







https://www.bilibili.com/video/BV1CL6MYKEGd/?vd_source=c47fbb8166930edc486d8fdc405bf569
(项目作者:BannyLon)
安装环境
pip install docx -i https://pypi.tuna.tsinghua.edu.cn/simple
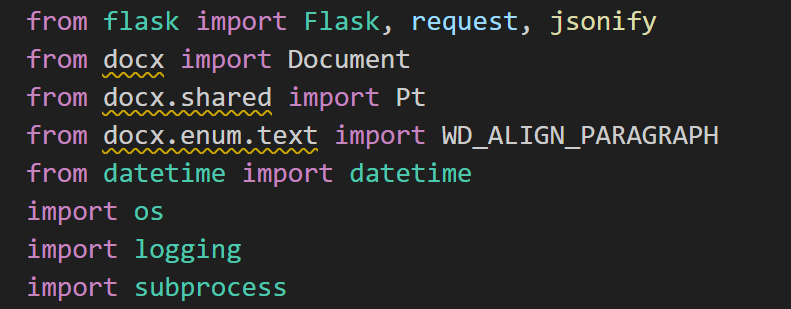
还是有错误:
from docx.shared import Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
pip install python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
代码解析
from flask import Flask, request, jsonify,send_file # 从Flask框架导入核心类Flask、请求处理对象request和JSON响应工具jsonify
from docx import Document # 从python-docx库导入Document类,用于操作Word文档
from docx.shared import Pt #导入Pt类,用于设置字体大小(磅值单位)
from docx.enum.text import WD_ALIGN_PARAGRAPH #导入段落对齐方式枚举
from datetime import datetime #导入日期时间处理模块
import os
import logging
import subprocess
# 导入操作系统接口模块、日志模块和子进程管理模块
app = Flask(__name__)
# 配置日志
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
SAVE_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data')
if not os.path.exists(SAVE_DIR):# DATA_DIR是否存在
os.makedirs(SAVE_DIR)# 创建路径
logging.info(f'DATA_DIR的路径:{SAVE_DIR}')
@app.route('/generate_doc', methods=['POST'])
def generate_doc():
try:
# 获取请求中的JSON数据
data = request.json
print(data)
title = data.get('title')
content = data.get('content')
if not title and not content:
logger.error("Title or content is required")
return jsonify({"error": "Title or content is required"}), 400
# 生成文档
file_name = f"phl_{datetime.now().strftime('%Y%m%d_%H%M%S')}.docx"# 时间磋
file_path = os.path.join(SAVE_DIR, file_name)
logger.debug(f"File path: {file_path}")
doc = Document()
if title:
# 添加大标题
"""
如果有标题则添加一级标题
设置居中对齐
设置仿宋字体
设置22磅(二号)字号
"""
paragraph = doc.add_heading(title, level=1)
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中对齐
paragraph.style.font.name = 'FangSong' # 直接设置整个段落的字体
paragraph.style.font.size = Pt(22) # 二号字体
if content:
# 添加正文
paragraph = doc.add_paragraph(content)
paragraph.style.font.name = 'FangSong' # 直接设置整个段落的字体
paragraph.style.font.size = Pt(10.5) # 五号字体
doc.save(file_path)
logger.info(f"Document generated successfully at {file_path}")
# # 在Mac上打开文件
# subprocess.call(['open', file_path])
download_url = request.host_url + 'download/' + os.path.basename(file_path)
print(download_url)
return {'download_url': download_url}
return jsonify({"message": "Document generated successfully", "file_path": file_path}), 200
except Exception as e:
