







DL图像增强方法–《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks,2017》
这篇文章提出了一个End-to-End的的DL方法,将普通的图片转化成单反质量的图片。论文内容介绍:http://www.vision.ee.ethz.ch/~ihnatova/ 要点:
- 使用残差卷积网学习translation function,以此改进颜色效果,并提升图像的锐化效果;
- 结合内容,颜色以及纹理损失,提出组合的感知误差函数;前两种损失有相应的解析式,纹理损失从对抗网络中学习;
- 提供了一个数据集DPED,其中包含了三种不同类型的手机拍摄出的相对低质量的图片,以及单反拍出的高质量的图片。
数据集DPED
论文作者分别使用三种设备,Sony smartphone, iPhone, BlackBerry 采集了4549张, 5727张,6015张低(quality: iphone < blackberry < sony)质量图片,并用Canon采集了6015张高质量图片。绝大部分的图片都是同时同地采集的,但由于不同的设备收集到的图片不一定是对齐的,所以需要将图片对齐。方式是,对每一个(Phone-DSLR) 图片对,针对SIFT描述子匹配的关键点,采用RANSAC估计单应性? ,最后裁剪,缩放(DSLR图片往往是downscale)得到两张具有相同尺寸,相同场景的图片。数据集的下载网址:http://www.vision.ee.ethz.ch/~ihnatova/
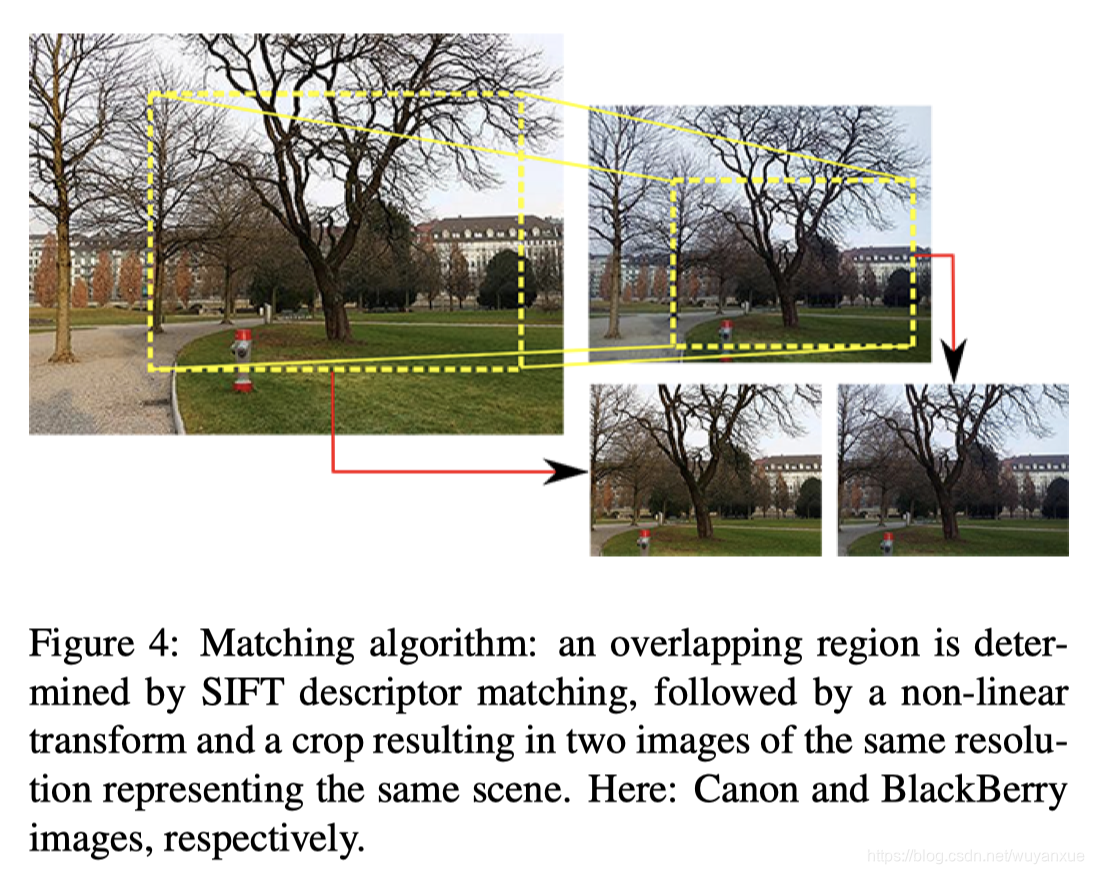
训练网络所使用的输入
直接采用高分辨率的图像作为网络的输入是不可行的。因此,使用从原图中抽取的100x100px大小的image patches。文章作者验证过,更大的patch尺寸不会使得结果更好。100x100px的patches是通过不相交的滑窗(sliding window)实现的,并行的在iphon-DSLR pair上进行,取出的patch pair再做Augmentation,最终生成了139K, 160k, 162k的训练集(分别对应BlackBerry-Canon, iphone-Canon, Sony-Canon)。和2.4k-4.3k的测试集。

Loss
本文的任务是:给定一个低质量的图片 I s I_s Is,目标是重构出DSLR所拍摄出的高质量图片 I t I_t It。文章用了一个深度残差CNN参数化这个重构函数的权重 W W W。
W = a r g m i n W 1 N ∑ j = 1 N L ( F W ( I s j ) , I t j ) W = argmin_{W} \frac{1}{N} \sum_{j=1}^N L(F_W(I_s^j), I_t^j) W=argminWN1∑j=1NL(FW(Isj),Itj)
图像增强Task的主要难点是输入图像和目标图片不可能精确到pixel2pixel级的,因此作者考虑三个方面感知图像的质量,分别是颜色质量,纹理质量和内容质量。这三部分的损失共同构成了 L L L。
Color Loss
