







新智元报道
编辑:编辑部
两天前,马斯克得意自曝:团队仅用 122 天,就建成了 10 万张 H100 的 Colossus 集群,未来还会扩展到 15 万张 H100 和 5 万张 H200。此消息一出,奥特曼都被吓到了:xAI 的算力已经超过 OpenAI 了,还给员工承诺了价值 2 亿期权,这是要上天?
马斯克的 xAI 一路狂飙突进,把 Sam Altman 都整怕了!
就在 9 月 3 日,马斯克在推上得意自曝:
团队仅仅用了 122 天时间,就建成了有 10 万张 H100 的 Colossus 集群,是世界上最强大的 AI 训练系统。
而且,未来几个月规模还要翻一倍,扩展到 15 万张 H100+5 万张 H200。
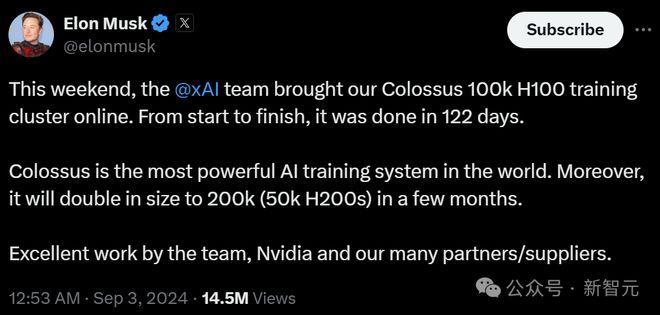
最后,马斯克感谢了英伟达和许多其他合作伙伴、供应商。据悉,是戴尔开发、组装了 Colossus 系统。
马斯克的 xAI,已经让几大 AI 巨头感受到了强烈的威胁。
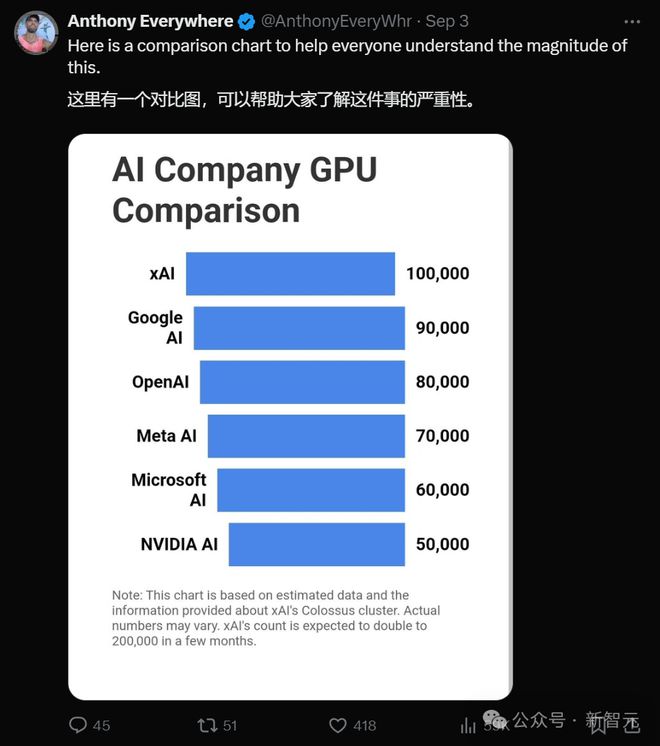
根据内幕消息,Sam Altman 就曾表示,自己是怕了马斯克了!
如今的 xAI,不光算力有超越 OpenAI 之势,还对员工十分大方。有说法指出,对于 xAI 的研究者,马老板曾承诺过价值 2 亿美元的期权。


马斯克,全力进军超算
相信大家都已经发现:马斯克的超算野心,是愈发藏不住了!
隔三岔五的,就会有劲爆消息曝出。
7 月底,xAI 启动了位于孟菲斯的超级 AI 集群的训练,该集群由十万个液冷 H100 GPU 组成。
十万个 H100 GPU 消耗的电力大约在 70 兆瓦,因此这个超算至少会消耗 150 兆瓦的电力。
8 月底,特斯拉宣布了 Cortex AI 集群,包括 5 万个英伟达 H100 GPU,和 2 万个特斯拉的 Dojo AI 晶圆级芯片。