logger.error(f"Error generating document: {e}")
return jsonify({"error": str(e)}), 500
@app.route('/download/<filename>', methods=['GET'])
def download_file(filename):
file_path = os.path.join('data', filename)
return send_file(file_path, as_attachment=True)
Dify应用
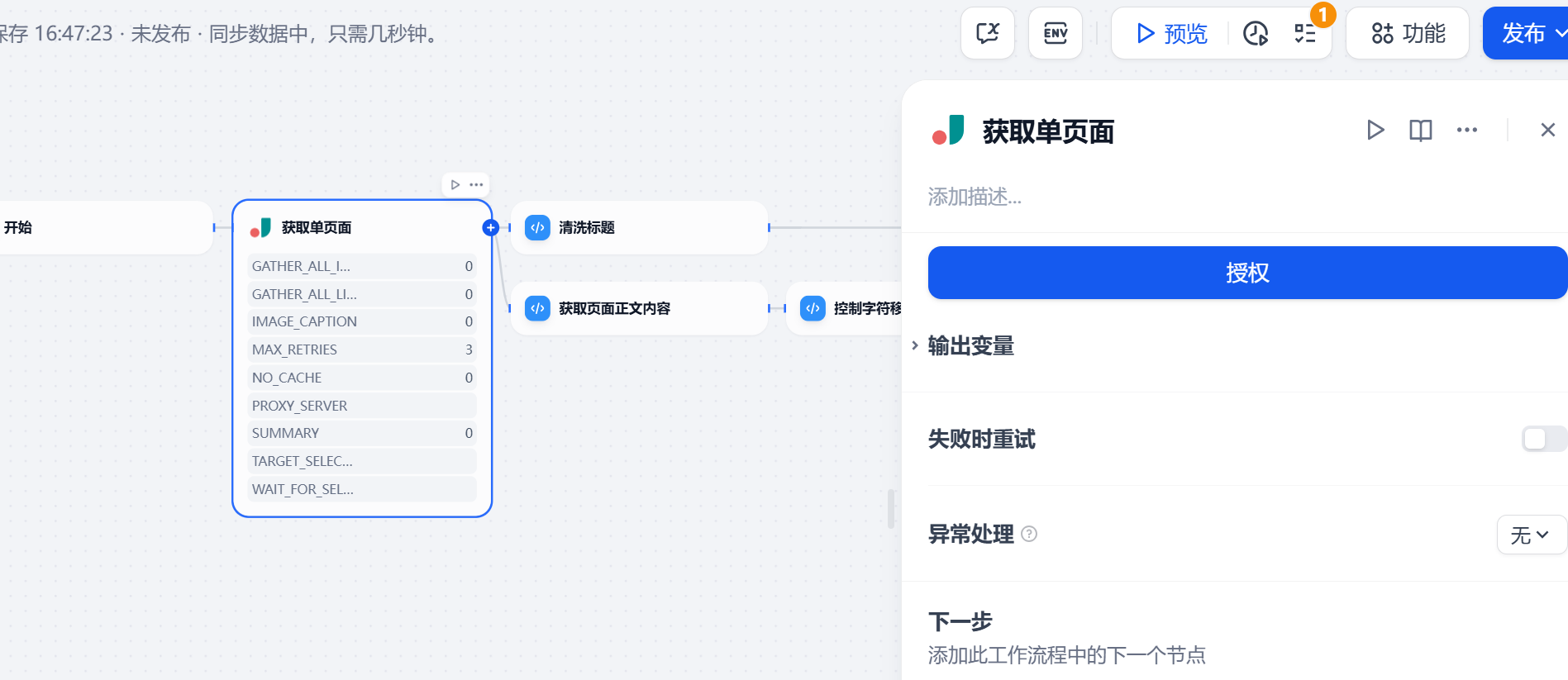
又没有授权
https://geek-docs.com/beautifulsoup/beautifulsoup-questions/373_beautifulsoup_how_to_scrape_through_single_page_application_websites_in_python_using_bs4.html
工具:Jina获取单页面

https://yusjade.github.io/posts/dify_use_knowledge_jina/#:~:text=%E5%9C%A8%20Dify%20%E4%B8%AD%E9%85%8D%E7%BD%AE%20Jina%20%E5%9C%A8%20%E8%AE%BE%E7%BD%AE%20-%20%E6%A8%A1%E5%9E%8B%E4%BE%9B%E5%BA%94%E5%95%86,Reader%20%E9%85%8D%E7%BD%AE%20Jina%20API%20key%EF%BC%8Ckey%20%E5%8F%AF%E4%BB%A5%E9%80%9A%E8%BF%87%E8%AE%BF%E9%97%AE%20Jina%20%E5%AE%98%E7%BD%91%E5%85%8D%E8%B4%B9%E8%8E%B7%E5%BE%97%EF%BC%9Ajina.ai
好吧,我又没有读写的权限


解析这个里面的应用
import json
def main(arg1: str) -> dict:
try:
# 解析 JSON 数据
parsed_data = json.loads(arg1)
# 检查 "data" 是否存在且不是 None
if "data" in parsed_data and parsed_data["data"] is not None:
… return {"result": ""}
# 假设我们有一个 JSON 字符串作为输入
json_string = '{"data": {"title": "Example Title"}}'
# 调用 main 函数并打印结果
print(main(json_string))
获取页面正文
import json
def main(json_str: str) -> dict:
try:
# 解析传入的JSON字符串
data = json.loads(json_str)
# 确保解析结果是一个字典
if not isinstance(data, dict):
raise ValueError("解析结果不是字典类型")
# 获取"data"键下的值
inner_data = data.get('data', {})
# 检查'content'是否存在
content_value = inner_data.get('content', None)
# 返回结果
return {
"result": content_value
}
except json.JSONDecodeError:
# 如果主JSON字符串解析失败,返回错误信息
return {"error": "无法解析JSON字符串"}
except ValueError as e:
# 处理非字典类型的解析结果
return {"error": str(e)}
# 示例输入
json_str = '''{
"json_str": "{\"code\":200,\"status\":20000,\"data\":{\"title\":\"澳鹏appen_全球AI训练数据服务领军者 | 数据标注与采集\",\"description\":\"大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\",\"url\":\"https://www.appendata.com/blogs/fine-tuning\",\"content\":\"2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据以及超级算力资源使得基础模型成为一些头部企业的“特权”。\\n\\n然而,无法自己创建基础模型,并不代表着大模型无法为大部分公司所用:在大量基础模型的开源分享之后,企业可以使用微调(Fine tuning)的方法,训练出适合自己行业和独特用例的大模型以及应用。\\n\\n本文即将讨论大模型微调的定义,重要性,常见方法,流程,以及澳鹏如何帮助您利用大模型进行应用落地。\\n\\n \\n\\n什么是大模型微调?