







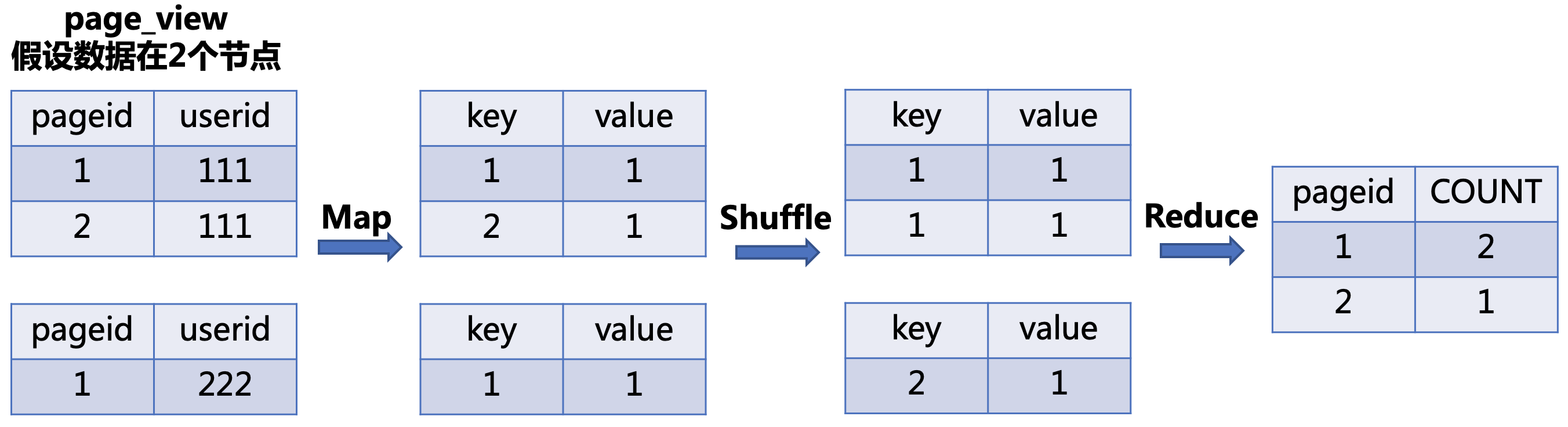
(1)hive并不是所有的查询都需要走MR
hive的优化中fetch抓取,就是修改配置文件参数hive.fetch.task.conversion为more
这样全局查找、字段查找、过滤查询、limit查询,都不会走MR,直接fetch抓取,提高查询效率(其余的还是走MR)
ps:该参数设置为none时,所有任务转化为MR,一般默认是more
(2)hive中需要走MR的sql,通常涉及key的shuffle,比如join、group by、distinct等
以下参照链接:HiveSQL转化为MapReduce任务
~~~join任务转化为mr的流程:
select table1.a,table2.b from table1 join table2 on table1.c=table2.c;

map:生成kv,以join on条件中的列c作为key,以join之后需要查询的列a或者b作为value,在value中还会记录表的标记tag
也就是生成kv:c——(tag,table1.a)和c——(tag,table2.b)
shuffle:根据key的值进行hash,将hash结果一致的kv发送给同一个reducer
reduce:reducer通过tag来识别不同表中的数据,根据key值进行join操作,将key值相等的数据中,来自不同tag的value值进行配对
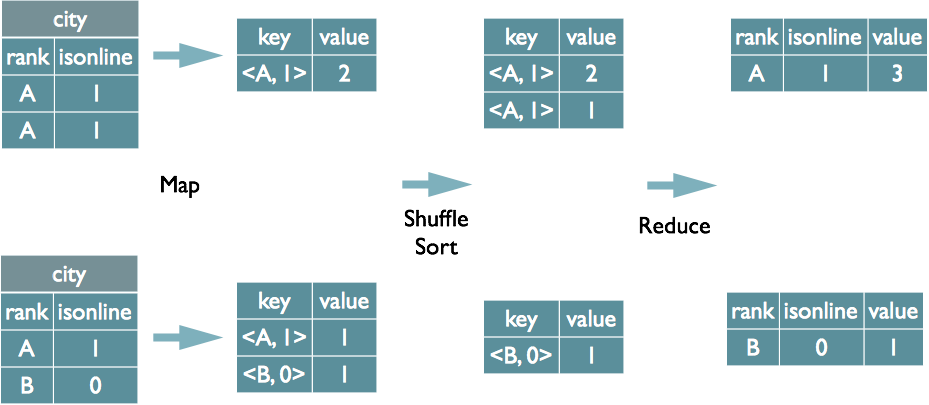
~~~~group by任务转化为mr的流程:
select a,count(1) as num from table group by a
map:生成kv,以group by条件中的聚合列a作为key值,以聚合函数count(1)的结果作为value值
shuffle:根据key的值进行hash,将hash结果一致的kv发送给同一个reducer
reduce:根据select子句的列和count(1)函数进行reduce端的全局聚合
ps:如果select不接聚合函数,直接排序对key分组排序最后输出,一样的MR流程,只是value为空了,如果group by多个字段,则key也有多个<A,B>,value是聚合函数的结果
~~~~distinct任务转化为mr的流程:
相当于没有聚集函数的group by,操作相同,value可以为空
select distinct a from table(去重操作)
(3)hive中需要走MR,但是没有reduce端的情况,也就是mapjoin的优化原理
当小表join大表时,将小表的数据,先转化为hashtable格式,再上传至分布式缓存中
然后开启没有reduce端的MR任务,处理大表,在map端依据大表的每一条记录,去与缓存中小表对应的hashtable关联进行两表连接,在map端就完成聚合操作
由于没有reduce,所以有多少个maptask任务,就输出多少个结果文件















 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