如今看来,这些集群很可能都正式投入运行,甚至已经在训练 AI 模型了。
不过,马斯克真的有能力让它们全部在线吗?
首要问题是,要调试和优化这些集群的设置,需要一定时间。
其次,xAI 还得确保它们获得足够的电力。
我们知道,虽然马斯克的公司一直在用 14 台独立发电机为其供电,但要为十万块 H100 GPU 供电,这些电力显然不够。
训练 xAI 的 Grok 2,需要两万块 H100;而马斯克预测,要训练 Grok 3,可能会需要十万块 H100。
所以,xAI 的数据中心,建得怎么庞大都不过分。
建设速度太快,推测是「部分上线」
122 天,也就是 4 个月的时间,建成 10 万张 H100 组成的超算集群,这是个什么速度?
有业内人士表示,通常完成这样一个集群可能需要一年时间。
这个速度,这个规模,很马斯克。
但也有人猜测,他可能有夸大其词的倾向,高估了在单一集群中实际运行的 GPU 数量。
囤足 10 万张芯片、放在一起共同运行,并不意味着就是单一集群。
论 GPU 数量,Meta 在今年 1 月就已经计划采购 35 万张 H100,但实际运行时是分成了不同集群。
之所以还没有其他公司能造出 10 万 GPU 规模的集群,很难说是因为缺钱,更重要的因素是网络解决方案。
串联起所有 GPU 的网络,需要保证足够的高带宽、低延迟和可靠性,才能让 10 万张芯片协同起来像一台计算机一样工作。

Colossus 是二战期间第一台可编程计算机,也曾在科幻电影里登场
除了网络,还有电力问题。
马斯克此前表示,Colossus 在 6 月底已经启动运行,当时,电力公司供应的最高功率只有几兆瓦,仅能供应数千个 GPU 同时运行。
电力公司表示,到 8 月,xAI 将获得大约 50 兆瓦的电力,但这只能供应大约 5 万个芯片。
与此同时,现场即将建成的另一个发电站将提供另外 150 兆瓦,可以满足 10 万个或更多芯片的电力需求,但要到明年才能实现。
马斯克似乎找到了一个短期解决方案:引入化石能源发电机。
Colossus 所在地,田纳西州孟菲斯的环保组织前几天刚刚写信控诉马斯克,指责他在没有许可的情况下安装了至少 18 台涡轮机(可能更多),加剧了当地的空气污染。

出于网络和电力两方面的限制因素,The Information 指出,马斯克的这个集群可能只是「部分完成」
除了 Colossus 和微软在凤凰城为 OpenAI 建造的超算集群,多个类似的集群也正处在研发和建设过程中。
奥特曼:微软爸爸,我们的算力不够了
尽管如此,马斯克这个超大集群的进展,还是让一些竞争对手极度担心!

其中一位,就是 OpenAI 的 CEO Sam Altman。
根据内部消息,奥特曼已经向一些微软高管透露了自己的担忧——
他十分担心,xAI 很快就拥有比 OpenAI 更多的算力!

虽然为 OpenAI 提供算力的微软老大哥,资金实力非常雄厚,但作为上市公司,微软在花费资金时,还需要对公众股东负责。
但马斯克则完全没有这样的限制,尽管他的资金不如微软。

甭管马斯克有多少吹牛的成分,即使能部分完成 Colossus 集群的建成,也是一件令人印象深刻的事。
外媒 The Information 猜测,马斯克这种神奇的赶工速度,是否放弃了传统的例行安全检查?
毕竟,如果按例检查的话,可能会让数据中心项目的竣工延迟数月。

