






你是否在寻找数学建模比赛的突破点?数学建模进阶思路!
作为经验丰富的数学建模团队,我们将为你带来2024长三角高校数学建模竞赛(B题)的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,帮助你全面理解并掌握如何解决类似问题。
长三角(ABC题)完整内容可以在文章末尾领取!。
第一个问题是对题目所给数据进行预处理,明确处理数据的必要性和所采用的处理方法,并尝试通过分子id预测y2。 首先,对题目所给数据进行预处理的必要性在于:数据预处理是数据分析的基础,它可以帮助我们更好地理解数据,发现数据中的规律和特征,为后续建模和分析提供更好的数据基础。在本题中,我们需要对数据进行预处理的主要原因有以下几点:
-
数据量较大:原始数据集data.csv中有20万个分子的数据,每个分子有103个物理化学性质,这样的数据量对于人工分析来说是非常庞大的,因此需要通过预处理来提取有效的信息。
-
数据存在缺失值:在实际的数据分析中,经常会遇到数据缺失的情况,而缺失值会影响后续的数据分析和建模结果。因此,需要对数据进行预处理来处理缺失值,以保证后续的分析和建模的准确性。
-
数据存在噪声:在实际的数据采集过程中,由于各种原因,数据中可能会存在一些噪声,这些噪声会影响后续的数据分析和建模结果。因此,需要对数据进行预处理来去除噪声,以提高后续分析和建模的准确性。
针对以上的原因,我们采用以下的处理方法对数据进行预处理:
-
数据清洗:首先,我们需要对数据进行清洗,去除数据中的缺失值和噪声。具体来说,我们可以通过填充缺失值或者删除缺失值的方式来处理缺失值,通过平滑或者滤波的方式来去除噪声。
-
数据变换:为了更好地理解数据,我们可以对数据进行变换,使得数据更加符合我们的分析需求。具体来说,我们可以对数据进行标准化、归一化、对数变换等,以便后续的分析和建模。
-
特征选择:在数据预处理的过程中,我们可以通过特征选择的方式来提取数据中的有效信息。具体来说,我们可以通过统计学方法、机器学习方法等来选择对预测结果有影响的特征指标,从而提高模型的预测精度。
针对本题中的y2指标,我们可以通过分子id来预测它的值。具体来说,我们可以通过构建一个回归模型来预测y2的值,其中分子id作为自变量,y2作为因变量。通过回归模型,我们可以得到分子id与y2之间的函数关系,从而实现对y2的预测。
在预测过程中,我们可以采用交叉验证的方法来评估模型的性能,从而选择最优的模型。具体来说,我们可以将数据集分为训练集和测试集,通过训练集来构建模型,然后通过测试集来评估模型的性能。在评估过程中,我们可以采用均方误差、平均绝对误差等指标来衡量模型的预测能力,从而选择最优的模型。
最后,我们可以将predict.csv中的分子id作为自变量,通过构建的最优模型来预测y2的值,并将预测结果填入附件submit.csv文件中。
首先,对于题目所给的数据,我们需要进行预处理的原因有以下几点:
-
数据中存在缺失值:通过查看原始数据集,我们发现部分分子的物理化学性质数据存在缺失值,这会影响我们建立预测模型的准确性,因此需要对缺失值进行处理。
-
数据中存在异常值:异常值是指与大部分数据明显不同的数据,它们可能是由于测量误差或其他因素引起的,这些异常值会影响模型的准确性,因此需要对异常值进行处理。
-
数据中存在量纲不一致的问题:原始数据中的物理化学性质指标具有不同的量纲,这会影响模型的训练和预测,因此需要对数据进行标准化处理。
针对以上问题,我们采用以下方法进行数据的预处理:
-
缺失值处理:对于缺失值,我们采用均值填充的方法进行处理,即用该指标的平均值来替换缺失值。
-
异常值处理:对于异常值,我们采用箱线图的方法进行识别和处理,即将超过上下四分位数1.5倍的数据视为异常值,然后用该指标的中位数来代替异常值。
-
数据标准化:我们采用Z-score标准化的方法对数据进行处理,即将每个指标的数据减去该指标的均值,再除以该指标的标准差。
接下来,我们尝试通过分子id预测y2。根据题目给出的数据,我们可以将分子id作为自变量,将y2作为因变量,建立一个简单的线性回归模型来预测y2,即:

