








新智元报道
编辑:好困 Aeneas
【新智元导读】清华大学 SuperBench 团队的新一轮全球大模型评测中,Claude 3 依然强到发指。在技术报告中,有人发现了 Claude 3 的亮点——它是在合成数据上训练的。所以,果然合成数据才是人类的未来吗?
就在最近,清华大学 SuperBench 团队的新一轮全球大模型评测结果出炉了!
此次测评,还增加了 Llama 3-8b 和 Llama 3-70b 两个最近炙手可热的模型。
在语义理解、智能体能力、代码能力三个测评中,我们发现:Claude-3 拿下两个 top 1,稳稳位于前三之列。
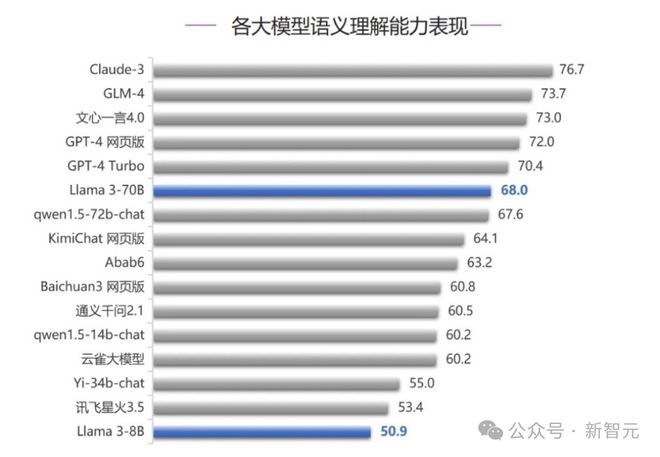
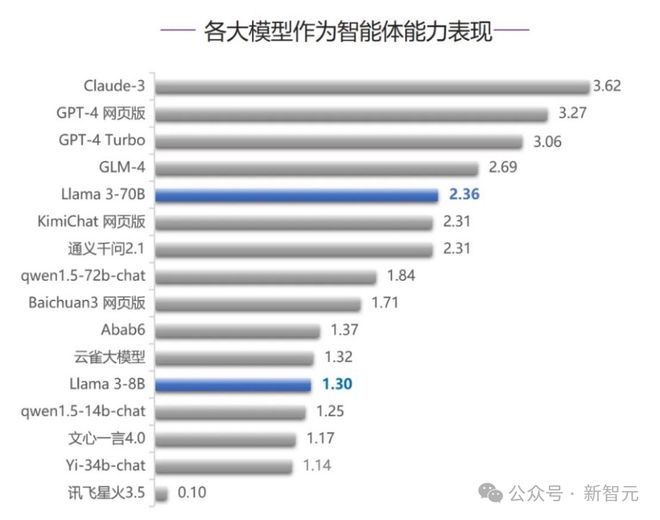
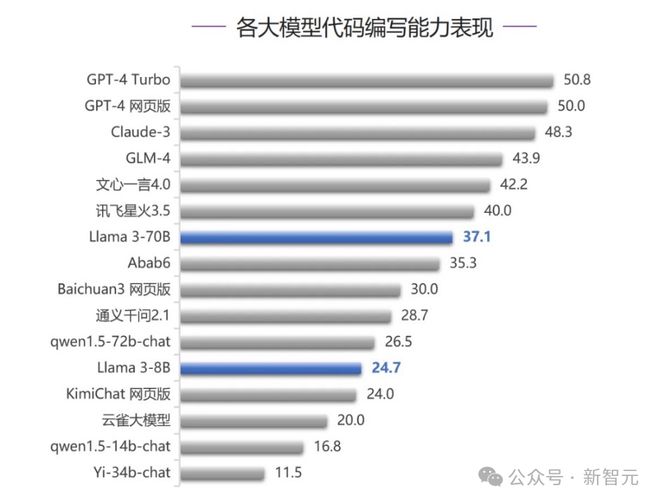
Claude 3 果然实强。
技术报告曝出:Claude 3 靠合成数据
在技术报告中,大家发现了 Claude 3 的亮点——
它是在合成数据上训练的。
鉴于大模型的参数数量和数据都是可以缩放的,所以以后计算就是瓶颈了。
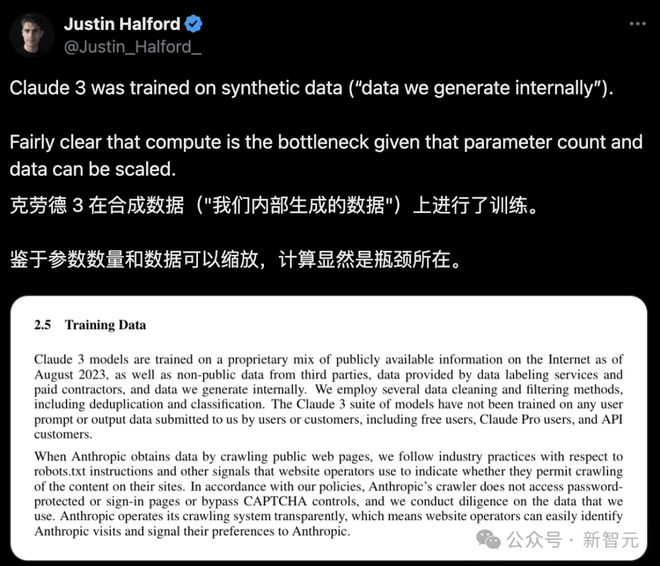
所以,Claude 3 的成功,可以说是对合成数据而言是一个巨大的进步。
