







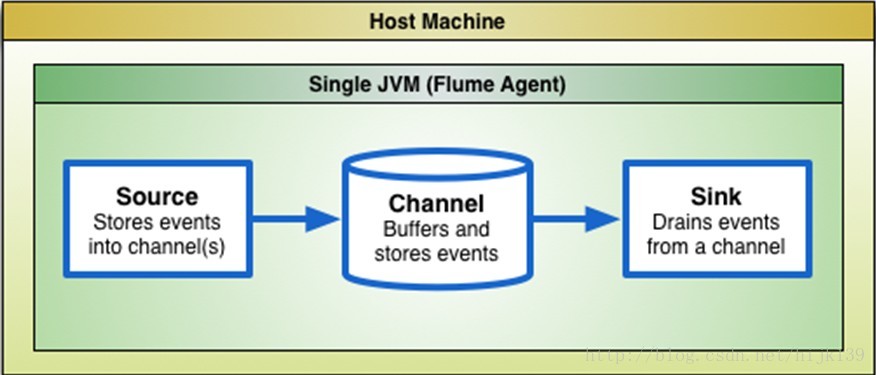
如图1所示,一个flume-ng agent主要包括source,channel和sink三部分,三部分运行在java JVM中,JVM一般运行在linux'操作系统上,因此,这些因素都可能影响最终的性能。flume-ng性能优化与架构设计,简单来讲,也主要包括以上部分。
1.1 source 的配置
有时候不需要每台主机均安装flume agent,可以和sshpass等命令结合使用,灵活收集日志.
1.2 channel的配置
可选的一般为memory channel和file channel,
内存足够的话,一般建议选择时效性更好的memory channel,
- agent.channels.memory_chan_1.type = memory
- agent.channels.memory_chan_1.keep-alive = 30
- agent.channels.memory_chan_1.transactionCapacity = 20000
- agent.channels.memory_chan_1.byteCapacityBufferPercentage = 40
- agent.channels.memory_chan_1.byteCapacity = 50000000
- agent.channels.memory_chan_1.capacity = 500000
capacity: Maximum # of events that can be in the channel
transactionCapacity: Maximum # of events in one txn.
keepAlive: how long to wait to put/take an event
channel性能的关键是设置合理的以上三个参数
1.3 sink的配置
已hdfs sink为例,可以使用压缩节省空间和网络流量,但会增加cpu消耗.
- # Each sink's type must be defined
- agent.sinks.hdfsSink_1.type = hdfs
- agent.sinks.hdfsSink_1.channel = memory_chan_1
- agent.sinks.hdfsSink_1.hdfs.path = /logdata/%Y%m%d/%{hostname}/%{filename}%{CRMLOG}
- agent.sinks.hdfsSink_1.hdfs.filePrefix = %{filename}%{CRMLOG}
- agent.sinks.hdfsSink_1.hdfs.rollInterval = 3600
- agent.sinks.hdfsSink_1.hdfs.rollSize = 40000000
- agent.sinks.hdfsSink_1.hdfs.rollCount = 0
- agent.sinks.hdfsSink_1.hdfs.writeFormat = Writable
- agent.sinks.hdfsSink_1.hdfs.fileType = CompressedStream
- agent.sinks.hdfsSink_1.hdfs.batchSize = 10000
- agent.sinks.hdfsSink_1.hdfs.serializer = avro_event
- agent.sinks.hdfsSink_1.hdfs.threadsPoolSize = 100
- agent.sinks.hdfsSink_1.hdfs.codeC = gzip
影响sink的注意事项
Batch Size:越大性能越好,但太大影响时效性.一般可选为100,1000,10000,batch size最好源数据端大小相同
agent.sinks.flowSink-3-5.batch-size = 10000
agent.sinks.hdfsSink_1.hdfs.batchSize = 10000
sink是单线程处理的,所有一个channel要配置多个写入sink,来提高性能
2, JAVA内存的设计
主要通过修改 conf/flume-env.sh文件实现
主要设计Xmx和Xms两个参数,可以根据OS内存的大小进行合理设置,一般一个flume agent 1g左右大小即可
-Xms<size> set initial Java heap size.........................
