的 correlation_id 属性。
3、将请求发送到一个 rpc_queue 队列中。
4、RPC工作者(又名:服务器)等待请求发送到这个队列中来。当请求出现的时候,它执行他的工作并且将带有执行结果的消息发送给reply_to字段指定的队列。
5、客户端等待回调队列里的数据。当有消息出现的时候,它会检查correlation_id属性。如果此属性的值与请求匹配,将它返回给应用。
rpc_server
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def test_rpc():
return "this is test_rpc"
def on_request(ch, method, props, body):
response = test_rpc()
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume('rpc_queue',on_request)
print ("Awaiting RPC requests")
channel.start_consuming()
rpc_client
import pika
import uuid
class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True,queue='')
self.callback_queue = result.method.queue #随机生成queue
self.channel.basic_consume(self.callback_queue,self.on_response, auto_ack=True,
)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body='')
while self.response is None:
self.connection.process_data_events()
return str(self.response)
rpc = RpcClient()
print ("RPC send")
response = rpc.call()
print ("the rpc response is {}".format(response))
我们通过发送rpc请求,并且rpc_server返回了我们想要的结果

听说关注公众号的都是大牛
















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