其实,此前艾伦人工智能研究所的科学家 Nathan Lambert 就曾经就 Anthropic 的合成数据做了一些猜测。
而现在详细技术报告的发布,将他的猜测完全证实了!
合成数据的探索
关于合成数据,Lambert 曾在 23 年 11 月写下了一篇文章《合成数据:Anthropic 的 CAI,从微调到预训练,OpenAI 的超对齐,提示、类型和开放示例》。
在这篇文章里,他做出判断——合成数据是 AI 下一阶段的加速器,并且详细解释了合成数据是什么,以及它意味着什么。

合成数据,也就是由机器生成而非人工创建的数据,在自然语言处理(NLP)和整个机器学习(ML)领域都有着长久的历史背景。与之密切相关的概念是数据增强,即通过对数据进行细微调整来丰富数据集的多样性。
在 NLP 领域,一个经典的应用是回译,即利用 ML 模型的输出对原始文本进行重新翻译,生成新的数据。
如今,合成数据的使命变得更加重大:通过去除人类的介入,让 AI 更加符合预期且用户友好。
这一任务由 Anthropic 的训练方法和 OpenAI 新成立的、充满神秘色彩的超对齐团队牵头,后者致力于利用 AI 反馈解决对齐问题。
同时,合成数据已经成为众多知名开源模型供应商微调 Meta 和 Mistral 模型的首选工具。
合成数据,能成为下一次技术突破的关键吗?
