







一:简述
Raft协议是一种强一致性、去中心化、高可用的分布式协议,它是用来解决分布式一致性问题的,相对于大名鼎鼎的Paxos协议,Raft协议更容易理解,并且在性能、可靠性、可用性方面是不输于Paxos协议的。许多中间件都是利用Raft协议来保证分布式一致性的,例如Redis的sentinel,CP模式的Nacos的leader选举都是通过Raft协议来实现的。今天就和大家一起探讨一下Raft协议的实现原理。
Raft协议可以分为数据同步和leader选举两个阶段方面进行分析。
二:Raft协议是如何实现数据一致性的
Raft协议规定节点有三种角色,Leader(主节点),Follower(从节点),Candidate(候选节点)。一开始大家都是Follower节点,如果Follower节点没有在指定时间内接收到Leader的心跳包,那么就会变成Candidate节点。而Candidate节点会向其他节点发送投票的请求,请求其他节点投票,而票数超过集群节点数的一半的节点会成为Leader节点。而Leader节点负责处理所有客户端的事务请求(增删改请求)。
注:如果事务请求没有到Leader节点,那么Follower节点也会将请求转发到Leader,nacos就是这样实现的。
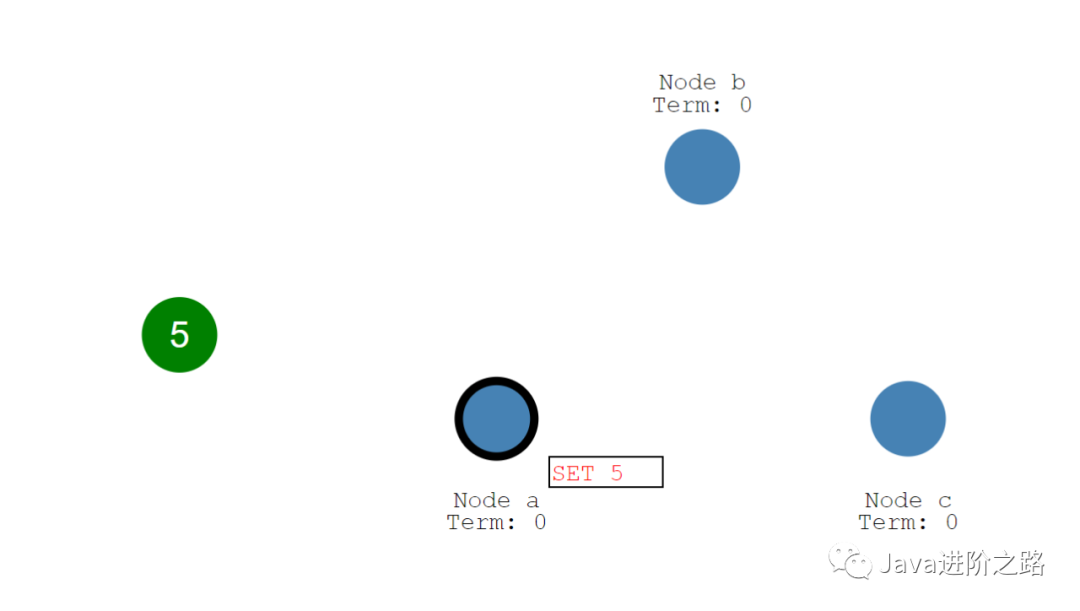
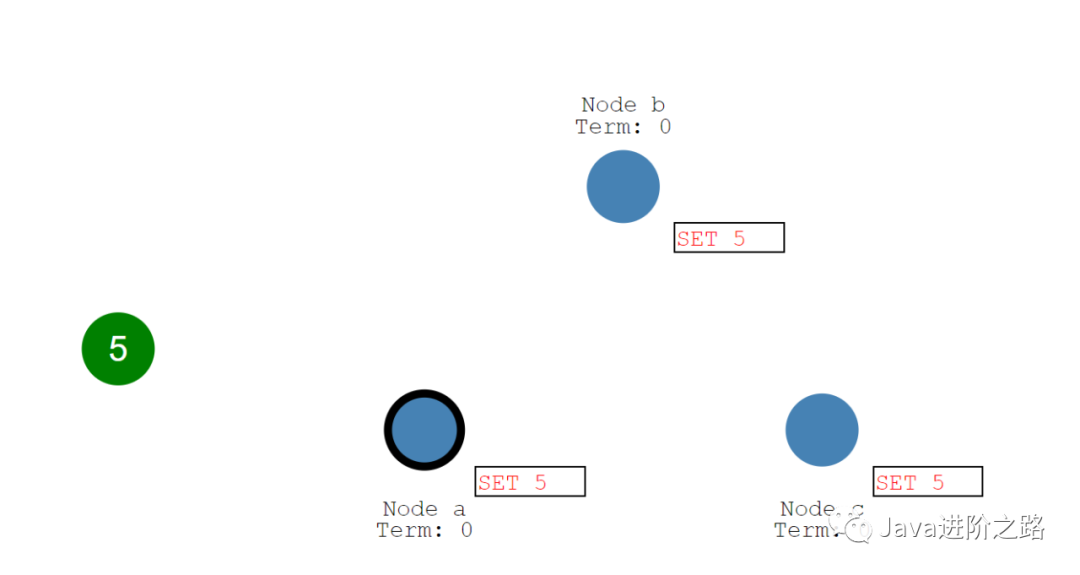
Leader节点接收到事务请求后,会先写入本地日志中,然后向集群中的每一个Follower节点发送一个请求询问是否可以更新数据。如果超过一半的节点都认同这次操作,那么Leader节点才会把数据更新,随后将结果返回给客户端并且通知每个Follower节点将自己的数据也进行修改。这样就可以保证集群的数据一致性了。
三:Raft协议是如何选举出Leader节点的
我们已经知道了,所有的事务请求都需要Leader来进行处理,Leader节点至关重要。那么如果Leader节点宕机了,那么会发生什么呢?
