









山东大学软件学院2022-2023第二学期多核平台上的并行计算期末考试(回忆版)
前言
1、考试时间:2023/5/30 8:00-10:00
2、考试科目:多核平台上的并行计算(老师:LiuWeiGuo)
3、考题语言:中文
4、考试形式:闭卷
5、考后感悟:考试题目都是最后的复习PPT上的,没有一点变化,题目很简单,只要提前背一下理解了就行。开考45分钟就开始陆续交卷(老师强调不要开考30分钟就交卷hhh),一个小时的时候只剩10个人左右。
一、
如图,MPI_reduce集合通讯中,Process1调用次序出错。
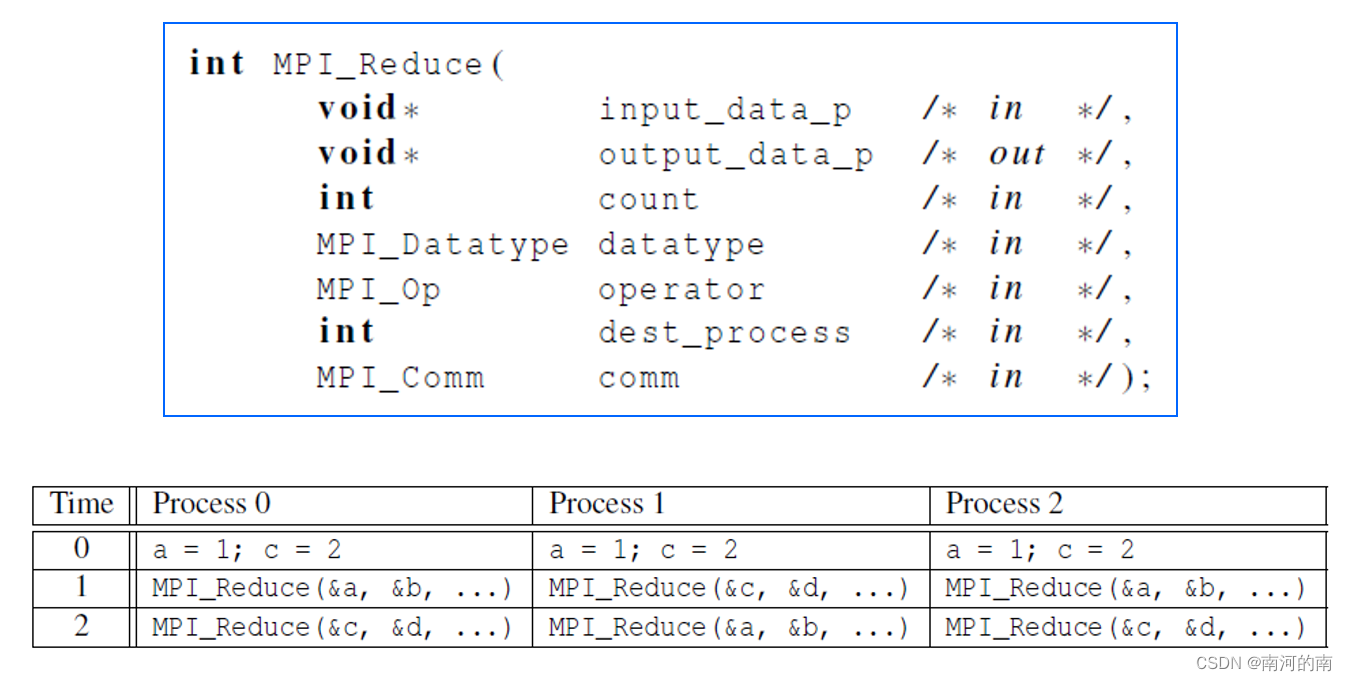
如果dest_process为0,b、d都初始化为0,求进行MPI_reduce后,b和d的值。
答:b = a+c+a = 1+2+1 = 4
d = c+a+c = 2+1+2 = 5
二、
在冯·诺依曼系统中加人缓存和虚内存改变了它作为 SISD 系统的类型吗?如果加人流水线呢?多发射或硬件多线程呢?
答:①加人缓存和虚内存不会改变系统的SISD类型。因为缓存和虚内存的加入没有改变一次可以执行的指令数或者一次可以操作的数据量,因此系统仍为SISD类型。
②加入流水线会使得系统变为SIMD类型。因为加入流水线相当于将一个指令应用于多个数据项,也就是SIMD。
③多发射和硬件多线程会使得系统变为MIMD类型。因为多发射相当于一个指令流在多个ALU上同时启动一部分,分裂为多个指令流,多个指令流用于不同的数据项,就是MIMD。硬件多线程是指当前任务被阻塞时,系统尝试切换到其他线程继续工作,这允许了多线程的存在,多个指令流用于不同的数据项,也是MIMD。
三、
当讨论矩阵 -向量乘法时,我们通常假设 m 和n,即矩阵的行数和列数,都能够被 t 整除,t 是线程的个数。但是,如果 m 和 n 不满足能被 t 整除的条件,那么用什么公式来分配数据?