为了度量model生成的图片和GT之间的颜色损失,作者并不是直接计算两张图片的Euclidean distance,而是对生成结果和GT分别做了Gaussian blur操作。表现在网络里面则相当于在顶层加了一个fix的convolutional kernel。
L c o l o r ( X , Y ) = ∣ ∣ X b − Y b ∣ ∣ F 2 L_{color}(X, Y) = ||X_b - Y_b||_F^2 Lcolor(X,Y)=∣∣Xb−Yb∣∣F2
其中 X b , Y b X_b, Y_b Xb,Yb分别是模糊后的生成结果和GT。原论文写的是矩阵的2范数,结合源代码可知是作者写错了,应该是矩阵的F范数。
Texture Loss
纹理损失由GAN来直接学习,用于度量纹理质量。
L t e x t u r e = − ∑ i l o g D ( F W ( I s ) , I T ) L_{texture} = -\sum_i log D(F_W(I_s), I_T) Ltexture=−∑ilogD(FW(Is),IT)
其中 F W F_W FW和 D D D分别表示生成器和判别器。判别器被用到灰度图,所以它的目标主要在纹理上的处理。判别器观察fake和real两张图片,目标是预测哪张图片是真的,哪张图片是假的。判别器训练是最小化交叉熵损失。判别器是在phon-DSLR图片对上进行预训练的,然后结合生成网络联合训练。这个损失函数具有shift-invariant性质。
Content Loss
类似地,这种方法并不是比较pixel2pixel的差异性。而是鼓励生成图片和GT具有相似的特征表示,这种特征表示可以综合内容和感知质量,由VGG-19的ReLU层产生这种特征表示。在本文中,它被用来保持图片的语义信息,因为其他的损失并没有考虑这一点。
L c o n t e n t = 1 C j H j W j ∣ ∣ ϕ j ( F W ( I s ) ) − ϕ j ( I t ) ∣ ∣ L_{content} = \frac{1}{C_jH_jW_j} ||\phi_j (F_W(I_s)) - \phi_j(I_t)|| Lcontent=CjHjWj1∣∣ϕj(FW(Is))−ϕj(It)∣∣
其中 ϕ j \phi_j ϕj表示VGG-19的第 j层卷积网激活后的feature maps,作者选用了VGG-19网络的relu_5_4层作为这里的feature representations。
Total variation loss
在前面loss的基础上,作者加入了一个total variation loss,用于增强生成图片的空间域平滑性。
L t v = 1 C H W ∣ ∣ ∂ x F W ( I s ) + ∂ y F W ( I s ) ∣ ∣ L_{tv} = \frac{1}{CHW} ||\partial_{x} F_W(I_s) + \partial_{y} F_W(I_s)|| Ltv=CHW1∣∣∂xFW(Is)+∂yFW(Is)∣∣
由于相对比较低的权重,这个损失并不会非常影响图像的高频部分,但对去除椒盐噪声有比较有效。
Total Loss
最终的损失为:
L
=
L
c
o
n
t
e
n
t
+
0.4
∗
L
t
e
x
t
u
r
e
+
0.1
∗
x
L
c
o
l
o
r
+
400
∗
L
t