\\n---------\\n\\n大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\\n\\n其根本原理在于,机器学习模型只能够代表它所接收到的数据集的逻辑和理解,而对于其没有获得的数据样本,其并不能很好地识别/理解,且对于大模型而言,也无法很好地回答特定场景下的问题。\\n\\n例如,一个通用大模型涵盖了许多语言信息,并能够进行流畅的对话。但是如果需要医药方面能够很好地回答患者问题的应用,就需要为这个通用大模型提供很多新的数据以供学习和理解。例如,布洛芬到底能否和感冒药同时吃?为了确定模型可以回答正确,我们就需要对基础模型进行微调。\\n\\n \\n\\n为什么大模型需要微调?\\n-----------\\n\\n预训练模型(Pre-trained Model),或者说基础模型(Foundation Model),已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,并没有一个模型可以解决所有的问题,尤其是行业内的专业问答、关于某个组织自身的信息等,是通用大模型所无法触及的。在这种情况下,就需要使用特定的数据集,对合适的基础模型进行微调,以完成特定的任务、回答特定的问题等。在这种情况下,微调就成了重要的手段。\\n\\n \\n\\n大模型微调的两个主要方法\\n------------\\n\\n我们已经讨论了微调的定义和重要性,下面我们介绍一下两个主要的微调方法。根据微调对整个预训练模型的调整程度,微调可以分为全微调和重用两个方法:\\n\\n1. 全微调(Full Fine-tuning):全微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。\\n2. 部分微调(Repurposing):部分微调是指在微调过程中只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。这种方法的目的是在保留预训练模型的通用知识的同时,通过微调顶层来适应特定任务。Repurposing通常适用于目标任务与预训练模型之间有一定相似性的情况,或者任务数据集较小的情况。由于只更新少数层,Repurposing相对于Full Fine-tuning需要较少的计算资源和时间,但在某些情况下性能可能会有所降低。\\n\\n选择Full Fine-tuning还是Repurposing取决于任务的特点和可用的资源。如果任务与预训练模型之间存在较大差异,或者需要模型具有高度自适应能力,那么Full Fine-tuning可能更适合。如果任务与预训练模型相似性较高,或者资源有限,那么Repurposing可能更合适。在实际应用中,根据任务需求和实验结果,可以选择适当的微调方法来获得最佳的性能。\\n\\n \\n\\n大模型微调的两个主要类型\\n------------\\n\\n同时,根据微调使用的数据集的类型,大模型微调还可以分为监督微调和无监督微调两种:\\n\\n1. 监督微调(Supervised Fine-tuning):监督微调是指在进行微调时使用有标签的训练数据集。这些标签提供了模型在微调过程中的目标输出。在监督微调中,通常使用带有标签的任务特定数据集,例如分类任务的数据集,其中每个样本都有一个与之关联的标签。通过使用这些标签来指导模型的微调,可以使模型更好地适应特定任务。\\n2. 无监督微调(Unsupervised Fine-tuning):无监督微调是指在进行微调时使用无标签的训练数据集。这意味着在微调过程中,模型只能利用输入数据本身的信息,而没有明确的目标输出。这些方法通过学习数据的内在结构或生成数据来进行微调,以提取有用的特征或改进模型的表示能力。\\n\\n监督微调通常在有标签的任务特定数据集上进行,因此可以直接优化模型的性能。无监督微调则更侧重于利用无标签数据的特征学习和表示学习,以提取更有用的特征表示或改进模型的泛化能力。这两种微调方法可以单独使用,也可以结合使用,具体取决于任务和可用数据的性质和数量。\\n\\n \\n\\n大模型微调的主要步骤\\n----------\\n\\n大模型微调如上文所述有很多方法,并且对于每种方法都会有不同的微调流程、方式、准备工作和周期。然而大部分的大模型微调,都有以下几个主要步骤,并需要做相关的准备:\\n\\n1. 准备数据集:收集和准备与目标任务相关的训练数据集。确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。\\n2. 选择预训练模型/基础模型:根据目标任务的性质和数据集的特点,选择适合的预训练模型。\\n3. 设定微调策略:根据任务需求和可用资源,选择适当的微调策略。考虑是进行全微调还是部分微调,以及微调的层级和范围。\\n4. 设置超参数:确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。\\n5. 初始化模型参数:根据预训练模型的权重,初始化微调模型的参数。对于全微调,所有模型参数都会被随机初始化;对于部分微调,只有顶层或少数层的参数会被随机初始化。\\n6. 进行微调训练:使用准备好的数据集和微调策略,对模型进行训练。在训练过程中,根据设定的超参数和优化算法,逐渐调整模型参数以最小化损失函数。\\n7. 模型评估和调优:在训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。这有助于提高模型的性能和泛化能力。\\n8. 