答:
quotient = n/p;
remainder = n%p;
if(my_rank<remainder){
my_n_count = quotient+1;
my_first_i = myrank*my_n_count;
}else{
my_n_count = quotient;
my_first_i = my_rank*my_n_count+remainder;
}
my_last_i = my_first_i+my_n_count-1;
四、
如果已经定义了宏_OPENMP,它是一个 int 类型的十进制数。编写一个程序打印它的值。这个值的意义是什么?
答:"_OPENMP" 是一个预处理器宏定义,用于标识 OpenMP 版本。_OPENMP的值是一个具有yyyymm形式的日期。OpenMP标准规定,当定义宏时,它将是已实现的OpenMP标准版本的年份和月。
五、
当讨论浮点数加法时,我们简单地假设每个功能单元都花费相同的时间。如果每个取命令与存命令都耗费2纳秒,其余的每个作耗费1纳秒。
a.非流水线1000对浮点数的加法要耗费多少时间?
b.流水线 1000对浮点数加法要耗费多少时间?
| Stage | Fetch | Compare | Shift | Add | Normalize | Round | Store |
|---|---|---|---|---|---|---|---|
| Time | 2 | 1 | 1 | 1 | 1 | 1 | 2 |
答:a.1000×(2+1+1+1+1+1+2)=9000 ns
b.2×1000 + (1+1+1+1+1+2)=2007 ns
六、下面的代码存在两处错误,请指出错误,给出原因并纠正。
// Compute sum of length-N vectors:C=A+B
void _global_
vecAdd (float* a, float* b, float* c, int N)
{
int i = blockIdx.x * grimDim.x + threadIdx.x;
if (i < N) c[i] = a[i] + b[i];
}
int main () {
int N = ...;
float *a,*b,*c;
cudaMalloc (&a,sizeof(float) * N);
//...allocate other arrays, fill with data
// Use thread blocks with 256 threads each
vecAdd <<< N/256,256 >>> (a, b,c,N);
}
答:①第四行计算i时出错,不能使用grimDim.x。
原因: i是全局的标号,应该由线程所在的块的标号blockIdx.x 乘以块的维度blockDim.x,然后再加上局部的线程号threadIdx.x求的。
第四行纠正后代码: int i = blockIdx.x * blockDim.x + threadIdx.x;
②倒数第二行调用vecADD时传入第一个参数出错, 不能使用N/256。
原因: vecADD<<<grid_size, block_size > >>执行配置的第一个参数是网格维度,也就是启动块的数目。第二个参数是块维度,也就是每个块中线程的数目。需要保证第一个参数大于等于1。由于N是向量的长度,故N≥1。而使用N/256不能保证vecADD第一个参数大于等于1,因此出错。应当使用(N+255)/256,使得N+255恒大于等于256,那么vecADD<<< >>>的第一个参数(N+255)/256就恒大于等于1。
倒数第二行纠错后代码: vecAdd <<< (N+255)/256,256 >>> (a, b,c,N);
七、
指出下面代码有哪些性能问题?指出原因并给出改进后的代码。
__global__ void reduce0(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
答:
①性能问题:%操作运算效率慢。
原因: %操作符在Cuda中被编译成20多条指令,运算速度慢,性能下降。
改进: 将%操作符改为乘法运算。
②性能问题:warp分支严重。
原因: Cuda 的 GPU 采用了 SIMT 架构,所以无法让同一 warp 的线程执行不同指令;如图1,if判断会使warp中偶数号线程运行,奇数号线程空闲,导致warp分支严重,性能下降。
改进: 将if判断语句改为index<blockDim.x,其中index = 2*s*tid。这样会使得同一个warp中的线程统一执行或统一不执行该语句,如图2,同一warp都执行了0、1、……7线程,没有执行8、9、……线程。这样就会提高性能。


for循环改进后的代码如下:
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
结尾
本次考试很简单,考的内容都是最后的复习ppt上的,最后一节课老师带着复习的时候很重要,最好就是录一下音,这样便于理解和复习。
参考文章:
1、山东大学2022-2023多核复习课题目答案整理/往年题整理
2、【山东大学】多核平台下的并行计算——复习笔记
















 6132
6132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