-Xmx<size> set maximum Java heap size.........................
3,OS的内核参数调整
如果单台服务器启动的flume agent过多的话,默认的内核参数设置偏小,需要调整, 调整方法基本和安装oracle数据库等类似,相关参数可以相应设置的大一点
系统的参数限制,设置样例为
- cat /etc/sysctl.conf
- kernel.shmall = 33554432
- kernel.shmmax = 137438953472
- kernel.shmmni = 4096
- kernel.sem = 250 32000 100 128
- fs.file-max = 6815744
- fs.aio-max-nr = 1048576
- net.ipv4.ip_local_port_range = 9000 65500
- net.core.rmem_default = 262144
- net.core.rmem_max = 4194304
- net.core.wmem_default = 262144
- net.core.wmem_max = 1048576
- vi /etc/security/limits.conf
- # End of file
- hadoop soft nproc 32047
- hadoop hard nproc 36384
- hadoop soft nofile 31024
- hadoop hard nofile 65536
4,网络配置
flume日志和hadoop集群都是通过网络进行日志传送,所以网络不要成为性能瓶颈
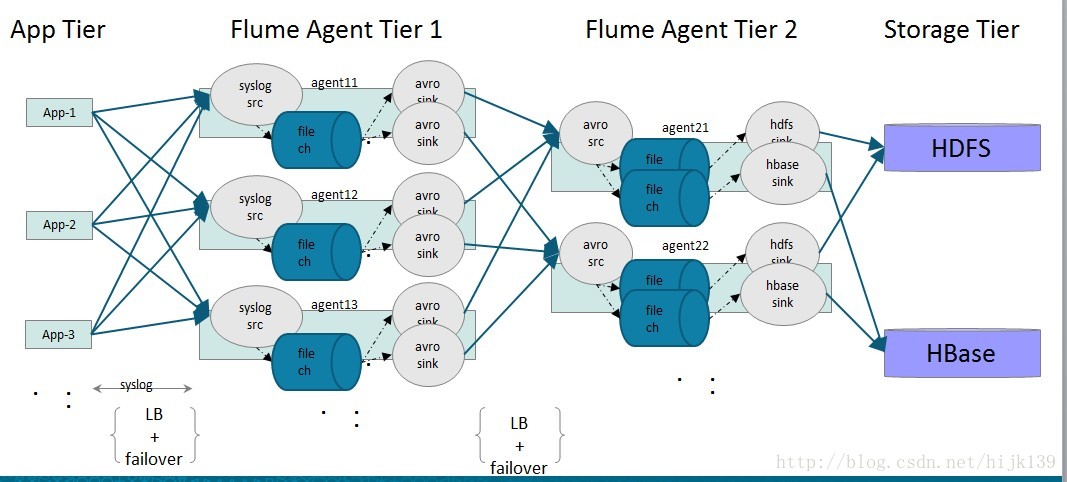
5,架构设计,尽可能使用分布式和高可用的架构 (重要)
建议使用loadbalnce+failover,实现了架构的可扩展性和高可用性, 一台物理服务器上agent的数量不要超过core的数量 。
- agent.sinks = flowSink-3-1 flowSink-3-2 flowSink-3-3 flowSink-3-4 flowSink-3-5
- agent.sinkgroups = g1
- agent.sinkgroups.g1.sinks = flowSink-3-1 flowSink-3-2 flowSink-3-3 flowSink-3-4 flowSink-3-5
- agent.sinkgroups.g1.processor.type = load_balance
- agent.sinkgroups.g1.processor.selector = round_robin
- agent.sinkgroups.g1.processor.backoff = true
- ...
- agent.sinks.flowSink-3-1.type = avro
- agent.sinks.flowSink-3-1.channel = memory_chan_1
- agent.sinks.flowSink-3-1.hostname = 127.0.0.1
- agent.sinks.flowSink-3-1.port = 41451
- agent.sinks.flowSink-3-1.batch-size = 1000
参考文档
Building a Data Collection System with Apache Flume
http://flume.apache.org/FlumeUserGuide.html















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