而且,The Information 还发现了一个「华点」:Colossus 位于以前的制造工厂内,这可不是适合高性能计算的理想场所。
微软和英伟达的高管透露,这是他们最不愿意放置昂贵硬件的地点之一。
因为这些地方很难改造,来适应服务器耗费的巨大电量,和数据中心设备需要的冷却技术。
咱们都知道,马老板一向喜欢突破边界,而在质疑声纷至沓来时,他又经常被证明是正确的。
最近在 xAI 的姊妹公司X,马斯克又有了一个惊人之举:关闭了一个数据中心。
当时大家都担心,X会因此而崩溃。结果谁也没想到,X运行得很好,马斯克居然有如此先见之明。
而这次,马斯克在田纳西州的超算,也同样可能会对 AI 开发者振聋发聩——
或许他们会发现,传统的做事方式如今已经过时了。
两家神秘 AI 巨头,正计划打造 1250 亿美元超算
如今,数据中心之战,竞争还在火热加剧!至少有六大巨头,已经下场了。
根据北达科他州官员的披露,除了微软、OpenAI 和 xAI,还有两家 AI 巨头也正在酝酿建造「巨型 AI 数据中心」。

这两家公司找到了商务专员 Josh Teigen 和州长 Doug Burgum,商讨建立巨型 AI 数据中心。
除了技术研发,这类数据中心也对资源和基础设施提出了很高的要求。
不仅需要采购足够的芯片和相关设备,还要留出数万英亩的土地、建设新的发电设施。
马斯克的 Colossus 要自建发电站才能弄出 200 兆瓦,而这两家公司可能是因为直接找上了州长,他们的初始电力就能达到 500~1000 兆瓦,并计划在几年内扩增至 5k~1w 兆瓦。
这些项目的规模将比现有的任何数据中心,包括 Colossus 都扩大几个数量级。
100 兆瓦可以为 7 万至 10 万个家庭供电;去年微软 Azure 的全球数据中心总共使用了大约 5 吉瓦(5k 兆瓦)的电力。
这就意味着,一个数据中心,可能和整个 Azure 云服务平台的耗电量相当。
根据会议的音频记录,这类规模的项目耗资可能超过 1250 亿美元。
在对外会议上,商务专员 Teigen 没有透露这两家神秘 AI 巨头的名字,但他表示市值达到了「一万亿美元」。
这就将潜在名单缩小到了美国的大约 6 家公司,七巨头之六——英伟达、亚马逊、微软、谷歌、Meta 和苹果。
微软此前就和 OpenAI 讨论过建造价值 1000 亿美元的「星际之门」(Stargate),而且北达科他州长 Doug Burgum 曾是微软的高管,在 2001 年以 11 亿美元向微软出售过自己的一家软件公司。
但我们也知道,谷歌和亚马逊等其他公司也在积极提升其 AI 计算能力。
揭开美国 AI 超算的神秘面纱
AI 巨头一向对尖端技术严格保密,但他们对开发数据中心所需的技术,保密程度有过之而无不及。
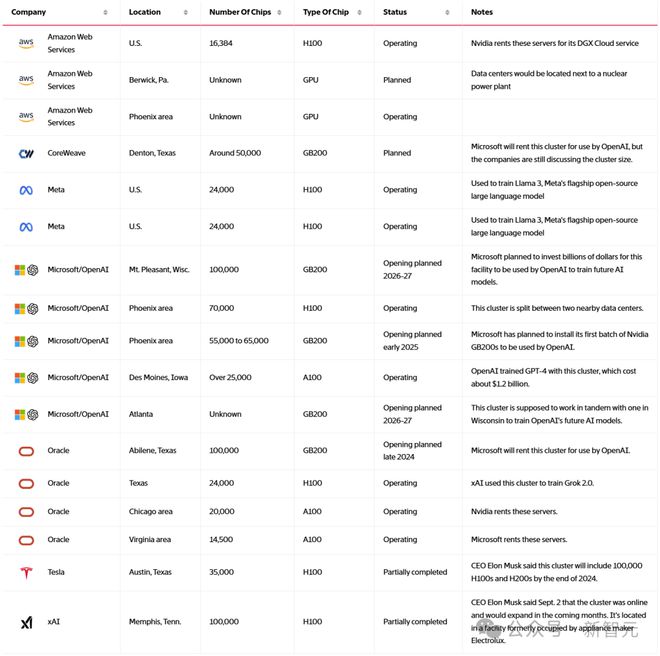
The Information 列出了在美国 7 个州运营或计划中的 17 个超算数据中心,涉及微软、OpenAI、Meta 和 xAI 等公司。
总的来说,仍在开发或计划阶段的设施建设成本可能超过 500 亿美元,其中包括约 350 亿美元的英伟达芯片,以及运营所需的额外数十亿美元。
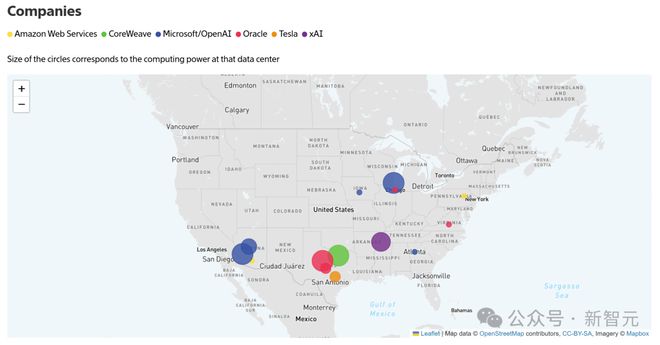
这些超算估计在数年时间内落成,并需要大量的芯片、土地和电力。
在 ChatGPT 问世前,GPU 集群通常只包含几千个芯片。如今,一些最大的 GPU 集群拥有超过 3 万个芯片,上面提到的这些超算更是达到了前所未有的规模。
要为所有计划中的数据中心供电,美国能源部预计会出现电力不足的情况,因此最近提出了一些解决方案,例如资助研究使 AI 计算更高效。
争夺「下一个高地」
现在,数据中心竞赛的焦点,集中到了英伟达 CEO 黄仁勋的身上。
就在上周,老黄发表了以下言论,宛如在业内投入一颗炸弹。
率先达到超算集群下一个高地的人,将实现革命性的 AI 水平。
此言一出,英伟达的 GPU,谁敢不买?
即使已经和博通共同设计出了 TPU 的谷歌,最近也为英伟达即将推出的 Blackwell 下了大单。

