






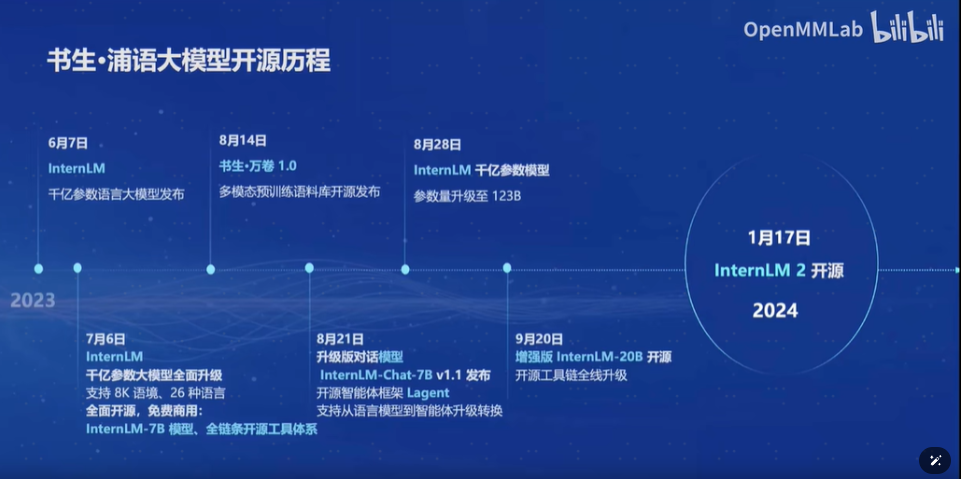
1.书生·浦语大模型开源历程
书生大模型自2021年6月首次发布以来,经历了快速的迭代和发展。在短短一年时间内,书生大模型完成了多次重大升级,包括千亿参数模型的全面升级、支持8K语境和26种语言、推出7B开源模型和全链条工具体系、发布书生万卷1.0多模态预训练语料库、升级对话模型并开源智能体框架等。
2.书生·浦语大模型全链路开源体系
书生大模型的全链条工具体系是其开源开放体系的重要组成部分,涵盖了数据、预训练、微调、部署、评测和应用等多个环节。在数据方面,书生大模型提供了书生万卷和书生外传CC等高质量的多模态数据集。在预训练方面,书生大模型开发了intlevo预训练框架,支持从8卡到千卡级的训练,并实现了92%的加速效率。在微调方面,书生大模型提供了x tuner微调框架,支持增量训练和有监督微调等多种微调策略。在部署方面,书生大模型开发了m deploy部署解决方案,支持模型的轻量化推理和服务。在评测方面,书生大模型发布了open compass评估体系,提供了全面的性能榜单和评测工具链。在应用方面,书生大模型开源了legend智能体框架和agent lego工具箱,支持多种智能体能力和服务。