v
L = L_{content} + 0.4 * L_{texture} + 0.1*x L_{color} + 400 * L_{tv}
L=Lcontent+0.4∗Ltexture+0.1∗xLcolor+400∗Ltv。
超参数是通过实验调整得到的。
Networks
本文的网络结构如下:
![[外链图片转存失败(img-fPFb9Cly-1568210525767)(网络结构.png)]](https://i-blog.csdnimg.cn/blog_migrate/28537ad4ea75a766e30eb49fe0628e3f.png)
可以看到,在增强网络部分,经过9x9x64卷积核处理,随后经过4个residual blocks,随后紧跟两个3x3x64x64卷积核和9x9x64x3卷积核,前面的激活函数都是relu,最后一层的激活函数是tanh。输出结果为和输入形状一样的三通道图像。tanh的主要目的是将像素值归一化到(-1, 1)。
增强网络部分分别计算 L c o l o r L_{color} Lcolor和 L t v L_{tv} Ltv损失。
判别网络部分由5层卷积层构成,需要注意其输入是灰度图,作者将输入的Target image和enhanced image做了灰度化处理,并且一个batch的输入由一个batch的target和一个batch的enhanced图片随机混合。判别器需要判别这个batch里面哪些图片是target,哪些图片是enhanced,—直到无法判别这两部分的图片。
判别网络部分的texture loss被定义为
L
t
e
x
t
u
r
e
=
−
c
r
o
s
s
_
e
n
t
r
o
p
y
_
l
o
s
s
(
y
1
,
y
2
)
L_{texture} = -cross\_entropy\_loss(y_1, y_2)
Ltexture=−cross_entropy_loss(y1,y2)
其中 y 1 y_1 y1和 y 2 y_2 y2分别是这批图片的真实和预测标签(target or enhanced)。笔者看了源代码才明白,判别网络部分的损失是交叉熵损失函数的负数,即它不是要极小化真实标签和预测标签之间的差异性,而是尽可能极大化这种差异性。这是因为,生成器的目的是要产生尽可能与真实DSLR图像接近的图像,当判别器无法判别这两者之间的差异性时,也就意味着生成器产生的效果是比较好的。
存疑:原文中有提到说判别器网络会在phone-DSLR图片对上进行预训练,然后再与生成器网络联合训练,但源代码中没有显式的判别器网络的预训练过程,是直接联合训练的。
https://github.com/aiff22/DPED/issues/17 这个issue里面作者回答了这一点,确实没有预训练的过程,如果需要判别器预训练的过程,那么可以
Regarding discriminator pre-training - you can remove the texture (discriminator) loss from the generator's total loss for the first 1K-2K iterations, while still training them simultaneously.
