







Spark安装环境准备
操作系统准备
Spark是运行在JVM上的,JVM是跨平台的,所以Spark可以跨平台运行在各种类型的操作系统上。但是在实际使用中,通常都将Spark安装部署在Linux服务器上,所以需要准备好用来安装Spark的Linux服务器,这里以Ubuntu20.04作为目标操作系统。
- 在本地模式下,需要1台服务器
- 在Standalone模式下,至少需要3台服务器
- 在Yarn模式下,至少需要3台服务器
- 在云环境模式下,不需要自己准备服务器,在创建集群的时候可以选择集群规模需要多少节点
在自己安装部署的环境中,无论是1台服务器还是多台服务器,都做统一的规划:操作系统用户统一使用hadoop、软件安装目录统一使用${HOME}/apps,所以需要在系统中创建hadoop用户并在hadoop用户的home目录下创建apps目录。

Java环境准备
由于Spark是由Scala语言编写,需要在JVM环境下运行,所以需要在安装Spark的服务器上安装并配置Java。根据集群的规划,需要给集群中的每一个节点都安装Java环境,并且需要安装Java8+以上的版本。在Ubuntu操作系统中,可以执行以下命令进行Java8的安装。
sudo apt-get update
sudo apt install -y openjdk-8-jdk
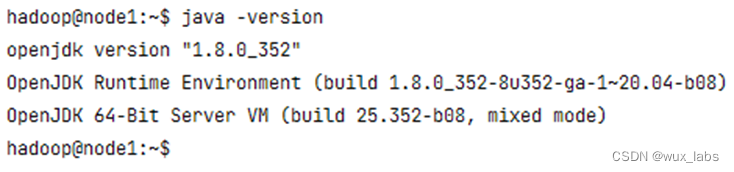
安装完成后可以执行java -version命令来检查安装结果及相关版本。
Python环境准备
Spark提供了对Python的支持,提供了PySpark包,这里以Python作为主要开发语言,所以在服务器环境中需要安装Python3。Linux服务器通常自带Python环境,自带的Python环境有可能是Python2,也有可能是Python3,如果自带的环境是Python2,那么需要重新安装Python3的环境,推荐使用Anaconda3进行安装。Anaconda的安装可参考官方文档https://docs.anaconda.com/anaconda/install/linux/。
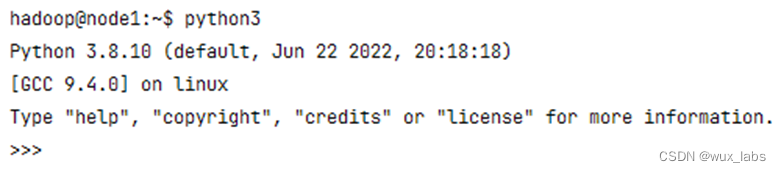
安装完成以后,确保服务器上执行python3命令不会报错。
Spark安装包下载
在安装Spark之前,需要从其官方网站下载Spark的安装包。
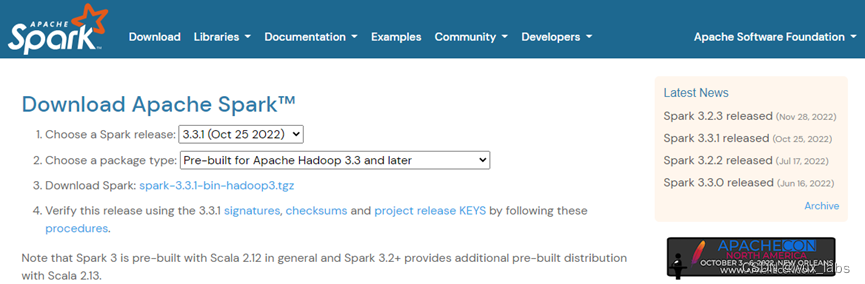
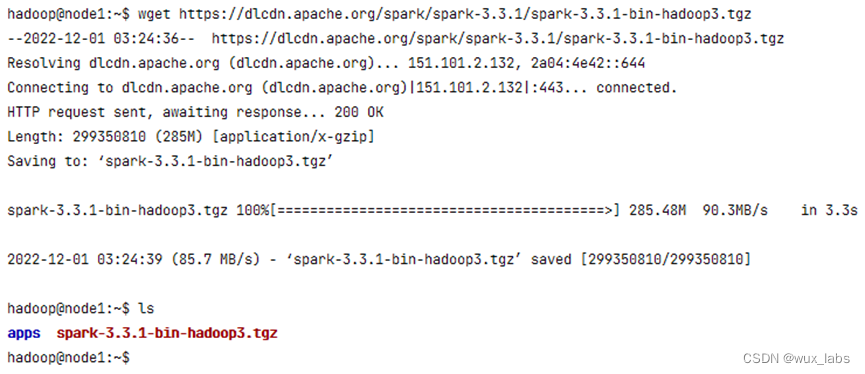
可以直接点击下载链接将安装包下载到本地,然后将安装包上传到需要安装Spark的Linux服务器上进行安装。也可以复制下载链接,然后在需要安装Spark的Linux服务器上通过wget等命令进行安装包的下载。
wget https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
Hadoop安装包下载
数据文件通常存放于HDFS分布式文件系统,Spark On Yarn模式的部署依赖Yarn,这些都需要用到Hadoop集群,所以需要下载Hadoop安装包。通过Hadoop的官网下载Hadoop 3.3.x版本。
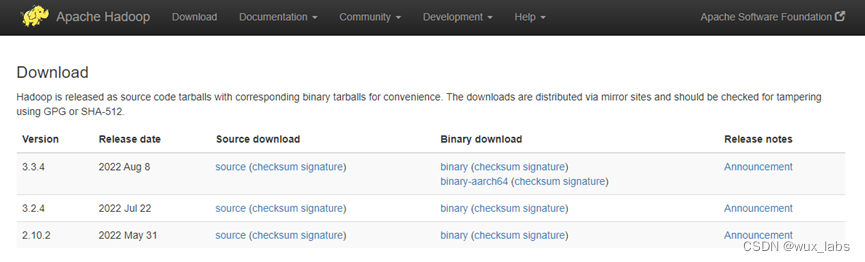
可以直接点击下载链接将安装包下载到本地,然后将安装包上传Linux服务器上进行安装。也可以复制下载链接,然后在Linux服务器上通过wget等命令进行安装包的下载。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
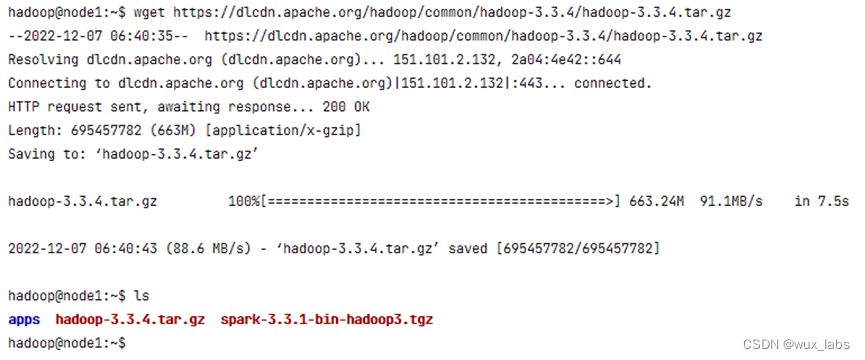
至此,基础环境准备完成。















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