测试模型性能:在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。这有助于评估模型在实际应用中的表现。\\n9. 模型部署和应用:将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。\\n\\n这些步骤提供了一个一般性的大模型微调流程,但具体的步骤和细节可能会因任务和需求的不同而有所变化。根据具体情况,可以进行适当的调整和优化。\\n\\n然而,虽然微调相对于训练基础模型,已经是相当省时省力的方法,但是微调本身还是需要足量的经验和技术,算力,以及管理和开发成本。为此,澳鹏已经推出一系列定制化服务和产品,助您轻松拥抱大模型。\\n\\n \\n\\n澳鹏帮助您轻松拥抱大模型\\n------------\\n\\n澳鹏为所有希望进军大语言模型应用的企业,提供一系列定制化服务及产品:\\n\\n1. 数据清洗、数据集、采标定制:澳鹏作为人工智能数据行业超过26年的全球领军人,在235+种语言方言方面有深入的研究和大量的数据经验,可以为您提供您需要的使用场景中所需的[多语言数据](https://www.appendata.com/datasets)、定制化[采集](https://www.appendata.com/data-collection)标注、以及多层次[详细标注](https://www.appendata.com/data-annotation),为您的LLM训练提供强大的数据后盾。\\n2. 微调/RLHF:拥有全球超过100万的众包及强大的合作标注团队、经验丰富的管理团队,我们可以为您的模型微调提供巨量的[RLHF支持](https://www.appendata.com/intelligent-llm-development-platform),最大程度减少幻觉(hallucination)的干扰。\\n3. [LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform):由于大语言模型的应用开发,除了训练和微调之外,还需要多方面的开发流程,以提高开发效率、减少开发阻碍。澳鹏自主开发的[LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform),为您提供多层次、多方面的开发者工具,助您快速训练、部署LLM程序。\\n4. LLM应用定制服务:同时,对于没有开发能力的企业,我们强大的数据团队、算法团队,提供全面的[定制服务](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&)。根据您的用例和需求,选择合适的基础模型,并使用最合适的数据进行微调,最后为您部署出您想要的LLM应用。\\n\\n如想进一步了解澳鹏能够为您的LLM应用提供哪些支持,或有相关需求,可以[联系我们](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&),我们的专家团队会为您提供可行建议,或给出服务报价。\\n\\n澳鹏支持全栈式大模型数据服务,包括数据集,模型评估,模型调优;同时,澳鹏智能大模型开发平台与全套标注工具支持您快速部署大模型应用。\",\"usage\":{\"tokens\":3448}}}"
}'''
# 调用函数并打印结果
result = main(json_str)
print(result)
我自己改
因为我没有权限调用,所以就只能测试一下路径,我就改了一下操作

执行代码4-标题的json
def main() :
json_string = '{"data": {"title": "Example Title"}}'
return {
"json_string": json_string,
}
执行代码5-正文
def main() :
json_str = "{\"code\":200,\"status\":20000,\"data\":{\"title\":\"澳鹏appen_全球AI训练数据服务领军者 | 数据标注与采集\",\"description\":\"大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\",\"url\":\"https://www.appendata.com/blogs/fine-tuning\",\"content\":\"2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据以及超级算力资源使得基础模型成为一些头部企业的“特权”。\\n\\n然而,无法自己创建基础模型,并不代表着大模型无法为大部分公司所用:在大量基础模型的开源分享之后,企业可以使用微调(Fine tuning)的方法,训练出适合自己行业和独特用例的大模型以及应用。\\n\\n本文即将讨论大模型微调的定义,重要性,常见方法,流程,以及澳鹏如何帮助您利用大模型进行应用落地。\\n\\n \\n\\n什么是大模型微调?\\n---------\\n\\n大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\\n\\n其根本原理在于,机器学习模型只能够代表它所接收到的数据集的逻辑和理解,而对于其没有获得的数据样本,其并不能很好地识别/理解,且对于大模型而言,也无法很好地回答特定场景下的问题。