最后是一个VGG-19的网络结构用于提取图片特征,衡量 L c o n t e n t L_{content} Lcontent损失。
作者也给出了这个模型的一些不足:1. 颜色偏差; 2. 高对比度, 可能看起来像人工生成的图片; 3. 尽管增强了图片本身的高频部分,但是也增强了噪声。
代码解读
代码地址:https://github.com/aiff22/DPED
训练过程
训练过程的主函数在train_model.py这个文件里面,用法为
python train_model.py model=<model>
可选参数为:
batch_size: 50 - 一批数据的样本个数 [smaller values can lead to unstable training]
train_size: 30000 - the number of training patches randomly loaded each eval_step iterations 每个评价步骤中所使用的
eval_step: 1000 - each eval_step iterations the model is saved and the training data is reloaded
num_train_iters: 20000 - the number of training iterations
learning_rate: 5e-4 - learning rate
w_content: 10 - the weight of the content loss
w_color: 0.5 - the weight of the color loss
w_texture: 1 - the weight of the texture [adversarial] loss
w_tv: 2000 - the weight of the total variation loss
dped_dir: dped/ - path to the folder with DPED dataset
vgg_dir: vgg_pretrained/imagenet-vgg-verydeep-19.mat - path to the pre-trained VGG-19 network
示例:
python train_model.py model=iphone batch_size=50 dped_dir=dped/ w_color=0.7
源码及对应的解释
# train_model.py
# python train_model.py model={iphone,sony,blackberry} dped_dir=dped vgg_dir=vgg_pretrained/imagenet-vgg-verydeep-19.mat
import tensorflow as tf # version: >= 1.0.1,+CUDA, cuDNN
from scipy import misc
import numpy as np
import sys
from load_dataset import load_test_data, load_batch
from ssim import MultiScaleSSIM # 结构相似性模块导入
import models # 导入模型结构
import utils
import vgg
# defining size of the training image patches,论文中说明该模型是以100x100的image path进行训练的
PATCH_WIDTH = 100
PATCH_HEIGHT = 100
PATCH_SIZE = PATCH_WIDTH * PATCH_HEIGHT * 3
# processing command arguments,获取控制台参数。
phone, batch_size, train_size, learning_rate, num_train_iters, \
w_content, w_color, w_texture, w_tv, \
dped_dir, vgg_dir, eval_step = utils.process_command_args(sys.argv)
np.random.seed(0) # 设置随机数种子方便复现实验结果
# loading training and test data
# 测试数据是ndarray格式,shape为(测试图片个数, 100*100*3)
# 需要注意的事,加载这部分数据是把图片flatten了的,并且归一化到[0,1]区间。
# float16
print("Loading test data...")
test_data, test_answ = load_test_data(phone, dped_dir, PATCH_SIZE)
print("Test data was loaded\n")
# 加载一个batch的数据,注意这里train_size默认是30000,这表明会随机加载30000张训练图片,将每张图片flatten,并且归一化到[0,1]区间。
# float16
print("Loading training data...")
train_data, train_answ = load_batch(phone, dped_dir, train_size, PATCH_SIZE)
print("Training data was loaded\n")
TEST_SIZE = test_data.shape[0]
num_test_batches = int(test_data.shape[0]/batch_size)
# defining system architecture
# 默认计算图,开启tensorflow会话
with tf.Graph().as_default(), tf.Session() as sess:
# 定义图结构部分
# placeholders for training data
# 设置训练数据的输入placeholder
phone_ = tf.placeholder(tf.float32, [None, PATCH_SIZE])
# 由于网络的输入是形状为NxHxWxC的Tensor,因此需要把原始flatten的patch进行reshape
phone_image = tf.reshape(phone_, [-1, PATCH_HEIGHT, PATCH_WIDTH, 3])
# ground-truth图像,也即需要生成的目标图像
dslr_ = tf.placeholder(tf.float32, [None, PATCH_SIZE])
# 最终生成的图片将结合dslr_image计算损失
dslr_image = tf.reshape(dslr_, [-1, PATCH_HEIGHT, PATCH_WIDTH, 3])
# 生成器生成的结果与GT图像混合(产生一个混合batch,以训练判别器),并给定该batch的真实标签adv_,0表示为生成器生成的结果,1表示gt。
# shape: [N, 1]
adv_ = tf.placeholder(tf.float32, [None, 1])
# 训练数据过生成器部分以获得增强后的图片 --> enhanced
# shape = [N, H, W, 3]
enhanced = models.resnet(phone_image)
# 判别器的训练数据为灰度图像。tf.image.rgb_to_grayscale函数将RGB图像转化为灰度图
enhanced_gray = tf.reshape(tf.image.rgb_to_grayscale(enhanced), [-1, PATCH_WIDTH * PATCH_HEIGHT])