很明显,Leader节点宕机了,我们就需要重新选择一个节点作为新的Leader节点。接下来我们看Raft协议是如何判断Leader节点已经宕机,又是如何进行Leader选举的。
1.如何判断Leader节点已经宕机
Leader会定时向每一个Follower节点发送一个心跳请求,如果在指定的时间内没有接收到Leader的心跳包,那么Follower节点就会认为Leader已经宕机了。
2.如何进行新Leader的选举
首先,每个Follower节点都有一个超时时间,这个超时时间是一个150-300ms的随机数,通过接收Leader的心跳包不断重置这个时候,如果这个时间内没有接收到Leader的心跳包,那么Follower节点就会变成Candidate节点,并且将选票投给自己,同时发送请求给其他节点,要求将选票投给自己。
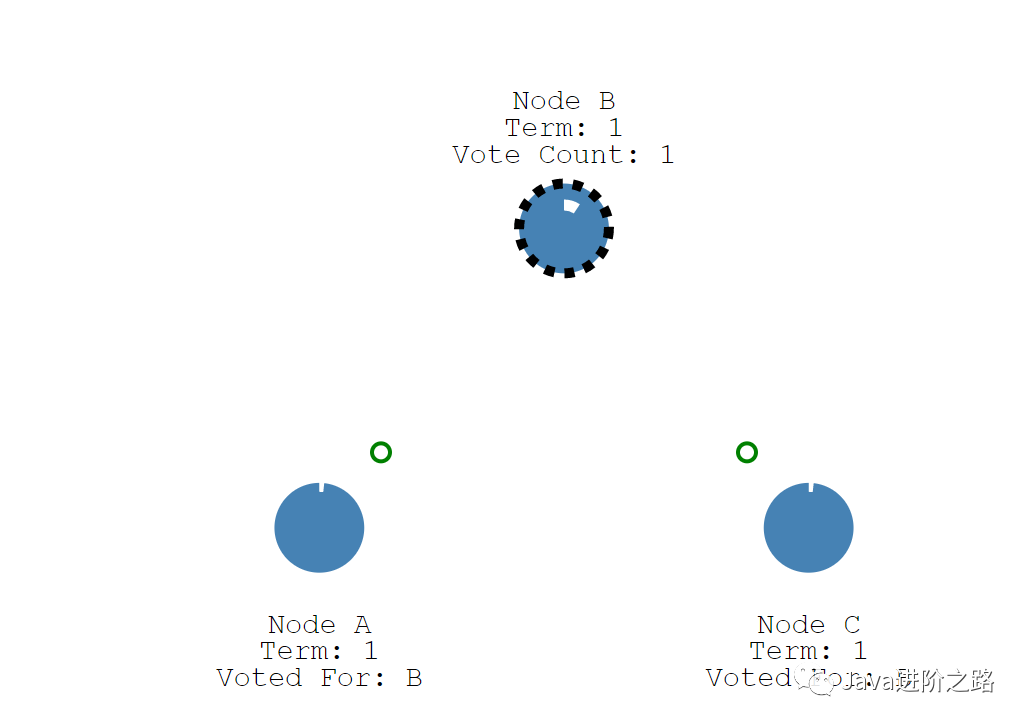
如果Candidate节点获得的选票超过半数,那么它将会成为新的Leader节点,并且将Term标志+1,同时会将自己的节点信息以及数据同步到各个节点。这样也就完成了一轮Leader的选举。