随着当前或下一代模型很可能已经用尽了互联网上所有的高质量数据源,模型开发者正在寻找新的途径来获取所需的大规模数据,以支持模型的持续扩展。
合成数据的支持者认为,增加更多的数据有助于模型更好地解决那些长尾任务或评估问题。为了模型能够扩大 100 倍,将需要大量的合成或数字化数据。
反对者则认为,我们生成的所有数据都来源于与当前 SOTA 模型相同的分布,因此不太可能推动技术产生新的进展。
尽管如此,开源领域仍然远远落后于 GPT-4 和 GPT-4-Turbo,这意味着我们想要在开发的各个阶段复制这些数据,还有很长的路要走。
开源的支持者和 HuggingFace Hub 上的大多数趋势模型都将合成数据作为一种快速行动的方式,并有能力在行业中尝试 SOTA 语言模型背后的技术。
开源支持者和 HuggingFace Hub 上大多数流行模型,都将合成数据作为一种快速发展,并尝试业内最先进 SOTA 语言模型的方法。
像 Anthropic 和 OpenAI 这样的公司使用合成数据,因为这是他们在规模和能力上取得进展的唯一方式,而小模型之所以使用合成数据,是因为相同规模的人类数据的成本要高出数千倍。
在这种二分法中,虽然方法看起来相似,但大公司会在创建数据集(预训练规模的合成数据)上投入超过 1000 万美元的推理计算成本,而开源竞争者可能只需要花费大约 10 美元。
尽管开源和闭源这两个社区追求的目标截然不同,合成数据却同时为他们双方提供了支持。
合成数据可以让模型在训练中能多次看到某些不常见的数据点,从而使模型的鲁棒性得到提升。
通过投喂大量数据,模型在小众事实、语言和任务的处理能力也都将显著提高。
Anthropic 的 CAI 技术与合成数据的复杂性
关于 Anthropic 大量使用合成数据的传言众所周知,这种做法显著提升了他们的模型鲁棒性。
尽管 Meta 的 Llama 2 聊天机器人因基于隐藏的触发词列表而做出荒谬的拒绝而受到批评,但 Anthropic 的模型在拒绝不了解的问题时表现出了更加合理的判断,值得我们给予肯定。
Anthropic 在其 Claude 系列模型中广泛采用的宪法 AI(Constitutional AI, CAI)技术,是迄今为止已知最大规模的合成数据应用实例。
具体来说,宪法 AI 通过两种方式利用合成数据:
1. 对指令调整数据进行评估,确保其遵循一系列原则,如「答案是否鼓励暴力」或「答案是否真实」。模型在生成问题答案时会根据这些原则进行检查,并随时间优化答案。之后,模型会根据这些经过筛选的数据进行微调。
2. 利用语言模型生成成对偏好数据,评估在特定原则指导下哪个答案更为恰当(类似于某篇论文中对原则引导奖励模型的使用)。随后,模型通过合成数据进行正常的从人类反馈中学习(RLHF),这一过程也称为 RLAIF。
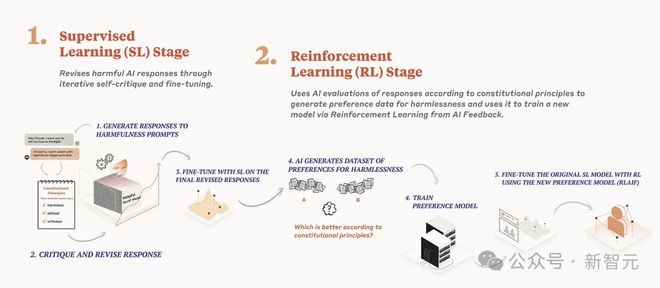
如今,RLAIF 已成为业界广泛认可的术语,很多研究人员都会通过使用 GPT-4 来获取评分或选择,这些评分或选择可以转化为 RLHF 所需的接受/拒绝样本。
然而,由于在生成批评/对多个答案进行评分与在合成数据生成阶段确定一套经验稳定原则之间存在细微差别,CAI 的复杂性和细节并未被充分理解。
在进行 CAI 的两个核心步骤时,Anthropic 必须确保各项原则长度一致,避免概念上的重叠,并且不能随意更改其规模。此外,有些原则所生成的数据在数值上可能会出现不稳定。
合成指令、偏好和评论