\\n\\n例如,一个通用大模型涵盖了许多语言信息,并能够进行流畅的对话。但是如果需要医药方面能够很好地回答患者问题的应用,就需要为这个通用大模型提供很多新的数据以供学习和理解。例如,布洛芬到底能否和感冒药同时吃?为了确定模型可以回答正确,我们就需要对基础模型进行微调。\\n\\n \\n\\n为什么大模型需要微调?\\n-----------\\n\\n预训练模型(Pre-trained Model),或者说基础模型(Foundation Model),已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,并没有一个模型可以解决所有的问题,尤其是行业内的专业问答、关于某个组织自身的信息等,是通用大模型所无法触及的。在这种情况下,就需要使用特定的数据集,对合适的基础模型进行微调,以完成特定的任务、回答特定的问题等。在这种情况下,微调就成了重要的手段。\\n\\n \\n\\n大模型微调的两个主要方法\\n------------\\n\\n我们已经讨论了微调的定义和重要性,下面我们介绍一下两个主要的微调方法。根据微调对整个预训练模型的调整程度,微调可以分为全微调和重用两个方法:\\n\\n1. 全微调(Full Fine-tuning):全微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。\\n2. 部分微调(Repurposing):部分微调是指在微调过程中只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。这种方法的目的是在保留预训练模型的通用知识的同时,通过微调顶层来适应特定任务。Repurposing通常适用于目标任务与预训练模型之间有一定相似性的情况,或者任务数据集较小的情况。由于只更新少数层,Repurposing相对于Full Fine-tuning需要较少的计算资源和时间,但在某些情况下性能可能会有所降低。\\n\\n选择Full Fine-tuning还是Repurposing取决于任务的特点和可用的资源。如果任务与预训练模型之间存在较大差异,或者需要模型具有高度自适应能力,那么Full Fine-tuning可能更适合。如果任务与预训练模型相似性较高,或者资源有限,那么Repurposing可能更合适。在实际应用中,根据任务需求和实验结果,可以选择适当的微调方法来获得最佳的性能。\\n\\n \\n\\n大模型微调的两个主要类型\\n------------\\n\\n同时,根据微调使用的数据集的类型,大模型微调还可以分为监督微调和无监督微调两种:\\n\\n1. 监督微调(Supervised Fine-tuning):监督微调是指在进行微调时使用有标签的训练数据集。这些标签提供了模型在微调过程中的目标输出。在监督微调中,通常使用带有标签的任务特定数据集,例如分类任务的数据集,其中每个样本都有一个与之关联的标签。通过使用这些标签来指导模型的微调,可以使模型更好地适应特定任务。\\n2. 无监督微调(Unsupervised Fine-tuning):无监督微调是指在进行微调时使用无标签的训练数据集。这意味着在微调过程中,模型只能利用输入数据本身的信息,而没有明确的目标输出。这些方法通过学习数据的内在结构或生成数据来进行微调,以提取有用的特征或改进模型的表示能力。\\n\\n监督微调通常在有标签的任务特定数据集上进行,因此可以直接优化模型的性能。无监督微调则更侧重于利用无标签数据的特征学习和表示学习,以提取更有用的特征表示或改进模型的泛化能力。这两种微调方法可以单独使用,也可以结合使用,具体取决于任务和可用数据的性质和数量。\\n\\n \\n\\n大模型微调的主要步骤\\n----------\\n\\n大模型微调如上文所述有很多方法,并且对于每种方法都会有不同的微调流程、方式、准备工作和周期。然而大部分的大模型微调,都有以下几个主要步骤,并需要做相关的准备:\\n\\n1. 准备数据集:收集和准备与目标任务相关的训练数据集。确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。\\n2. 选择预训练模型/基础模型:根据目标任务的性质和数据集的特点,选择适合的预训练模型。\\n3. 设定微调策略:根据任务需求和可用资源,选择适当的微调策略。考虑是进行全微调还是部分微调,以及微调的层级和范围。\\n4. 设置超参数:确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。\\n5. 初始化模型参数:根据预训练模型的权重,初始化微调模型的参数。对于全微调,所有模型参数都会被随机初始化;对于部分微调,只有顶层或少数层的参数会被随机初始化。\\n6. 进行微调训练:使用准备好的数据集和微调策略,对模型进行训练。在训练过程中,根据设定的超参数和优化算法,逐渐调整模型参数以最小化损失函数。\\n7. 模型评估和调优:在训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。这有助于提高模型的性能和泛化能力。\\n8. 测试模型性能:在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。