






张量并行TP
挖坑
流水线并行 PP
经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为:在梯度更新上,Gpipe是同步的,PipeDream是异步的。异步方法更进一步降低了GPU的空转时间比。虽然PipeDream设计更精妙些,但是Gpipe因为其“够用”和浅显易懂,更受大众欢迎(torch的pp接口就基于Gpipe)。因此本文以Gpipe作为流水线并行的范例进行介绍。https://zhuanlan.zhihu.com/p/613196255
gpipe论文 https://arxiv.org/pdf/1811.06965.pdf
naive模型并行
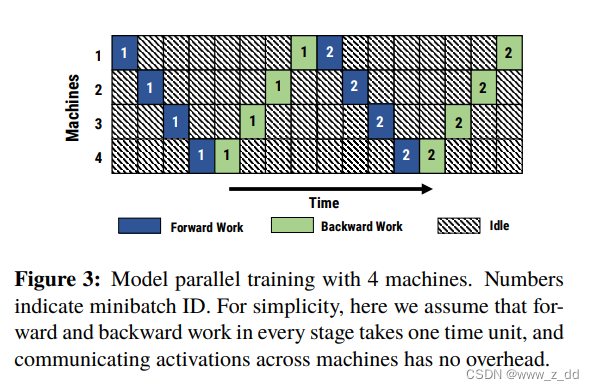
图片来自https://arxiv.org/pdf/1806.03377.pdf
如果一个模型一个gpu放不下,就某些层放在一个卡,上图表示一共四个卡,F0表示第0个batch,灰色的第一个卡计算完第0个batch交给黄色的卡。黄卡上放的模型的层的输入是灰色的卡上放的模型的输出。一次只有一个gpu工作。
GPipe
把mini batch分成micro batch,这样多个gpu可以同时计算。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vWgbtoCx-1691048478616)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/8aa74ef6-308b-48d9-b961-ac72a6031873/Untitled.png)]](https://img-blog.csdnimg.cn/d69d2ead79f340ee8b0864c33cd8381f.png)
具体的算法:
用户定义好L层的网络、前向、损失函数等以后,GPipe 就会将网络划分为 K 个单元,并将第 k 个单元放置在第 k 个加速器上。通信原语自动插入到分区边界,以允许相邻分区之间的数据传输。分区算法最小化所有单元估计成本的方差,以便通过同步所有分区的计算时间来最大化管道的效率。
前向过程:GPipe先把大小为N的minibatch分成M个相等的micro batch,通过 K 个加速器进行流水线处理。在向后传递过程中,每个micro batch通过 K 个加速器进行流水线处理。在向后传递过程中,通过 K 个加速器进行流水线处理。在向后传递过程中,每个micro batch计算梯度都是基于跟前向同一个模型,没有误差哦。每个mini batch的最后,M个micro的梯度都计算完了
在前向计算期间,每个加速器仅存储分区边界处的输出激活。在向后传递期间,第 k 个加速器重新计算复合前向函数 Fk。
在micro-batch的划分下,我们在计算Batch Normalization时会有影响。Gpipe的方法是,在训练时计算和运用的是micro-batch里的均值和方差,但同时持续追踪全部mini-batch的移动平均和方差,以便在测试阶段进行使用。Layer Normalization则不受影响。
总结:
如果模型太大一张卡放不下,按照层来切开,第一层放在第一张卡,第二层放在第二张卡,这样第二层要等第一层的计算结果作为输入,等待的时候卡就空闲了很浪费。
gpipe的做法是batch再切开切成micro batch,这样虽然第一个microbatch的时候要等待,但是多张卡可以同时工作了。