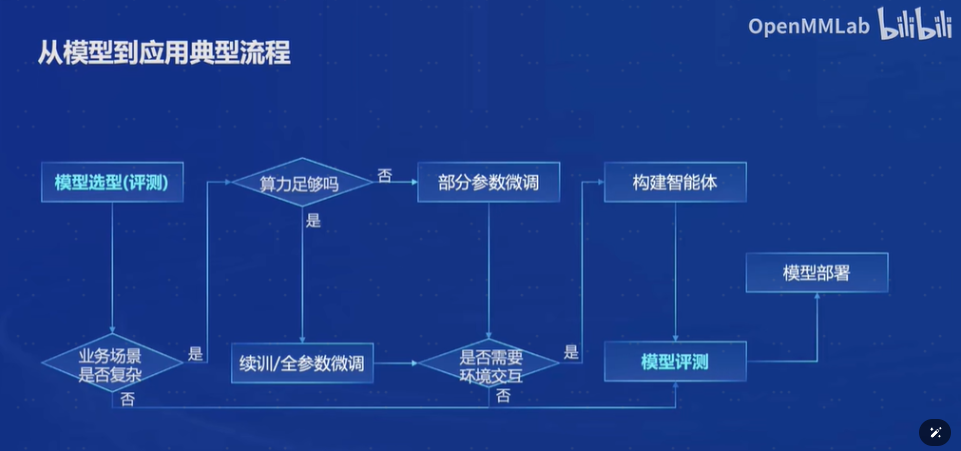
3.模型应用开发流程
模型选型考虑业务场景是否复杂。如果业务场景,比如说是比较复杂业务场景,我们就可能去需要去对模型进行微调。模型微调的话,我们需要进一步去考虑我们目前的算力它是否足够。如果是比如说有充足的算力,我们就可以去进行模型的这种训练或者全参数的微调。如果算力非常有限,可能只能去进行部分参数的微调。然后就构建智能体,模型的评测以及后面的模型部署。
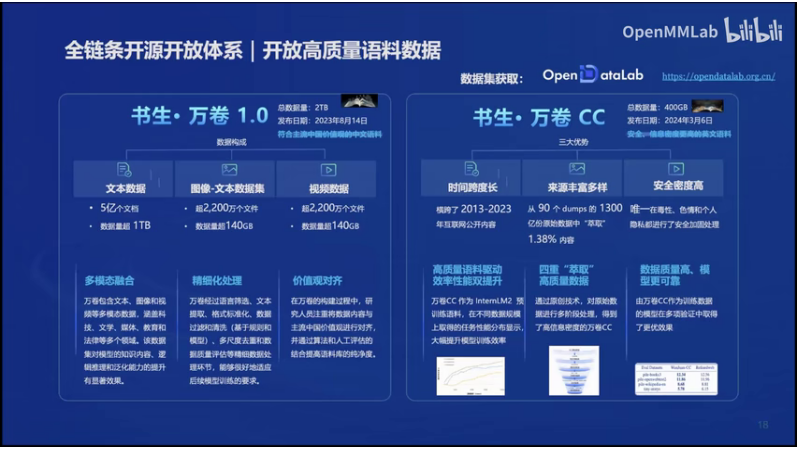
4.开源数据集
数据方面发布了书生万卷1.0这样的一个多模态的数据集。它总数据量其实达到了2个TB,并且它都是符合主流的中国价值观的一些中文语料。里面包括有文本数据,有图像文本的数据,有视频数据。2024年4月又发布书生外传CC,就这样的一个开源的数据集,它其实包包括了从2013年到2023年的互联网的公开内容,它其实是基于CC这样的一个税级,做了非常精细的一些清洗。
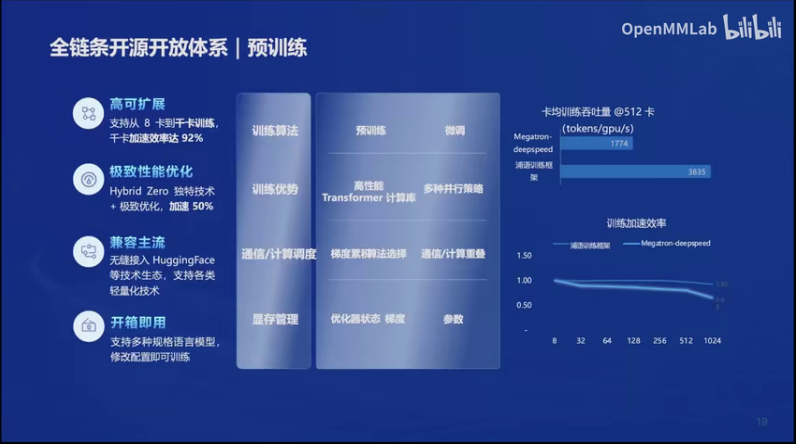
5.预训练&微调
开发了预训练练框架和X Tuner微调框架来实现模型的训练和微调。

