







Spark MLlib
Spark MLlib简介
- 算法与模型:没有经过数据训练之前的是算法,训练后的是模型
- spark机器学习:突破传统机器学习算法的单机限制,使用分布式计算框架,对全局数据进行机器学习


- MLlib库包括:分类、回归、聚类、协同过滤、降维
- 特征化工具:特征提取、转化、降维
- 机器学习不同的包:
- spark.mllib:基于RDD的数据抽象
- spark.ml:基于DataFrame的数据抽象,可以将spark SQL与机器学习库融合,所以较为常用

机器学习流水线(pipeline)
一个比较完整度咋的机器学习任务,一般使用过多个阶段构成流水线来完成的,另外会提供持久性,可以保存和加载算法、模型,上面的流水线都可以保存起来,下次直接使用
流水线的概念
-
采用DataFrame结构化的数据表作为抽象
-
transformer(转化器):可以将输入数据封装为一个DataFrame,传入转换器,转换器对DataFrame进行打标签操作后再输出。也就是将一个DataFrame转换成另一个DataFrame。转换器通过训练获得,本质上就是一个模型
-
Transform() 转化器的方法
-
Estimator评估器,估计器:一个算法,评估器对DataFrame数据进行操作后,得到一个转换器
-
fit()方法:评估器实现了fit方法,数据封装到DataFrame后,将DataFrame传给fit()方法,它会自动使用数据进行训练,得到一个模型(转换器)
-
PipeLine流水线(管道):转换器与估计器之间反复组合,形成一个非常犊砸的机器学习流水线
-
构建Pipeline流水线:
-
定义Pipeline中的各个流水线阶段PipelineStage(包括转换器、评估器)
-
按照处理逻辑,将转换器和评估器有序地组织起来构成Pipeline
-
先通过new Pipeline()生成流水线‘,再调用**setStage()**方法,将流水线各个节点的名称传给它,生成一个Pipeline。
val pipeline = new Pipeline().setStage(Array(stage1,stage2,stage3...)) -
流水线本身不是一个模型,本质上很多时候是个评估器,所以需要对流水线使用fit()方法输入原始数据去训练,从而得到流水线模型 PipeLine Model,是pipelineMode类的一个示例,可以用来预测相关数据
-
构建机器学习流水线
示例:逻辑回归:找出所有包含spark的句子(包含则打为1,否则为0)
- 构架SparkSession对象
SparkSession.builder().master("local").appName("xx").getOrCreate() - 导入包并构建训练数据集

- 根据任务需求,构建pipelineStage(可能是转换器,也可能是评估器)






传入测试数据,生成模型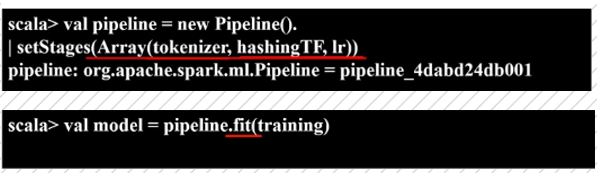


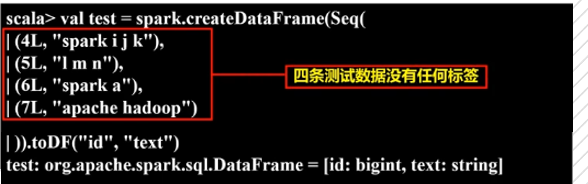
4. 构建测试数据,转化成DataFrame




















 8121
8121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