GPipe 还用recomputation这个简单有效的技巧来降低内存,进一步允许训练更大的模型
如何按照层自动划分:根据计算量分配到每张卡
gpipe的micro batch上是需要累计梯度的
重计算,多计算一次前向换空间,但是不是梯度来了从头前向一次,中间有几个激活其实存下来了,叫做checkpoint,然后从checkpoing的激活值的位置前向就行。(因为每张卡上不止一个micro batch,所以激活的数量也是好几份,这个量就比较大)
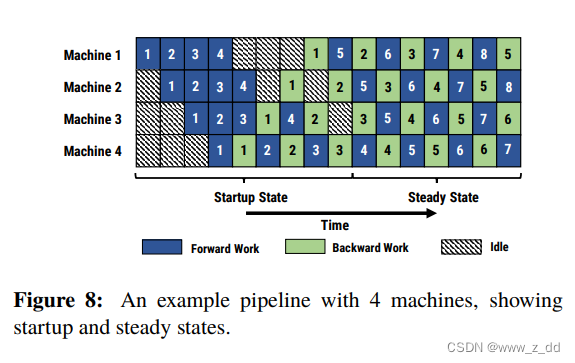
Gpipe流水线其存在两个问题:硬件利用率低,内存占用大。于是在另一篇流水并行的论文里,微软 PipeDream 针对这些问题提出了改进方法,就是1F1B (One Forward pass followed by One Backward pass)策略。
PipeDream
微软在论文 PipeDream: Fast and Efficient Pipeline Parallel DNN Training
PipeDream 模型的基本单位是层,PipeDream将DNN的这些层划分为多个阶段。每个阶段(stage)由模型中的一组连续层组成
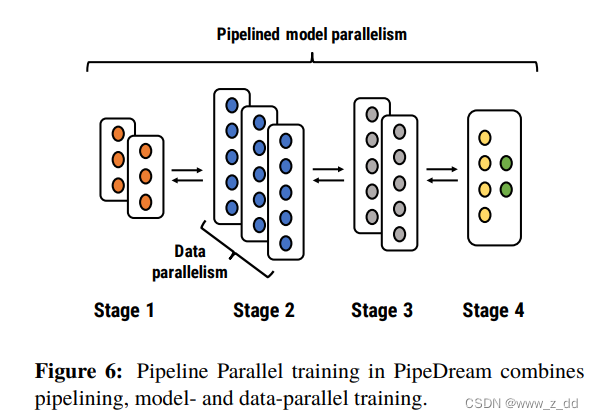
1F1B
由于前向计算的 activation 需要等到对应的后向计算完成后才能释放(无论有没有使用 Checkpointing 技术),因此在流水并行下,如果想尽可能节省缓存 activation 的份数,就要尽量缩短每份 activation 保存的时间,也就是让每份 activation 都尽可能早的释放,所以要让每个 micro-batch 的数据尽可能早的完成后向计算,因此需要把后向计算的优先级提高
参考:
[源码解析] 深度学习流水线并行Gpipe https://www.cnblogs.com/rossiXYZ/
数据并行DP
FSDP
fair scale的fsdp
https://engineering.fb.com/2021/07/15/open-source/fsdp/
Fully Sharded Data Parallel (FSDP) 是一种DP算法,offload一部分计算到cpu。但是模型的参数在多个gpu之间是share的?每个microbatch的计算还是local to每个gpu的
在标准 DDP 训练中,每个工作人员处理一个单独的批次,并使用allreduce对各gpu的梯度进行求和。虽然 DDP 已经变得非常流行,但它占用的 GPU 内存超出了其需要,因为模型权重和优化器状态会在所有 DDP 工作线程之间复制。
FSDP是pytorch1.11的新特性。其新特性目的主要是训练大模型。我们都知道pytorch DDP用起来简单方便,但是要求整个模型能加载一个GPU上,这使得大模型的训练需要使用额外复杂的设置进行模型拆分。pytorch的FSDP从DeepSpeed ZeRO以及FairScale的FSDP中获取灵感,打破模型分片的障碍(包括模型参数,梯度,优化器状态),同时仍然保持了数据并行的简单性。














 8587
8587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