这有助于评估模型在实际应用中的表现。\\n9. 模型部署和应用:将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。\\n\\n这些步骤提供了一个一般性的大模型微调流程,但具体的步骤和细节可能会因任务和需求的不同而有所变化。根据具体情况,可以进行适当的调整和优化。\\n\\n然而,虽然微调相对于训练基础模型,已经是相当省时省力的方法,但是微调本身还是需要足量的经验和技术,算力,以及管理和开发成本。为此,澳鹏已经推出一系列定制化服务和产品,助您轻松拥抱大模型。\\n\\n \\n\\n澳鹏帮助您轻松拥抱大模型\\n------------\\n\\n澳鹏为所有希望进军大语言模型应用的企业,提供一系列定制化服务及产品:\\n\\n1. 数据清洗、数据集、采标定制:澳鹏作为人工智能数据行业超过26年的全球领军人,在235+种语言方言方面有深入的研究和大量的数据经验,可以为您提供您需要的使用场景中所需的[多语言数据](https://www.appendata.com/datasets)、定制化[采集](https://www.appendata.com/data-collection)标注、以及多层次[详细标注](https://www.appendata.com/data-annotation),为您的LLM训练提供强大的数据后盾。\\n2. 微调/RLHF:拥有全球超过100万的众包及强大的合作标注团队、经验丰富的管理团队,我们可以为您的模型微调提供巨量的[RLHF支持](https://www.appendata.com/intelligent-llm-development-platform),最大程度减少幻觉(hallucination)的干扰。\\n3. [LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform):由于大语言模型的应用开发,除了训练和微调之外,还需要多方面的开发流程,以提高开发效率、减少开发阻碍。澳鹏自主开发的[LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform),为您提供多层次、多方面的开发者工具,助您快速训练、部署LLM程序。\\n4. LLM应用定制服务:同时,对于没有开发能力的企业,我们强大的数据团队、算法团队,提供全面的[定制服务](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&)。根据您的用例和需求,选择合适的基础模型,并使用最合适的数据进行微调,最后为您部署出您想要的LLM应用。\\n\\n如想进一步了解澳鹏能够为您的LLM应用提供哪些支持,或有相关需求,可以[联系我们](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&),我们的专家团队会为您提供可行建议,或给出服务报价。\\n\\n澳鹏支持全栈式大模型数据服务,包括数据集,模型评估,模型调优;同时,澳鹏智能大模型开发平台与全套标注工具支持您快速部署大模型应用。\",\"usage\":{\"tokens\":3448}}}"
return {
"json_str": json_str,
}
清洗标题
import json
def main(arg1: str) -> dict:
try:
# 解析 JSON 数据
parsed_data = json.loads(arg1)
# 检查 "data" 是否存在且不是 None
if "data" in parsed_data and parsed_data["data"] is not None:
# 获取 title 字段
title = parsed_data["data"].get("title", "")
else:
title = ""
# 返回结果
return {"result": title}
except json.JSONDecodeError:
# 如果 JSON 解码失败,返回空的结果
return {"result": ""}
# 假设我们有一个 JSON 字符串作为输入
json_string = '{"data": {"title": "Example Title"}}'
# 调用 main 函数并打印结果
print(main(json_string))
获得正文
import json
def main(json_str: str) -> dict:
try:
# 解析传入的JSON字符串
data = json.loads(json_str)
# 确保解析结果是一个字典
if not isinstance(data, dict):
raise ValueError("解析结果不是字典类型")
# 获取"data"键下的值
inner_data = data.get('data', {})
# 检查'content'是否存在
content_value = inner_data.get('content', None)
# 返回结果
return {
"result": content_value
}
except json.JSONDecodeError:
# 如果主JSON字符串解析失败,返回错误信息
return {"result": "无法解析JSON字符串"}
