







说起正则化,不得不先说过拟合。首先我们先看西瓜书书里的解释。
经验误差与过拟合问题
通常我们吧分类错误的样本数占样本总数的比例较“错误率”(error rate),即如果在m个样本中有a个样本分类错误,则错误率E=a/m;相应1-a/m为“精度”(accuracy),即“精度=1-错误率”。一般来说,把学习器的实际预测输出与样本的真实输出之间的差异称为“误差”(error),学习器在训练集上的误差称为“训练误差”(training error)或者叫“经验误差”,在新样本上的误差叫“泛化误差”。过拟合(overfitting)的意思就是学习器把训练样本学的“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所以潜在样本都会具有的一些性质,导致泛化性能下降。为了是学习器不总是过拟合,就要给它添加一下项防止过拟合,正则化就应运而生了。
正则化
之前看了不少博客我也稍微总结一下,有什么不对的地方还望指正!
L0范数是向量中非0的元素个数。原则上说是个数越少越好。但是L0范数不连续,难以优化求解,这时候L1范数就出来了。L1范数是向量中各个元素绝对值之和,也叫“稀疏规则算子”,就是大名鼎鼎的LASSO(Lease Absolute Shrinkage and Selection Operator,直译就是“最小绝对收缩选择算子”,没错,很直译!)为什么L1范数就比L0好使呢?PS:为什么要稀疏?参考这篇博客机器学习中的范数
L2范数是标识各个参数的平方的和。
引用一张非常著名的图:
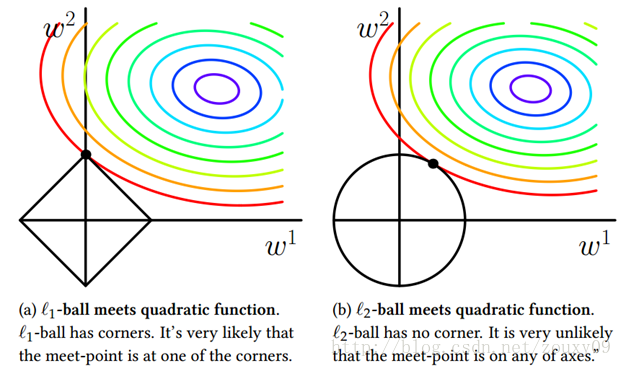
由图上可以看出,L1正则化可以在区域的角附近取得最优值,而角也就意味着有一个或者多个参数值为0,这就实现了稀疏化。而L2正则因为是球域,在坐标轴相交的可能性大大减小,因此没有稀疏性。在看哈,采用L1范数时交点在坐标轴上,而L2在交点在某个象限内,换言之L1比L2更易于得到稀疏解。
坐标下降法:
我们的优化目标就是在θ的n个坐标轴上(或者说向量的方向上)对损失函数做迭代的下降,当所有的坐标轴上的θi(i = 1,2,…n)都达到收敛时,我们的损失函数最小,此时的θ即为我们要求的结果。
坐标下降优化方法是一种非梯度优化算法。为了找到一个函数的局部极小值,在每次迭代中可以在当前点处沿一个坐标方向进行一维搜索。在整个过程中循环使用不同的坐标方向。一个周期的一维搜索迭代过程相当于一个梯度迭代。
坐标下降法基于最小化多变量目标函数可以通过每次沿一个方向最小化目标函数来求解。与梯度方法的变化的梯度方向不同,坐标下降方法固定其他的梯度方向。例如,坐标方向为e1,e2,…,en。每次沿一个坐标方向最小化目标函数,循环地沿每个坐标方向进行计算。具体可以参考坐标下降法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