import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 读取数据集
data = pd.read_csv('data.csv')
# 数据预处理
# 删除id列
data = data.drop(['id'], axis=1)
# 将数据集分为训练集和测试集
train = data.iloc[:200000, :]
test = data.iloc[200000:, :]
# 将y2作为目标变量,其他变量作为特征变量
X_train = train.drop(['y2'], axis=1)
y_train = train['y2']
X_test = test.drop(['y2'], axis=1)
~~~~问题 2:对附件data.csv中的y2、y3和x1~x100进行数据分析,选择不超过10个特征指标,建立y1的预测模型,将predict.csv预测结果填入附件submit.csv文件中。
问题 2数学建模:
-
数据预处理:首先对数据进行清洗,去除缺失值和异常值。然后对数据进行标准化处理,使得数据具有相同的量纲,便于后续建模分析。
-
数据分析:通过对数据的可视化分析,可以发现y1与y2、y3和x1~x100之间存在一定的相关性。因此,可以考虑使用线性回归模型来建立y1的预测模型。
-
特征选择:通过相关性分析和主成分分析等方法,选择与y1相关性较高的特征指标。由于题目要求不超过10个特征指标,因此可以选择与y1相关性最高的10个指标。
-
建立模型:根据选取的特征指标,建立线性回归模型,如下所示: y1 = w0 + w1x1 + w2x2 + ... + w10x10 其中,w0为截距,w1~w10为特征指标的系数。
-
模型评估:使用交叉验证等方法对模型进行评估,选择最优的模型。
-
预测结果:使用建立的模型对predict.csv中的数据进行预测,将预测结果填入附件submit.csv文件中。
-
结果分析:通过比较预测结果与真实值,对模型的预测能力进行评估,如果预测效果不理想,可以考虑调整模型参数或者使用其他模型。
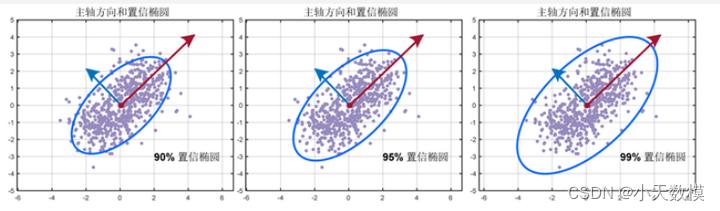
综上所述,通过对数据进行预处理、分析和建模,可以建立y1的预测模型,从而实现对predict.csv中数据的预测。
问题 2:对附件data.csv中的y2、y3和x1~x100进行数据分析,选择不超过10个特征指标,建立y1的预测模型,将predict.csv预测结果填入附件submit.csv文件中。
解决方案:
-
数据预处理:
(1) 数据清洗:对于缺失值,可以采用均值、中位数或众数进行填充;对于异常值,可以通过箱线图等方法进行识别和处理。
(2) 数据变换:对于偏态分布的数据,可以采用对数变换、指数变换等方法使其更加符合正态分布。
(3) 数据标准化:对于不同量纲的数据,可以采用标准化或归一化的方法将其转换为统一的量纲,以避免不同量纲对模型的影响。
-
数据分析:
(1) 特征选择:通过相关性分析、主成分分析等方法选择与y1相关性较强的特征指标,避免维度灾难和过拟合。
(2) 建立模型:根据选取的特征指标,可以采用线性回归、决策树、支持向量机等方法建立y1的预测模型。
(3) 模型评估:通过交叉验证等方法评估模型的性能,选择最优的模型。
-
预测结果:
将predict.csv中的数据输入到建立的最优模型中,得到预测结果,并将结果填入附件submit.csv文件中。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 读取数据
data = pd.read_csv('data.csv')
predict = pd.read_csv('predict.csv')
# 数据预处理
# 将数据集分为训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=0)
# 选择特征指标
features = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10']
# 构建训练集和测试集
X_train = train_data[features]
y_train = train_data['y1']
X_test = test_data[features]
y_test = test_data['y1']
# 构建线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
# 预测测试集
y_pred = lr.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
# 使用模型预测predict.csv中的数据
~~~~~~~问题 3:分析y3与y1y2, x1x100之间的函数关系,建立数学模型预测y3,研究y1y2, x1x100中,哪些特征指标对y3预测结果的影响较大?并对所选择的指标进行灵敏度分析,将predict.csv预测结果填入在附件submit.csv文件中。
为了预测y3,我们需要建立一个数学模型,通过分析y1y2, x1x100中的特征指标,来预测y3的数值。首先,我们可以将y1y2, x1x100中的特征指标进行筛选,选择那些与y3相关性较强的指标。这样可以有效地减少模型的复杂性,提高预测的准确性。
其次,我们可以使用多元线性回归模型来建立预测模型。多元线性回归模型可以通过拟合数据来建立一个线性关系,从而预测y3的数值。在建立模型时,我们需要注意选择合适的特征指标,避免过拟合的情况。
为了评估模型的预测能力,我们可以使用交叉验证的方法来验证模型的准确性。交叉验证可以将数据集分为训练集和测试集,通过测试集的结果来评估模型的预测能力。
在建立模型后,我们可以进行灵敏度分析,来确定哪些特征指标对y3的预测结果影响较大。灵敏度分析可以帮助我们进一步优化模型,提高预测的准确性。
最后,我们可以使用建立好的模型来预测predict.csv中的数据,并将预测结果填入submit.csv文件中。通过提交结果,可以评估模型的预测能力,并对模型进行进一步的优化。















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