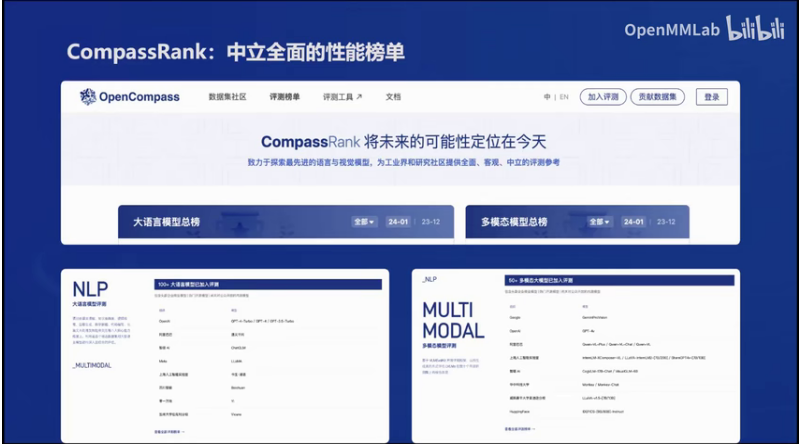
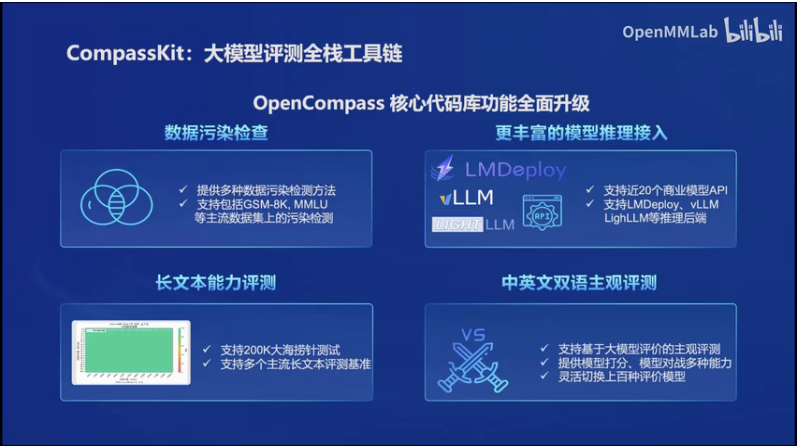
6.模型评测OpenCompass
OpenCompass是一个开源开放的大模型评测平台。OpenCompass构建了一个包含学科、语言、知识、理解、推理五大维度的通用能力评测体系,并支持多种评测指标。
7.模型部署LMDeploy
LMDeploy提供大模型在GPU上部署全流程解决方案,包括模型轻量化、推理和服务。

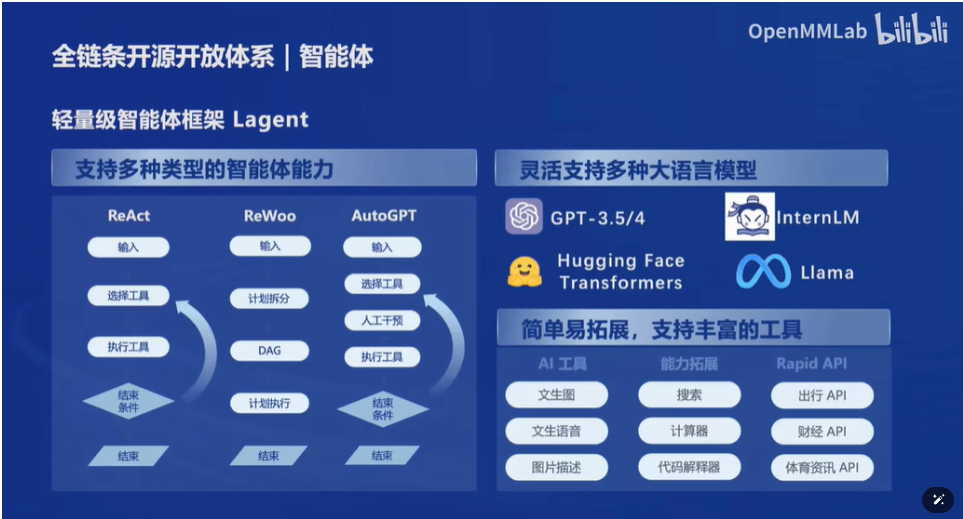
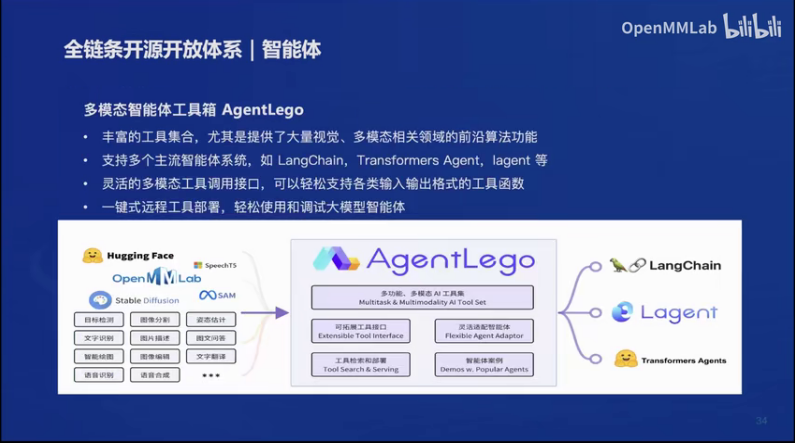
8.轻量级智能体框架Lagent
一个轻量级的智能体框架lagent和多模态智能体工具箱agentlego















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









