







1、引言
小鱼:今天难得小屌丝 出去玩了, 咱们今天干点正儿八经的事
小芸:嘿嘿,终于等到这一刻了
小鱼:额… 看样子你还蛮期待的哦
小芸:对啊, 难得能跟鱼哥一起做点事情,我好期待的哦

小鱼:(⊙o⊙)… 我有点不敢想象接下来的画面。
小芸:嘿嘿, 好害羞的哦。
小鱼:额… 别说了, 接下来咱们可以安安静静的学习了,没有小屌丝的打扰。
小芸:嗯嗯嗯…
小鱼:… 能不能别这样表达,容易引起误会
小芸:嗯,哦,

小鱼:你可别说了, 我来说吧
小芸:嗯嗯嗯
小鱼:… 唉~ 你可以不用说话的哦。
小芸:嗯嗯嗯
小鱼:姐姐,你别这样表达呀, 不然我真的说不清楚哦
小芸:好…好…
小鱼:… 我自己说YOLO吧
2、YOLO
2.1 定义
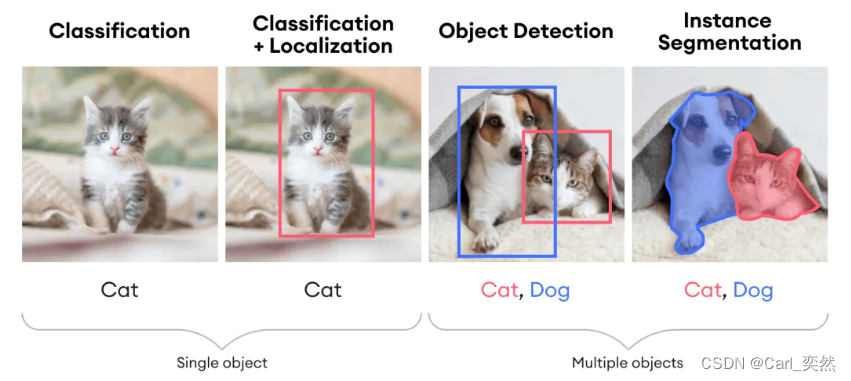
YOLO(You Only Look Once)是一种实时目标检测算法,它将目标检测任务视为一个单一的回归问题,从而大大简化了检测流程。
与传统的目标检测算法(如R-CNN系列)相比,YOLO不需要生成候选区域(Region Proposal),而是直接在输入图像上进行一次前向传播即可得到目标的边界框和类别概率。
2.2 核心思想
YOLO的核心思想是将输入图像划分为S×S的网格,每个网格负责预测固定数量的边界框以及这些边界框的类别概率。
每个边界框包含五个预测值:x, y, w, h, 和 confidence(置信度)。
其中:
- (x, y)表示边界框的中心坐标,
- w和h表示边界框的宽和高,
- confidence表示边界框内存在目标的概率与预测框的准确度之积。
在训练过程中,YOLO通过最小化边界框的坐标损失、置信度损失以及类别概率损失来优化模型参数。这使得模型能够学习到如何准确地预测目标的位置和类别。