except ValueError as e:
# 处理非字典类型的解析结果
return {"result": str(e)}
# 示例输入
json_str = '''{
"json_str": "{\"code\":200,\"status\":20000,\"data\":{\"title\":\"澳鹏appen_全球AI训练数据服务领军者 | 数据标注与采集\",\"description\":\"大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\",\"url\":\"https://www.appendata.com/blogs/fine-tuning\",\"content\":\"2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据以及超级算力资源使得基础模型成为一些头部企业的“特权”。\\n\\n然而,无法自己创建基础模型,并不代表着大模型无法为大部分公司所用:在大量基础模型的开源分享之后,企业可以使用微调(Fine tuning)的方法,训练出适合自己行业和独特用例的大模型以及应用。\\n\\n本文即将讨论大模型微调的定义,重要性,常见方法,流程,以及澳鹏如何帮助您利用大模型进行应用落地。\\n\\n \\n\\n什么是大模型微调?\\n---------\\n\\n大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。\\n\\n其根本原理在于,机器学习模型只能够代表它所接收到的数据集的逻辑和理解,而对于其没有获得的数据样本,其并不能很好地识别/理解,且对于大模型而言,也无法很好地回答特定场景下的问题。\\n\\n例如,一个通用大模型涵盖了许多语言信息,并能够进行流畅的对话。但是如果需要医药方面能够很好地回答患者问题的应用,就需要为这个通用大模型提供很多新的数据以供学习和理解。例如,布洛芬到底能否和感冒药同时吃?为了确定模型可以回答正确,我们就需要对基础模型进行微调。\\n\\n \\n\\n为什么大模型需要微调?\\n-----------\\n\\n预训练模型(Pre-trained Model),或者说基础模型(Foundation Model),已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,并没有一个模型可以解决所有的问题,尤其是行业内的专业问答、关于某个组织自身的信息等,是通用大模型所无法触及的。在这种情况下,就需要使用特定的数据集,对合适的基础模型进行微调,以完成特定的任务、回答特定的问题等。在这种情况下,微调就成了重要的手段。\\n\\n \\n\\n大模型微调的两个主要方法\\n------------\\n\\n我们已经讨论了微调的定义和重要性,下面我们介绍一下两个主要的微调方法。根据微调对整个预训练模型的调整程度,微调可以分为全微调和重用两个方法:\\n\\n1. 全微调(Full Fine-tuning):全微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。\\n2. 部分微调(Repurposing):部分微调是指在微调过程中只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。这种方法的目的是在保留预训练模型的通用知识的同时,通过微调顶层来适应特定任务。Repurposing通常适用于目标任务与预训练模型之间有一定相似性的情况,或者任务数据集较小的情况。由于只更新少数层,Repurposing相对于Full Fine-tuning需要较少的计算资源和时间,但在某些情况下性能可能会有所降低。\\n\\n选择Full Fine-tuning还是Repurposing取决于任务的特点和可用的资源。如果任务与预训练模型之间存在较大差异,或者需要模型具有高度自适应能力,那么Full Fine-tuning可能更适合。如果任务与预训练模型相似性较高,或者资源有限,那么Repurposing可能更合适。在实际应用中,根据任务需求和实验结果,可以选择适当的微调方法来获得最佳的性能。\\n\\n \\n\\n大模型微调的两个主要类型\\n------------\\n\\n同时,根据微调使用的数据集的类型,大模型微调还可以分为监督微调和无监督微调两种:\\n\\n1. 监督微调(Supervised Fine-tuning):监督微调是指在进行微调时使用有标签的训练数据集。这些标签提供了模型在微调过程中的目标输出。在监督微调中,通常使用带有标签的任务特定数据集,例如分类任务的数据集,其中每个样本都有一个与之关联的标签。通过使用这些标签来指导模型的微调,可以使模型更好地适应特定任务。\\n2. 无监督微调(Unsupervised Fine-tuning):无监督微调是指在进行微调时使用无标签的训练数据集。这意味着在微调过程中,模型只能利用输入数据本身的信息,而没有明确的目标输出。这些方法通过学习数据的内在结构或生成数据来进行微调,以提取有用的特征或改进模型的表示能力。\\n\\n监督微调通常在有标签的任务特定数据集上进行,因此可以直接优化模型的性能。无监督微调则更侧重于利用无标签数据的特征学习和表示学习,以提取更有用的特征表示或改进模型的泛化能力。