有些小伙伴可能会问,既然超时时间是一个随机数,那么有没有可能超时时间是一样的,导致获得的选票也一样。那这种情况如何解决?其实很简单,再重新选举一次即可,毕竟这种情况出现的概率较小。
四:Raft协议如何处理脑裂的问题
什么是脑裂?简单来说就是因为不同机房之间的网络出现了故障,导致集群重新选举,从而导致集群重新选举Leader,从而造成集群存在两个Leader。
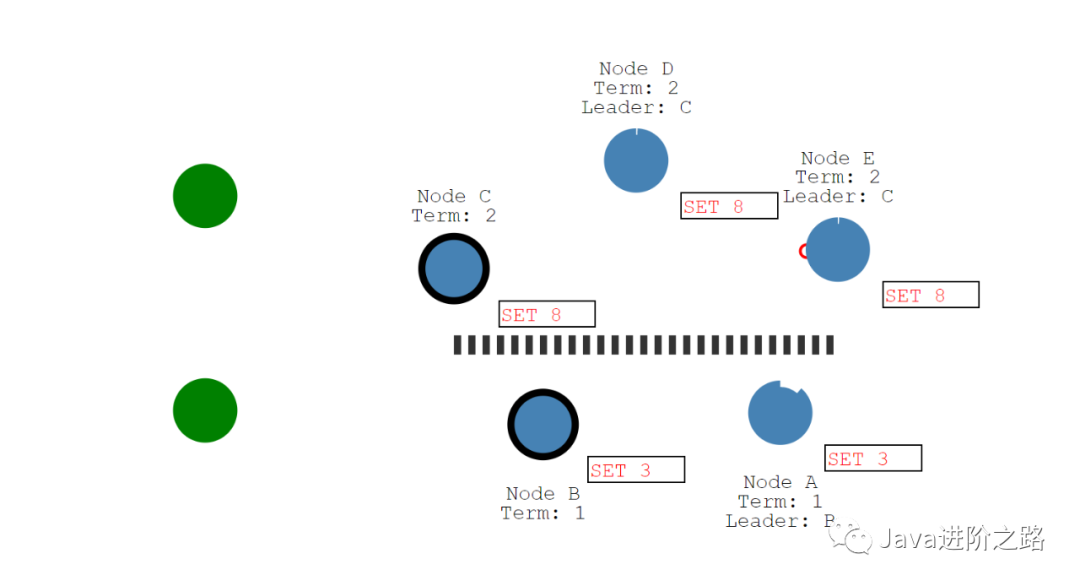
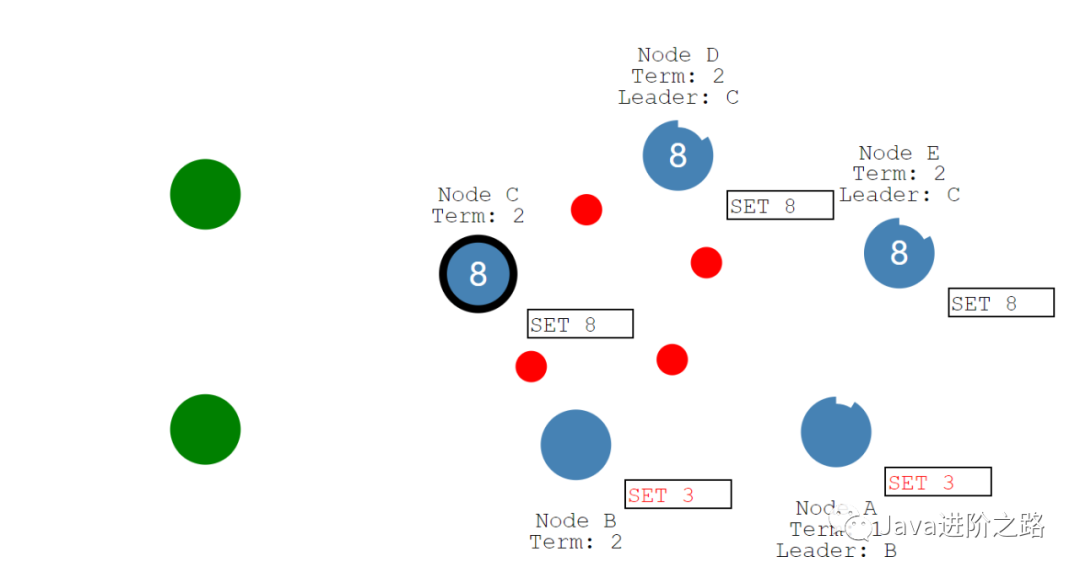
如图所示,当出现网络故障之后,集群重新选举新的Leader节点,但是我们已经知道了,在Raft协议中要进行事务操作,必须要有半数以上的Follower同意才能完成,否则将会失败。
可以看到如果客户端请求到下面的Leader,那么数据只会保存在Leader本地日志中,而无法提交,也无法返回给客户端。而如果客户端请求到上面的Leader,那么是可以正常处理事务请求的,因为上面的Leader是可以得到半数以上节点的同意的。
那么如果网络恢复之后,存在两个Leader,该如何处理?