2.3 算法公式
YOLO的损失函数由三部分组成:
- 坐标损失
- 置信度损失
- 类别概率损失
2.3.1 坐标损失
- 坐标损失(Coordinate Loss):
L c o o r d = ∑ ( ∣ ∣ b b o x ( i ) − g r o u n d t r u t h b b o x ( i ) ∣ ∣ 2 ) / n u m a n c h o r s L_coord = ∑(||bbox(i) - ground_truth_bbox(i)||^2) / num_anchors Lcoord=∑(∣∣bbox(i)−groundtruthbbox(i)∣∣2)/numanchors
其中, b b o x ( i ) bbox(i) bbox(i)是预测框的位置和大小, g r o u n d t r u t h b b o x ( i ) ground_truth_bbox(i) groundtruthbbox(i) 是真实框的位置和大小, n u m a n c h o r s num_anchors numanchors 是锚框的数量。
ρ 2 ( b , b g t ) = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 ρ²(b, b^gt) = (x2 - x1)² + (y2 - y1)² ρ2(b,bgt)=(x2−x1)2+(y2−y1)2
c = d i a g o n a l l e n g t h ( b g t ) c = diagonal_length(b^gt) c=diagonallength(bgt)
u = ρ 2 ( b g t c e n t r o i d , b c e n t r o i d ) / c 2 u = ρ²(b^gt_centroid, b_centroid) / c² u=ρ2(bgtcentroid,bcentroid)/c2
o v = I n t e r s e c t i o n ( b , b g t ) / U n i o n ( b , b g t ) ov = Intersection(b, b^gt) / Union(b, b^gt) ov=Intersection(b,bgt)/Union(b,bgt)
w r a t i o = w i d t h ( b ) / w i d t h ( b g t ) w_ratio = width(b) / width(b^gt) wratio=width(b)/width(bgt)
h r a t i o = h e i g h t ( b ) / h e i g h t ( b g t ) h_ratio = height(b) / height(b^gt) hratio=height(b)/height(bgt)
KaTeX parse error: Double subscript at position 60: …) - arctan(gt_w_̲ratio / gt_h_ra…
C I o U l o s s = 1 − I o U + u / ( 1 − I o U ) + a r l o s s CIoU_loss = 1 - IoU + u / (1 - IoU) + ar_loss CIoUloss=1−IoU+u/(1−IoU)+arloss
其中:
- b b b 和 b g t b^gt bgt 分别代表预测的边界框和真实的边界框。
- ρ 2 ( b , b g t ) ρ²(b, b^gt) ρ2(b,bgt) 是预测框和真实框中心点之间的欧氏距离的平方。
- c c c 是最小闭包框的对角线长度。
- u u u 是标准化后的中心点距离。
- o v ov ov 是预测框和真实框之间的交集除以并集,即 I o U ( I n t e r s e c t i o n o v e r U n i o n ) IoU(Intersection over Union) IoU(IntersectionoverUnion)。
- w r a t i o w_ratio wratio 和 h r a t i o h_ratio hratio 分别是预测框和真实框的宽高比。
- a r l o s s ar_loss arloss 是宽高比损失的度量。
最终,坐标损失会乘以一个权重因子 λ c o o r d λ_coord λcoord:
l o s s b b o x = λ c o o r d ∗ Σ i Σ j C I o U l o s s ( b i j , b i j g t ) loss_bbox = λ_coord * Σ_i Σ_j CIoU_loss(b_ij, b_ij^gt) lossbbox=λcoord∗ΣiΣjCIoUloss(bij,bijgt)
其中 i i i 和 j j j分别遍历所有网格和每个网格内的边界框。
2.3.2 置信度损失
- 置信度损失(Confidence Loss):
置信度损失通常采用二元交叉熵损失(Binary Cross-Entropy Loss),用于衡量预测置信度与真实置信度的差异。
公式如下:
l o s s o b j = λ o b j ∗ Σ i Σ j o b j t r u e i j ∗ B C E ( o b j p r e d i j , o b j t r u e i j ) + λ n o o b j ∗ Σ i Σ j ( 1 − o b j t r u e i j ) ∗ B C E ( o b j p r e d i j , 0 ) loss_obj = λ_obj * Σ_i Σ_j obj_true_ij * BCE(obj_pred_ij, obj_true_ij) + λ_noobj * Σ_i Σ_j (1 - obj_true_ij) * BCE(obj_pred_ij, 0) lossobj=λobj∗ΣiΣjobjtrueij∗BCE(objpredij,objtrueij)+λnoobj∗ΣiΣj(1−objtrueij)∗BCE(objpredij,0)
其中:
- o b j p r e d i j obj_pred_ij objpredij 是网格 i 中边界框 j 的预测置信度。
- o b j t r u e i j obj_true_ij objtrueij 是对应的真实置信度标签(通常是1表示有目标,0表示无目标)。
- λ o b j λ_obj λobj 和 λ n o o b j λ_noobj λnoobj 是平衡有目标和无目标边界框损失的权重因子。通常 λ n o o b j λ_noobj λnoobj会设置得较小,因为无目标边界框的数量通常较多。