dslr_gray = tf.reshape(tf.image.rgb_to_grayscale(dslr_image),[-1, PATCH_WIDTH * PATCH_HEIGHT])
# 随机混合enhanced images与dslr images
# 1 - adv_由[N, 1]的shape被广播成了[N, H, W]结构。
adversarial_ = tf.multiply(enhanced_gray, 1 - adv_) + tf.multiply(dslr_gray, adv_)
adversarial_image = tf.reshape(adversarial_, [-1, PATCH_HEIGHT, PATCH_WIDTH, 1])
# 获得判别器的判别结果
discrim_predictions = models.adversarial(adversarial_image)
# losses
# 1) texture loss
# 判别器的学习目标,亦即gt labels,注意这里是做了ont hot。
discrim_target = tf.concat([adv_, 1 - adv_], 1)
# 判别器的损失,判别结果和学习目标的标准BCE loss
loss_discrim = -tf.reduce_sum(discrim_target * tf.log(tf.clip_by_value(discrim_predictions, 1e-10, 1.0)))
# 纹理损失=判别器损失的负数,原因在Loss一章中有讲解
loss_texture = -loss_discrim
correct_predictions = tf.equal(tf.argmax(discrim_predictions, 1), tf.argmax(discrim_target, 1))
# 判别器的预测精度,这个值应该越小越好
discim_accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))
# 2) content loss
CONTENT_LAYER = 'relu5_4'
# VGG-19网络的relu5_4层提取特征
# 需要注意vgg的输入需要对图像进行预处理,并没有进行微调,只用于提取特征。
enhanced_vgg = vgg.net(vgg_dir, vgg.preprocess(enhanced * 255))
dslr_vgg = vgg.net(vgg_dir, vgg.preprocess(dslr_image * 255))
# 获取tensor的size,比如一个tensor形状为[N, H, W, 3]
# content_size = N*H*W*3
# dslr_vgg[CONTENT_LAYER].get_shape()[i].value for i in range(1, 4)
content_size = utils._tensor_size(dslr_vgg[CONTENT_LAYER]) * batch_size
# 计算向量的欧式距离
loss_content = 2 * tf.nn.l2_loss(enhanced_vgg[CONTENT_LAYER] - dslr_vgg[CONTENT_LAYER]) / content_size
# 3) color loss
# 对图像进行模糊
enhanced_blur = utils.blur(enhanced)
dslr_blur = utils.blur(dslr_image)
# 计算矩阵的F范数,注意这里不能用l2_loss。
loss_color = tf.reduce_sum(tf.pow(dslr_blur - enhanced_blur, 2))/(2 * batch_size)
# 4) total variation loss
batch_shape = (batch_size, PATCH_WIDTH, PATCH_HEIGHT, 3)
tv_y_size = utils._tensor_size(enhanced[:,1:,:,:])
tv_x_size = utils._tensor_size(enhanced[:,:,1:,:])
# y方向差分
y_tv = tf.nn.l2_loss(enhanced[:,1:,:,:] - enhanced[:,:batch_shape[1]-1,:,:])
# x方向差分
x_tv = tf.nn.l2_loss(enhanced[:,:,1:,:] - enhanced[:,:,:batch_shape[2]-1,:])
loss_tv = 2 * (x_tv/tv_x_size + y_tv/tv_y_size) / batch_size
# final loss
loss_generator = w_content * loss_content + w_texture * loss_texture + w_color * loss_color + w_tv * loss_tv
# psnr loss
# 评价指标
enhanced_flat = tf.reshape(enhanced, [-1, PATCH_SIZE])
loss_mse = tf.reduce_sum(tf.pow(dslr_ - enhanced_flat, 2))/(PATCH_SIZE * batch_size)
loss_psnr = 20 * utils.log10(1.0 / tf.sqrt(loss_mse))
# optimize parameters of image enhancement (generator) and discriminator networks
# 需要训练的参数,只包括生成器参数和判别器参数
generator_vars = [v for v in tf.global_variables() if v.name.startswith("generator")]
discriminator_vars = [v for v in tf.global_variables() if v.name.startswith("discriminator")]
# 生成器的优化器
train_step_gen = tf.train.AdamOptimizer(learning_rate).minimize(loss_generator, var_list=generator_vars)
# 判别器的优化器
train_step_disc = tf.train.AdamOptimizer(learning_rate).minimize(loss_discrim, var_list=discriminator_vars)
# 存储生成器权重。
saver = tf.train.Saver(var_list=generator_vars, max_to_keep=100)
print('Initializing variables')
sess.run(tf.global_variables_initializer())
print('Training network')
# 生成器的训练损失
train_loss_gen = 0.0
# 判别器精度
train_acc_discrim = 0.0
all_zeros = np.reshape(np.zeros((batch_size, 1)), [batch_size, 1])