因为上面的Leader的Term是大于下面的Leader的,所以会选择上面的Leader作为新的Leader,下面的Leader会变成Follower节点,同时新Leader会将数据同步到其他的节点。所以基于Raft协议作为一致性协议的中间件是没有脑裂的问题的。
相信大家已经明白了Raft协议的原理了,最后大家可以思考一下,为什么我们不是Redis哨兵,nacos集群的时候为什么选择的节点数量都是单数(比如3个节点,5个节点)而不是偶数?
附上Raft协议的动图:http://thesecretlivesofdata.com/raft/
复制状态机
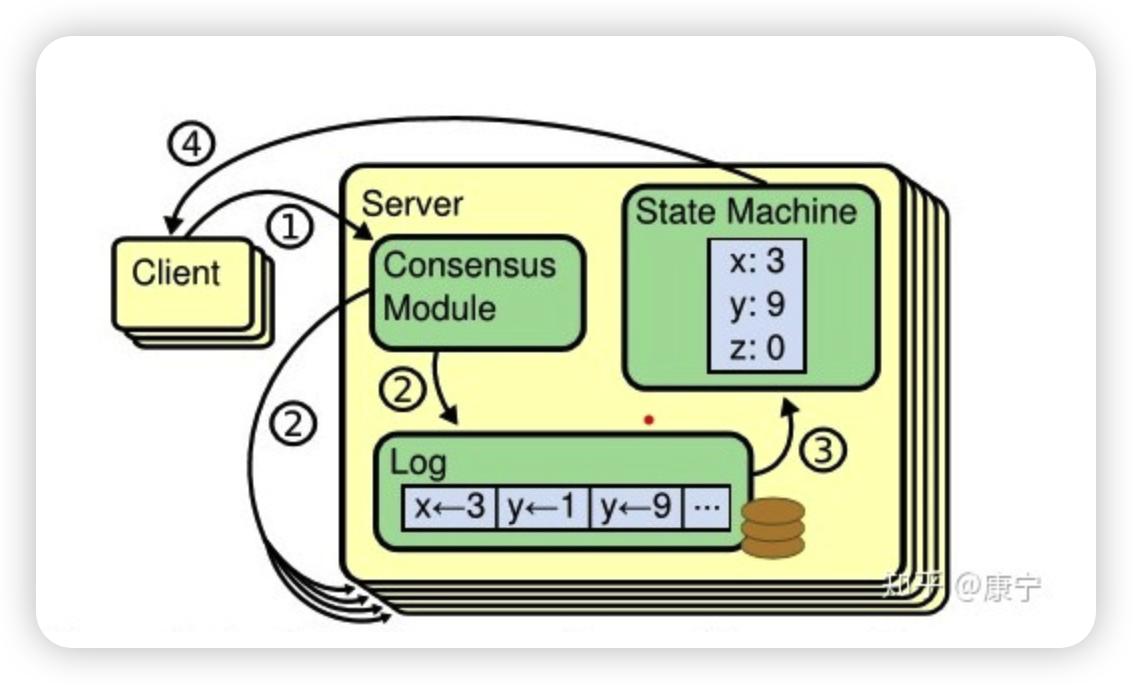
复制状态机,就是说每一台服务器上维持着一份持久化Log,然后 通过一致性协议算法,保证每一个实例中的Log保持一致,并且顺序存放,这样客户端就可以在每一个实例中读取到相同的数据。
如上图所示,有一个Consensus Module就是一致性协议模块,它可以是Paxos算法的实现或者Raft算法。
在上图中,服务器中的一致性模块(Consensus Modle)接受来自客户端的指令,并写入到自己的日志中,然后通过一致性模块和其他服务器交互,确保每一条日志都能以相同顺序写入到其他服务器的日志中,即便服务器宕机了一段时间。
一旦日志命令都被正确的复制,每一台服务器就会顺序的处理命令,并向客户端返回结果。















 2693
2693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