2.3.3 类别概率损失
- 类别概率损失(Class Probability Loss):
类别概率损失使用交叉熵损失来计算,用于衡量预测类别概率分布与真实类别之间的差异。
公式如下:
l o s s c l s = λ c l s ∗ Σ i Σ j o b j t r u e i j ∗ C E ( c l a s s p r e d i j , c l a s s t r u e i j ) loss_cls = λ_cls * Σ_i Σ_j obj_true_ij * CE(class_pred_ij, class_true_ij) losscls=λcls∗ΣiΣjobjtrueij∗CE(classpredij,classtrueij)
其中
- c l a s s p r e d i j class_pred_ij classpredij 是网格 i i i 中边界框 j j j 的预测类别概率分布
- c l a s s t r u e i j class_true_ij classtrueij 是对应的真实类别标签(通常是 o n e − h o t one-hot one−hot编码)
- λ c l s λ_cls λcls 是平衡类别概率损失的权重因子
2.4 代码示例
代码实战
# -*- coding:utf-8 -*-
# @Time : 2024-03-24
# @Author : Carl_DJ
'''
实现功能:
使用Python+PyTorch实现YOLO v5
'''
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们有一些自定义的YOLOv5层,比如CSP(Cross Stage Partial)模块等
class CSPBlock(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
# 初始化CSPBlock,包含卷积层、CSP模块等
super(CSPBlock, self).__init__()
def forward(self, x):
# CSPBlock的前向传播
return x
class YOLOv5Head(nn.Module):
def __init__(self, ch, num_anchors, num_classes):
# YOLOv5输出层的定义,包括边界框预测、置信度和类别预测
super(YOLOv5Head, self).__init__()
def forward(self, x):
# 前向传播,返回预测结果
return x
class YOLOv5(nn.Module):
def __init__(self, num_classes, anchors):
super(YOLOv5, self).__init__()
# YOLOv5的主干网络部分,可能包含CSPBlock等
self.backbone = ...
# YOLOv5的颈部(neck)网络部分,通常包含FPN(Feature Pyramid Network)等
self.neck = ...
# YOLOv5的输出层部分,每个尺度一个输出层
self.heads = nn.ModuleList([
YOLOv5Head(ch, len(anchors[0]), num_classes) for ch in [512, 256, 128]
])
def forward(self, x):
# 前向传播,通过主干网络、颈部网络,并得到各个尺度的预测结果
features = self.backbone(x)
features = self.neck(features)
outputs = []
for scale_idx, head in enumerate(self.heads):
x_scale = features[scale_idx]
output = head(x_scale)
outputs.append(output)
return outputs
# 初始化模型
model = YOLOv5(num_classes=80, anchors=[...]) # anchors是预先定义的锚框尺寸列表
# 假设输入图像已经准备好
inputs = torch.randn(1, 3, 640, 640) # 批量大小为1,3通道,640x640大小
# 前向传播计算预测结果
outputs = model(inputs)
# 损失函数需要根据YOLOv5的输出格式来定义,这里仅展示框架
class YOLOv5Loss(nn.Module):
def __init__(self):
super(YOLOv5Loss, self).__init__()
# 初始化损失函数需要的参数和辅助函数
def forward(self, preds, targets):
# preds是模型的输出,targets是真实标注
# 这里需要实现坐标损失、置信度损失、类别损失的计算
# 并返回总的损失值
loss = ...
return loss
# 定义损失函数和优化器
criterion = YOLOv5Loss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设targets是真实的目标标注,包含了边界框、类别和置信度信息
targets = ... # 这里需要实现一个生成targets的函数或加载标注数据
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
3、总结
YOLO算法作为实时目标检测领域的佼佼者,以其高效、准确的特点在实际应用中得到了广泛的应用。
通过将目标检测任务视为单一的回归问题,YOLO简化了检测流程并提高了检测速度。
同时,通过优化损失函数和网络结构,YOLO算法能够学习到如何准确地预测目标的位置和类别。
然而,YOLO算法也存在一些局限性,例如对于小目标或密集目标的检测效果可能不佳。
因此,在实际应用中,我们需要根据具体任务和数据特点选择合适的算法和模型,并进行适当的优化和调整。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,学习【机器学习】&【深度学习】领域的知识。
















 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











