







文章目录
python的list
list是python内置基础序列型数据类,也是tuple、dict、set的底层结构,它们的操作都可以通过转换成list来处理. 所以地位重要.
list可以是异构的,是与传统array的最大区别,在大数据处理方面具有高灵活性.

>>> [] #在内存定义一个空list,但无法调用
[]
>>> list()
[]
>>> L1=list() #把定义的空list,赋值给L1,则可以找到地址,进行操作
>>> type(L1)
<class 'list'>
>>>
numpy的array、ndarray
ndarray是Numpy(Numerical Python)的核心的数据结构.是由多个具有相同数据类型和相同长度的元素组成的多维容器. 类似C++ 的Vector容器.但是它基于python语言,所以,它与list形成很好的相容性。

(1)list to ndarray
>>> import numpy as np
>>> ar1=np.array([1,2,3]) #一维
>>> ar1
array([1, 2, 3])
>>> print(ar1)
[1 2 3]
>>>
>>> ar1=np.array([1,a,3]) #警告提示
Warning (from warnings module):
File "__main__", line 1
VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
>>> ar1=np.array([1,'a',3])
>>> print(ar1)
['1' 'a' '3'] #会统一转换为字符,建立一个字符串型‘numpy.ndarray’,元素混合类型的list会自动按照内部规则自动转换为统一的某一种类型
>>>
>>> type(ar1)
<class 'numpy.ndarray'>
>>> ar1.dtype
dtype('<U11')
>>> print(ar1.dtype) #dtype属性存储元素类型
<U11
>>>
#二维ndarray定义
>>> ar2=np.array([[1,2,3],[4,5,6]])
>>> print(ar2)
[[1 2 3]
[4 5 6]]
>>>
>>> ar1.flat #将ndarray迭代器
<numpy.flatiter object at 0x000000000A78AB60>
>>> ar2.flat
<numpy.flatiter object at 0x000000000A78B5B0>
>>> ar1.size #元素数量
3
>>> ar2.size
6
>>>
>>> ar1.flags #一维的缺省的存储方式
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
>>> ar2.flags #二维的缺省的存储方式
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
该容器还有其它丰富属性,对于存储方式解释:
行主序:指数组以一行为单位存储于内存中
列主序:指数组以一列为单位存储于内存中
三维可看成多个二维的数组,那么多个二维数组对象,也有行主序或是列主序问题,依次类推。
(2) ndarray to list
>>> ar2.tolist()
[[1, 2, 3], [4, 5, 6]] #转换为:ar2的每一行作为一个元素的List
>>>
>>> L2=ar2.tolist()
>>> L2
[[1, 2, 3], [4, 5, 6]]
>>> L3=L2[:,0] #提取二维列表某一列,出错
Traceback (most recent call last):
File "<pyshell#113>", line 1, in <module>
L3=L2[:,0]
TypeError: list indices must be integers or slices, not tuple
>>>
需要用迭代:
>>> L3=[x[0] for x in L2] #取第一列
>>> L3
[1, 4]
>>> L4=[x[1] for x in L2] #取第二列
>>> L4
[2, 5]
>>>
pandas的series 与 dataframe
Pandas中的 Series是一个一维标记数组,说明能够容纳任何数据类型
s=pd.Series(data,index=index)

这里data可以是ndarray,dict或标量
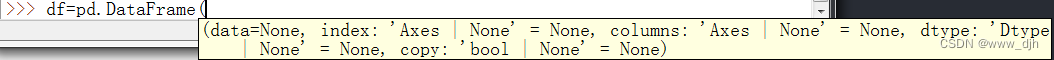
这里的data可以是 ndarray,series,list,dict,标量以及一个 dataframe
>>> ar=np.random.randn(5)
>>> ar
array([-0.81329296, 1.69389815, -0.39909151, -1.46635481, 0.5706054 ])
>>> s=pd.Series(ar,index=['a','a','a','a','a'])#array是numpy的基础数据结构
>>> s
a -0.813293
a 1.693898
a -0.399092
a -1.466355
a 0.570605
dtype: float64
>>> type(s)
<class 'pandas.core.series.Series'>
>>>
另:相对于ndarray(n维的array),series可以是异构的,它与list、dataframe更亲近,
事实上:Series是NDFrame子类,不是ndarray的子类
>>> s=pd.Series([1,2,'a','a','a'],index=['a']*len(ar))
>>> s
a 1
a 2
a a
a a
a a
dtype: object
>>> L2 = s.to_list() #Series转成List,丢失索引
>>> L2
[1, 2, 'a', 'a', 'a']
>>>
(1) ndarray to series
如上节,先定义一数组:
ar1=np.array([1,2,3,4,5])
ar1是没有index的,试着添加对应长度的index,一维的numpy.ndarray就可以转换为pandas.series
>>> s=pd.Series(ar1,index=[chr(i) for i in range(ord('a'), ord('a') + len(ar1))])
>>> s
a 1
b 2
c 3
d 4
e 5
dtype: int32
>>> type(s)
<class 'pandas.core.series.Series'>
>>>
上一节已经演示了:数值型list to array可直接用定义(list元素类型不一致时可能会出乎意料)
(2) series to ndarray
可以通过series的函数values去掉其索引,生成ndarray
>>> s
a 1
b 2
c 3
d 4
e 5
dtype: int32
>>> type(s)
<class 'pandas.core.series.Series'>
>>> ar2=s.values
>>> ar2
array([1, 2, 3, 4, 5])
>>> type(ar2)
<class 'numpy.ndarray'>
另例:
>>> s=pd.Series([1,2,'a','a','a'],index=['a']*5)
>>> ar3=s.values
>>> ar3
array([1, 2, 'a', 'a', 'a'], dtype=object) #竟然是这样的,本以为会出错
>>>type(ar3)
<class 'numpy.ndarray'>
numpy的ndarray与pandas的Series、DataFrame
(1)numpy.array 转 series 再转成dataframe
>>> ar1=np.array([1,2,'a','a','a'])
>>> ar1
array(['1', '2', 'a', 'a', 'a'], dtype='<U11')
>>> df=pd.DataFrame(ar1)
>>> df
0
0 1
1 2
2 a
3 a
4 a #会自动添加列索引、行索引
>>> s=pd.Series(df[0])
>>> s
0 1
1 2
2 a
3 a
4 a
Name: 0, dtype: object //df的列头Name,有的称为feild name,转为该series的属性Name值
>>>
(2)从dataframe中提取按列、按行提取生成series
通过检索dataframe某一列或某一行可以得到一个Series
提取行的方法:
>>> s=pd.Series(df.loc[3])
>>> s
0 a
Name: 3, dtype: object
>>>
改变index
>>> df1=df.set_index(chr(i) for i in range(ord('a'), ord('a') + df.size))
>>> df1
0
a 1
b 2
c a
d a
e a
>>>
修改列name
>>> df2=df1[0].rename('序号')
>>> df2
a 1
b 2
c a
d a
e a
Name: 序号, dtype: object
>>> df2=df1.rename(columns={0:'编号'})
>>> df2
编号
a 1
b 2
c a
d a
e a
>>>
继续从df2内提取name为‘编号的’列,生成一个series
>>> s=pd.Series(df2['编号'])
>>> s
a 1
b 2
c a
d a
e a
Name: 编号, dtype: object
>>>
笔记的主旨在于从数据结构角度理解python的list,numpy的array、ndarray,pandas的series、dataframe关系,以便于理解学习,在使用的时候减少对相关类的属性和方法的单纯记忆。有不当之处,望指正,以助完善。















 3426
3426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









