







概念: TF-IDF是一种用于资讯检索与资讯探测常用加权技术
评估一个字词对于一个文件集或一个语料库中一份文件的重要程度
字词的重要性随着它在文件中华出现的次数成正比增加
但同时会随着它在语料库中出现的频率成反比下降
TF:词频 某一个给定的词语在一份给定的文件中出现的次数,这个数字通常会被归一化(分子一般小于分母,区别于IDF),防止偏向长的文件
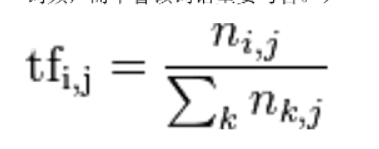
n是词在文件中出现的次数,分母是在文件中所有字词出现的次数之和
逆向文件频率一个词语普遍重要性的度量
第一步操作:
将所有的词按照
词语_微博id 出现次数
mapper方法
package com.zyd.tfidf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
public class FirstMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//3823890210294392 今天我约了豆浆,油条
String[] v = value.toString().trim().split("\t");
if (v.length>=2){
//id
String id = v[0].trim();
//内容
String content = v[1].trim();
StringReader sr = new StringReader(content);
//分词器
IKSegmenter ikSegmenter = new IKSegmenter(sr,true);
Lexeme word = null;
while ((word = ikSegmenter.next())!=null){
String w = word.getLexemeText();
//今天_3823890210294392 1
context.write(new Text(w+"_"+id),new IntWritable(1));
}
//count 1
context.write(new Text("count"),new IntWritable(1));
}else {
System.out.println(value.toString()+"------------");
}
}
}
reducer方法
package com.zyd.tfidf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FirstReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : values){
sum += i.get();
}
if (key.equals(new Text("count"))){
System.out.println(key.toString()+"__________"+sum);
}
context.write(key,new IntWritable(sum));
}
}
分区
package com.zyd.tfidf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class FirstPartition extends HashPartitioner<Text,IntWritable> {
public int getPartition(Text key, IntWritable value, int reduceCount) {
if (key.equals(new Text("count")))
return 3;
else
return super.getPartition(key,value,reduceCount-1);
}
}
驱动类
package com.zyd.tfidf;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FirstJob {
public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1 加载配置信息和job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 指定程序jar包所在的本地路径
job.setJarByClass(FirstJob.class);
//3 指定本业务job需要使用的mapper和reducer类
job.setMapperClass(FirstMapper.class);
job.setReducerClass(FirstReduce.class);
//4 指定mapper输出数据k,v类型 词_id 个数
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 指定输出数据的k,v数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置分区
job.setPartitionerClass(FirstPartition.class);
job.setNumReduceTasks(4);
//设置合并
job.setCombinerClass(FirstReduce.class);
//6 指定job的输入原始文件目录和输出文件目录
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7 将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
}
}
第二步操作:
分析将所有的词在其他微博里面出现的次数
Mapper
package com.zyd.tfidf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class TwoMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取当前mapper task的数据片段
FileSplit fs = (FileSplit) context.getInputSplit();
if (!fs.getPath().getName().contains("part-r-00003")){
//豆浆_3823890201582094 3
String[] v = value.toString().trim().split("\t");
//词语的长度大于等于2
if (v.length >= 2){
//豆浆_3823890201582094
String[] ss = v[0].split("_");
if (ss.length >= 2){
//豆浆
String w = ss[0];
context.write(new Text(w),new IntWritable(1));
}
}else {
System.out.println(value.toString());
}
}
}
}
Reducer方法
package com.zyd.tfidf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TowReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : values){
sum += i.get();
}
context.write(key,new IntWritable(sum));
}
}
驱动类
package com.zyd.tfidf;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TwoJob {
public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1 加载配置信息和job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 指定程序jar包所在的本地路径
job.setJarByClass(TwoJob.class);
//3 指定本业务job需要使用的mapper和reducer类
job.setMapperClass(TwoMapper.class);
job.setReducerClass(TowReduce.class);
//4 指定mapper输出数据k,v类型 词_id 个数
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 指定输出数据的k,v数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6 指定job的输入原始文件目录和输出文件目录
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7 将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
}
}
第三步:相除获取其值
Mapper代码
package com.zyd.tfidf;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.*;
import java.net.URI;
import java.text.NumberFormat;
import java.util.HashMap;
import java.util.Map;
public class LastMapper extends Mapper<LongWritable,Text,Text,Text> {
// 存放微博总数
public static Map<String, Integer> cmap = null;
// 存放df
public static Map<String, Integer> df = null;
// 在map方法执行之前
protected void setup(Context context) throws IOException
{
System.out.println("******************");
//如果判断全部都没有map
if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) {
URI[] ss = context.getCacheFiles();
if (ss != null) {
for (int i = 0; i < ss.length; i++) {
URI uri = ss[i];
if (uri.getPath().endsWith("part-r-00003")) {// 微博总数
// FileSystem fs
// =FileSystem.get(context.getConfiguration());
// fs.open(path);
//读取pd.txt文件,并把文件数据存储到缓存(集合)
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("f:/testoutput/outputidf/part-r-00003")));
String line = br.readLine();
if (line.startsWith("count")) {
String[] ls = line.split("\t");
cmap = new HashMap();
cmap.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
} else if (uri.getPath().endsWith("part-r-00000")) {// 词条的DF
df = new HashMap();
Path path = new Path(uri.getPath());
//BufferedReader br = new BufferedReader(new FileReader(path.getName()));
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("f:/testoutput/outputidf3/part-r-00000")));
String line;
while ((line = br.readLine()) != null) {
String[] ls = line.split("\t");
df.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
}
}
}
}
}
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
FileSplit fs = (FileSplit) context.getInputSplit();
// System.out.println("--------------------");
if (!fs.getPath().getName().contains("part-r-00003")) {
//豆浆_3823930429533207 2
String[] v = value.toString().trim().split("\t");
if (v.length >= 2) {
int tf = Integer.parseInt(v[1].trim());// tf值
String[] ss = v[0].split("_");
if (ss.length >= 2) {
String w = ss[0];
String id = ss[1];
double s = tf * Math.log(cmap.get("count") / df.get(w));
NumberFormat nf = NumberFormat.getInstance();
nf.setMaximumFractionDigits(5);
context.write(new Text(id), new Text(w + ":" + nf.format(s)));
}
} else {
System.out.println(value.toString() + "-------------");
}
}
}
}
Reducer代码
package com.zyd.tfidf;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LastReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text i : values) {
sb.append(i.toString() + "\t");
}
context.write(key, new Text(sb.toString()));
}
}
驱动类代码
package com.zyd.tfidf;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class LastJob {
public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
//1 加载配置信息和job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 指定程序jar包所在的本地路径
job.setJarByClass(LastJob.class);
//3 指定本业务job需要使用的mapper和reducer类
//缓存文件
//把微博总数加载到
job.addCacheFile(new URI("file:/f:/testoutput/outputidf/part-r-00003"));
//把df加载到
job.addCacheFile(new URI("file:/f:/testoutput/outputidf3/part-r-00000"));
job.setMapperClass(LastMapper.class);
job.setReducerClass(LastReducer.class);
//4 指定mapper输出数据k,v类型 词_id 个数
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//5 指定输出数据的k,v数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6 指定job的输入原始文件目录和输出文件目录
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7 将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
}
}
















 1938
1938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