对 GPU 的争夺,已经引发了 AI 开发者及其云供应商之间的紧张局势,甚至,有时还会引发它们和英伟达的摩擦。
比如,马斯克就曾考虑和甲骨文达成一项大规模协议,根据他的计划,xAI 将在未来几年内,花费超过 100 亿美元租赁英伟达的 GPU。
而这项谈判最终破裂了,部分原因在于,马斯克认为甲骨文无法足够快地建起超算,而甲骨文则担心,他会把 GPU 集群放在一个供电不足的地方。
芯片多多,问题多多
很多超大的 GPU 集群都位于土地辽阔、空间充裕且电力充足的地区。例如,马斯克的 Colossus 特意选址在田纳西州孟菲斯,亚马逊、Meta 和微软都在亚利桑那州的凤凰城地区运营 AI 服务器。
但随着更大的 GPU 集群需要更多的电力,AI 巨头们正计划在非传统数据中心枢纽的地区建造这些集群。
例如,亚马逊最近在宾夕法尼亚州中部的一座核电站旁边购置了土地,计划供应约一吉瓦(1000 兆瓦)的电力。
这足以为整个旧金山供电,或者构建多达 100 万张 GPU 的集群。
另一个挑战是如何进行设备冷却。
传统上,数据中心一般采用风冷,但 GPU 服务器产生的热量远远超过传统服务器。
为了更佳的冷却效果,微软在威斯康星州为 OpenAI 建设的数据中心预计将使用液冷而非风冷。
毕竟,竞家都 All In 了,你能不上吗?
六巨头割据,群雄逐鹿,谁将夺得下一个超算高地?
参考资料:
https://www.theinformation.com/articles/two-ai-developers-are-plotting-125-billion-supercomputers
https://www.theinformation.com/articles/introducing-the-ai-data-center-database?rc=epv9gi
来自: 网易科技



















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