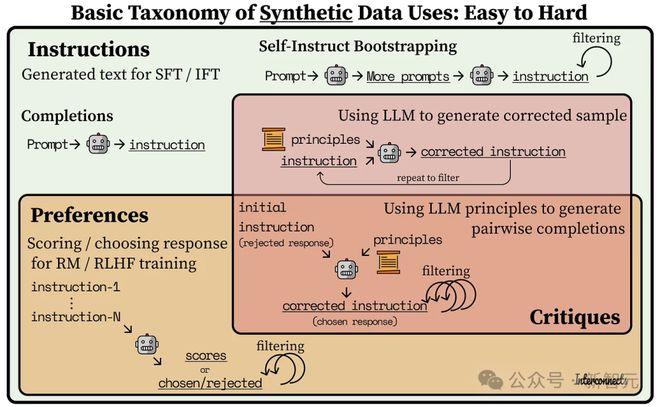
在开源模型里,我们可以清晰地看到合成数据应用方式的演进。
2023 年初,模型如 Alpaca 和 Vicuna 通过使用合成指令数据对 Llama 模型进行监督式微调(SFT),在7-13B 参数规模上实现了显著的性能提升。
其中,很多开源指令数据集都是基于 Self-Instruct 方法的进步——先创建一组「种子」指令,然后利用大语言模型(LLM)生成类似的指令。目前有许多方法可以实现这一点,但都还在探索如何为数据集增加多样性的初期阶段。
与此同时,一些研究人员通过从互联网上抓取提示,并用 GPT-4 将这些提示转化为指令。但要注意,像 ShareGPT 这样的提示数据集,其平均质量较低,分布也较为窄。
如今,合成偏好开始出现。这主要是通过评分或比较哪个更好来实现,类似于 MT Bench 和 AlpacaEval 的评分方法,但是会保留分数或胜负作为训练数据。
例如,UltraFeedback 就是从用户来源(如 ShareGPT)和现有的指令数据集(如 FLAN)中收集提示,并生成模型的评论和完成情况。
最新的进展是通过 AI 评论生成的偏好或指令数据。评论是一个反复利用经过特定原则或问题微调的大语言模型(LLM)的过程。期间,增加更多的上下文信息,会大幅提高模型评论合成数据的能力,但系统设计也更加复杂。
像 Meta 的 Shephard 和 KAIST 的 Prometheus 这样的评论模型开始出现,它们能够对提示-生成对做出响应。但我们距离模型、意图和知识协同作用的反馈循环还有很长的路要走
下面是一张简单的图表,用来展示合成指令生成是偏好上游,而偏好既是评论的上游,也是训练难度的上游。
尽管原始的 ChatGPT 模型(GPT-3.5-turbo)在执行一些任务时会遇到困难,比如返回一个 1 到 10 之间的单个整数,但最新的模型轻松做到了这一点。
当开源模型能够稳定地生成评论时,将迎来另一个转折点。
虽然目前还不完全清楚,评论数据相比通用偏好评分对于模型的改进到底有多重要,但如果以 Claude 为例,它肯定是有用的。
两个合成数据的小窍门
1. 始终使用最优的模型来生成数据:
众所周知,模型的效果完全依赖于数据的质量。
很多研究者可能不愿意支付 OpenAI 的数据训练费用,但从成本效益来看,使用 SOTA 模型绝对是值得的。
这甚至包括使用一些非传统方法,例如通过网页版的 ChatGPT 来生成一系列的提示词,这是作者亲自尝试过的。
2. API 会发生变化,因此需要尽可能锁定版本:
这一建议来自于作者数百次的 MT-Bench 评估经验——模型 API 端点的变化可能会导致研究结果出现重大偏差。
例如,某个 API 端点会在评分时变得非常严厉,并且无缘无故地给出只有 1 分的评价。
如果不固定 API 的版本,你可能会遇到一些意想不到的问题,进而无法使合成数据完全可靠或符合逻辑。
参考资料:
https://twitter.com/Justin_Halford_/status/1764677260555034844
Synthetic data: Anthropic’s CAI, scaling, OpenAI’s Superalignment, tips, and open-source examples
来自: 网易科技

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











