







storm学习:http://ifeve.com/getting-started-with-stom-index/
1.什么是storm
Storm是一个开源的,分布式的,可靠的,实时数据流处理系统。类比Hadoop对数据进行批处理,storm对数据进行实时处理。
2.storm的应用场景
Storm的处理速度快吞吐量大,根据Storm官方网站的资料介绍,Storm的一个节点(Intel E5645@2.4Ghz的CPU,24 GB的内存)在1秒钟能够处理100万个100字节的消息。
(1)流处理(Stream Processing)
Storm最基本的用例是“流处理”。Storm可以用来处理源源不断流进来的消息,再写入数据库。它是不需要中间队列的。
(2)连续计算(Continuous Computation)
Storm的另一个典型用例是“连续计算”。Storm能保证计算可以永远运行,直到用户结束计算进程为止。比如可以连续发送数据到客户端,实时更新显示。
(3)分布式远程过程调用(Distributed RPC)
Storm的第三个典型用例是“分布式RPC”,由于Storm的处理组件是分布式的,而且处理延迟极低,所以可以作为通用的分布式RPC框架来使用。可以将频繁的CPU密集型操作并行化。
4.storm组件
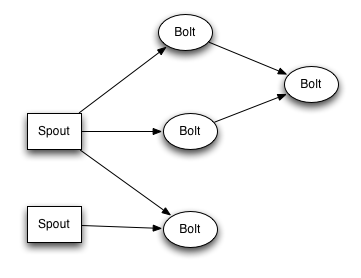
Spout:Spout是Topology流的来源。一般Spout从外部来源读取Tuple,提交到Topology(如Kestrel队列或Twitter API)。Spout可分为可靠的和不可靠的两种模式。Spout可以发出超过一个流。
Bolt:Topology中的所有处理都在Bolt中完成,Bolt是流的处理节点。Bolt可以完成过滤、业务处理、连接运算、连接、访问数据库等业务。Bolt可以做简单的流的转换,发出超过一个流。
Stream:流是Storm的核心抽象。一个流是一个无界Tuple序列,Tuple可以包含整形、长整形、短整形、字节、字符、双精度数、浮点数、布尔值和字节数组。用户可以通过定义序列化器,在本机Tuple使用自定义类型。
Tuple: Storm将元组作为其数据模型。元组是消息传递的基本单元,是一个命名的值列表,字段的类型不限。本来元组应该是一个key-value的Map, 但是各个组件之间传递的元组的字段名称已经事先定义好,故只需要按照顺序写入各个value即可,元组是一个value的list。
Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。
Topology: Storm的分布式计算结构称为拓扑(topology),由stream(数据流)、spout(数据流的生成者)、bolt(运算)组成。当Topology在服务器上部署完之后,它就会一直运行下去,直到用户禁止相应的进程。
一个拓扑是一个图的计算。用户在一个拓扑的每个节点包含处理逻辑,节点之间的链接显示数据应该如何在节点之间传递。Topology的运行是很简单的。拓扑(Topology)是Storm中运行的一个实时应用程序,因为各个组件间的消息流动而形成逻辑上的拓扑结构。
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑(Topology)。Storm的拓扑类似于MapReduce的作业(Job)。其主要的区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
一个拓扑会一直运行,直到你杀死它。Storm会自动重新分配任何失败的任务。此外,即使主机已经关闭,消息已经被删除,Storm也能保证不会有数据丢失。
接下来通过分析storm的组件来理解storm的主要工作。简单来说,storm的工作就是:Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。一个Storm集群就是在一连串的bolt之间转换spout传过来的数据。
5.storm节点 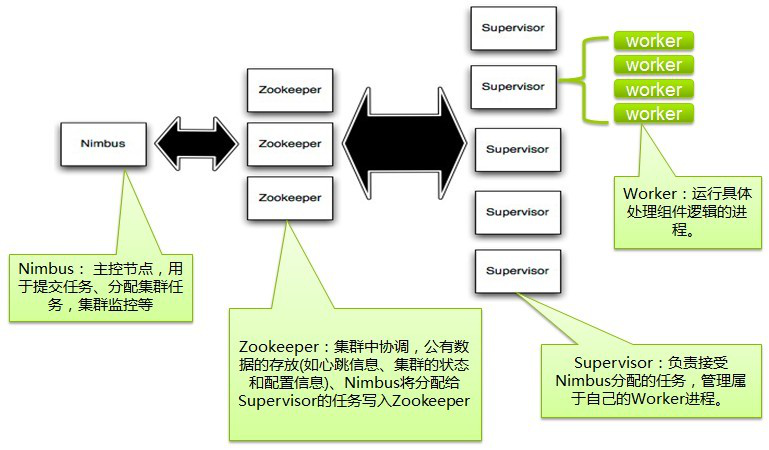
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker Node)。其中,主控节点只有一个,而工作节点可以有多个。
(1) 主控节点运行一个称为Nimbus的守护进程,类似于Hadoop的JobTracker。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
(2) 每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
Task(任务)
每个Spout或者Bolt在集群执行许多任务。每个任务对应一个线程的执行,流分组定义如何从一个任务集到另一个任务集发送Tuple。可通过TopologyBuilder类的setSpout()和setBolt()方法来设置每个Spout或者Bolt的并行度。
Worker(工作进程)
Topology跨一个或多个Worker节点的进程执行。每个Worker节点的进程是一个物理的JVM和Topology执行所有任务的一个子集。
6.Storm的操作模式
Storm有一个“本地模式”,用户可以在进程里面模拟一个Storm集群,然后进行类似实际集群上的开发工作。这种模式对于开发和测试十分有用。当用户准备好在一个真正的集群上提交Topology执行的时候,可以使用Storm命令行方便地从客户端提交一个Topology到集群上运行。在“集群模式“下,我们向Storm集群提交拓扑,它通常由许多运行在不同机器上的流程组成。
操作模式
本地模式
在本地模式下,Storm拓扑结构运行在本地计算机的单一JVM进程上。这个模式用于开发、测试以及调试,因为这是观察所有组件如何协同工作的最简单方法。在这种模式下,我们可以调整参数,观察我们的拓扑结构如何在不同的Storm配置环境下运行。要在本地模式下运行,我们要下载Storm开发依赖,以便用来开发并测试我们的拓扑结构。我们创建了第一个Storm工程以后,很快就会明白如何使用本地模式了。
NOTE: 在本地模式下,跟在集群环境运行很像。不过很有必要确认一下所有组件都是线程安全的,因为当把它们部署到远程模式时它们可能会运行在不同的JVM进程甚至不同的物理机上,这个时候它们之间没有直接的通讯或共享内存。
我们要在本地模式运行本章的所有例子。
远程模式
在远程模式下,我们向Storm集群提交拓扑,它通常由许多运行在不同机器上的流程组成。远程模式不会出现调试信息, 因此它也称作生产模式。不过在单一开发机上建立一个Storm集群是一个好主意,可以在部署到生产环境之前,用来确认拓扑在集群环境下没有任何问题。















 2869
2869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