test_crops = test_data[np.random.randint(0, TEST_SIZE, 5), :]
logs = open('models/' + phone + '.txt', "w+")
logs.close()
# 默认20000次迭代
for i in range(num_train_iters):
# train generator
# 随机从原训练数据中产生一个batch的数据
idx_train = np.random.randint(0, train_size, batch_size)
phone_images = train_data[idx_train]
dslr_images = train_answ[idx_train]
# Stage 1. 训练生成器
[loss_temp, temp] = sess.run([loss_generator, train_step_gen],
feed_dict={phone_: phone_images, dslr_: dslr_images, adv_: all_zeros})
# 每迭代eval_step次,打印一次train_loss_gen的均值 / eval_step
train_loss_gen += loss_temp / eval_step
# Stage 2. 训练判别器
idx_train = np.random.randint(0, train_size, batch_size)
# generate image swaps (dslr or enhanced) for discriminator
swaps = np.reshape(np.random.randint(0, 2, batch_size), [batch_size, 1])
phone_images = train_data[idx_train]
dslr_images = train_answ[idx_train]
[accuracy_temp, temp] = sess.run([discim_accuracy, train_step_disc],
feed_dict={phone_: phone_images, dslr_: dslr_images, adv_: swaps})
train_acc_discrim += accuracy_temp / eval_step
if i % eval_step == 0:
# test generator and discriminator CNNs
test_losses_gen = np.zeros((1, 6))
test_accuracy_disc = 0.0
loss_ssim = 0.0
for j in range(num_test_batches):
be = j * batch_size
en = (j+1) * batch_size
swaps = np.reshape(np.random.randint(0, 2, batch_size), [batch_size, 1])
phone_images = test_data[be:en]
dslr_images = test_answ[be:en]
[enhanced_crops, accuracy_disc, losses] = sess.run([enhanced, discim_accuracy, \
[loss_generator, loss_content, loss_color, loss_texture, loss_tv, loss_psnr]], \
feed_dict={phone_: phone_images, dslr_: dslr_images, adv_: swaps})
test_losses_gen += np.asarray(losses) / num_test_batches
test_accuracy_disc += accuracy_disc / num_test_batches
# 计算结构相似性
loss_ssim += MultiScaleSSIM(np.reshape(dslr_images * 255, [batch_size, PATCH_HEIGHT, PATCH_WIDTH, 3]),
enhanced_crops * 255) / num_test_batches
logs_disc = "step %d, %s | discriminator accuracy | train: %.4g, test: %.4g" % \
(i, phone, train_acc_discrim, test_accuracy_disc)
logs_gen = "generator losses | train: %.4g, test: %.4g | content: %.4g, color: %.4g, texture: %.4g, tv: %.4g | psnr: %.4g, ssim: %.4g\n" % \
(train_loss_gen, test_losses_gen[0][0], test_losses_gen[0][1], test_losses_gen[0][2],
test_losses_gen[0][3], test_losses_gen[0][4], test_losses_gen[0][5], loss_ssim)
print(logs_disc)
print(logs_gen)
# save the results to log file
logs = open('models/' + phone + '.txt', "a")
logs.write(logs_disc)
logs.write('\n')
logs.write(logs_gen)
logs.write('\n')
logs.close()
# save visual results for several test image crops
enhanced_crops = sess.run(enhanced, feed_dict={phone_: test_crops, dslr_: dslr_images, adv_: all_zeros})
idx = 0
for crop in enhanced_crops:
before_after = np.hstack((np.reshape(test_crops[idx], [PATCH_HEIGHT, PATCH_WIDTH, 3]), crop))
misc.imsave('results/' + str(phone)+ "_" + str(idx) + '_iteration_' + str(i) + '.jpg', before_after)
idx += 1
train_loss_gen = 0.0
train_acc_discrim = 0.0
# save the model that corresponds to the current iteration
saver.save(sess, 'models/' + str(phone) + '_iteration_' + str(i) + '.ckpt', write_meta_graph=False)
# reload a different batch of training data
del train_data
del train_answ
train_data, train_answ = load_batch(phone, dped_dir, train_size, PATCH_SIZE)
网络结构
生成器结构
def resnet(input_image):