这两种微调方法可以单独使用,也可以结合使用,具体取决于任务和可用数据的性质和数量。\\n\\n \\n\\n大模型微调的主要步骤\\n----------\\n\\n大模型微调如上文所述有很多方法,并且对于每种方法都会有不同的微调流程、方式、准备工作和周期。然而大部分的大模型微调,都有以下几个主要步骤,并需要做相关的准备:\\n\\n1. 准备数据集:收集和准备与目标任务相关的训练数据集。确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。\\n2. 选择预训练模型/基础模型:根据目标任务的性质和数据集的特点,选择适合的预训练模型。\\n3. 设定微调策略:根据任务需求和可用资源,选择适当的微调策略。考虑是进行全微调还是部分微调,以及微调的层级和范围。\\n4. 设置超参数:确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。\\n5. 初始化模型参数:根据预训练模型的权重,初始化微调模型的参数。对于全微调,所有模型参数都会被随机初始化;对于部分微调,只有顶层或少数层的参数会被随机初始化。\\n6. 进行微调训练:使用准备好的数据集和微调策略,对模型进行训练。在训练过程中,根据设定的超参数和优化算法,逐渐调整模型参数以最小化损失函数。\\n7. 模型评估和调优:在训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。这有助于提高模型的性能和泛化能力。\\n8. 测试模型性能:在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。这有助于评估模型在实际应用中的表现。\\n9. 模型部署和应用:将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。\\n\\n这些步骤提供了一个一般性的大模型微调流程,但具体的步骤和细节可能会因任务和需求的不同而有所变化。根据具体情况,可以进行适当的调整和优化。\\n\\n然而,虽然微调相对于训练基础模型,已经是相当省时省力的方法,但是微调本身还是需要足量的经验和技术,算力,以及管理和开发成本。为此,澳鹏已经推出一系列定制化服务和产品,助您轻松拥抱大模型。\\n\\n \\n\\n澳鹏帮助您轻松拥抱大模型\\n------------\\n\\n澳鹏为所有希望进军大语言模型应用的企业,提供一系列定制化服务及产品:\\n\\n1. 数据清洗、数据集、采标定制:澳鹏作为人工智能数据行业超过26年的全球领军人,在235+种语言方言方面有深入的研究和大量的数据经验,可以为您提供您需要的使用场景中所需的[多语言数据](https://www.appendata.com/datasets)、定制化[采集](https://www.appendata.com/data-collection)标注、以及多层次[详细标注](https://www.appendata.com/data-annotation),为您的LLM训练提供强大的数据后盾。\\n2. 微调/RLHF:拥有全球超过100万的众包及强大的合作标注团队、经验丰富的管理团队,我们可以为您的模型微调提供巨量的[RLHF支持](https://www.appendata.com/intelligent-llm-development-platform),最大程度减少幻觉(hallucination)的干扰。\\n3. [LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform):由于大语言模型的应用开发,除了训练和微调之外,还需要多方面的开发流程,以提高开发效率、减少开发阻碍。澳鹏自主开发的[LLM智能开发平台](https://www.appendata.com/intelligent-llm-development-platform),为您提供多层次、多方面的开发者工具,助您快速训练、部署LLM程序。\\n4. LLM应用定制服务:同时,对于没有开发能力的企业,我们强大的数据团队、算法团队,提供全面的[定制服务](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&)。根据您的用例和需求,选择合适的基础模型,并使用最合适的数据进行微调,最后为您部署出您想要的LLM应用。\\n\\n如想进一步了解澳鹏能够为您的LLM应用提供哪些支持,或有相关需求,可以[联系我们](https://www.appendata.com/contact?from=%2Fblogs%2Ffine-tuning&),我们的专家团队会为您提供可行建议,或给出服务报价。\\n\\n澳鹏支持全栈式大模型数据服务,包括数据集,模型评估,模型调优;同时,澳鹏智能大模型开发平台与全套标注工具支持您快速部署大模型应用。\",\"usage\":{\"tokens\":3448}}}"
}'''
最终Wrod结果

思考
感觉这个不太行,就是没有换行符
可能就是标题格式换了
可能还有图片那种没有加入
我记得之前有一个文章写了word还插入图片的,而且我之前写md转word也在之前写过。
所以这些是可以改进的。


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