with tf.variable_scope("generator"):
W1 = weight_variable([9, 9, 3, 64], name="W1"); b1 = bias_variable([64], name="b1");
c1 = tf.nn.relu(conv2d(input_image, W1) + b1)
# residual 1
W2 = weight_variable([3, 3, 64, 64], name="W2"); b2 = bias_variable([64], name="b2");
# _instance_norm是BN函数
c2 = tf.nn.relu(_instance_norm(conv2d(c1, W2) + b2))
W3 = weight_variable([3, 3, 64, 64], name="W3"); b3 = bias_variable([64], name="b3");
c3 = tf.nn.relu(_instance_norm(conv2d(c2, W3) + b3)) + c1
# residual 2
W4 = weight_variable([3, 3, 64, 64], name="W4"); b4 = bias_variable([64], name="b4");
c4 = tf.nn.relu(_instance_norm(conv2d(c3, W4) + b4))
W5 = weight_variable([3, 3, 64, 64], name="W5"); b5 = bias_variable([64], name="b5");
c5 = tf.nn.relu(_instance_norm(conv2d(c4, W5) + b5)) + c3
# residual 3
W6 = weight_variable([3, 3, 64, 64], name="W6"); b6 = bias_variable([64], name="b6");
c6 = tf.nn.relu(_instance_norm(conv2d(c5, W6) + b6))
W7 = weight_variable([3, 3, 64, 64], name="W7"); b7 = bias_variable([64], name="b7");
c7 = tf.nn.relu(_instance_norm(conv2d(c6, W7) + b7)) + c5
# residual 4
W8 = weight_variable([3, 3, 64, 64], name="W8"); b8 = bias_variable([64], name="b8");
c8 = tf.nn.relu(_instance_norm(conv2d(c7, W8) + b8))
W9 = weight_variable([3, 3, 64, 64], name="W9"); b9 = bias_variable([64], name="b9");
c9 = tf.nn.relu(_instance_norm(conv2d(c8, W9) + b9)) + c7
# Convolutional
W10 = weight_variable([3, 3, 64, 64], name="W10"); b10 = bias_variable([64], name="b10");
c10 = tf.nn.relu(conv2d(c9, W10) + b10)
W11 = weight_variable([3, 3, 64, 64], name="W11"); b11 = bias_variable([64], name="b11");
c11 = tf.nn.relu(conv2d(c10, W11) + b11)
# Final
W12 = weight_variable([9, 9, 64, 3], name="W12"); b12 = bias_variable([3], name="b12");
enhanced = tf.nn.tanh(conv2d(c11, W12) + b12) * 0.58 + 0.5
return enhanced
# BN函数
def _instance_norm(net):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
var_shape = [channels]
mu, sigma_sq = tf.nn.moments(net, [1,2], keep_dims=True)
shift = tf.Variable(tf.zeros(var_shape))
scale = tf.Variable(tf.ones(var_shape))
epsilon = 1e-3
normalized = (net-mu)/(sigma_sq + epsilon)**(.5)
return scale * normalized + shift
判别器结构
def adversarial(image_):
with tf.variable_scope("discriminator"):
conv1 = _conv_layer(image_, 48, 11, 4, batch_nn = False)
conv2 = _conv_layer(conv1, 128, 5, 2)
conv3 = _conv_layer(conv2, 192, 3, 1)
conv4 = _conv_layer(conv3, 192, 3, 1)
conv5 = _conv_layer(conv4, 128, 3, 2)
flat_size = 128 * 7 * 7
conv5_flat = tf.reshape(conv5, [-1, flat_size])
W_fc = tf.Variable(tf.truncated_normal([flat_size, 1024], stddev=0.01))
bias_fc = tf.Variable(tf.constant(0.01, shape=[1024]))
fc = leaky_relu(tf.matmul(conv5_flat, W_fc) + bias_fc)
W_out = tf.Variable(tf.truncated_normal([1024, 2], stddev=0.01))
bias_out = tf.Variable(tf.constant(0.01, shape=[2]))
adv_out = tf.nn.softmax(tf.matmul(fc, W_out) + bias_out)
return adv_out
def _conv_layer(net, num_filters, filter_size, strides, batch_nn=True):
weights_init = _conv_init_vars(net, num_filters, filter_size)
strides_shape = [1, strides, strides, 1]
bias = tf.Variable(tf.constant(0.01, shape=[num_filters]))
net = tf.nn.conv2d(net, weights_init, strides_shape, padding='SAME') + bias
net = leaky_relu(net)
if batch_nn:
net = _instance_norm(net)
return net

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









