







目录
分析用户的购物习惯,预测消费者将购买哪些产品,探究用户对物品类别的喜好细分降维
分析用户的购物习惯,预测消费者将购买哪些产品,探究用户对物品类别的喜好细分降维
有下面四张表
- order_ products_ prior. csv:订单与商品信息
字段: order_ id, product_ id, add_ to cart_ order, reordered
- products . csv:商品信息
字段: product_ id, product_ name, aisle_ id, department_ id
- orders .csv:用户的订单信息
字段: order_ id, user_ id,eval_ set, order_ number, ...
- aisles. csv:商品所属具体物品类别
字段: aisle_ id, aisle
大致操作
1. 将这几张表合并,得到同时含有user_id和aisle这两个变量的表。这里用到了pandas.merge()函数,merge函数的详情可参看右方链接------->>http://t.csdn.cn/cA4YQ
2. 找到user_id和aisle之间的关系,这里用到了pandas.crosstab()函数
3.PCA降维,因为有很多冗余的数据,这时候可以进行降维处理。
具体操作
先导入要用到的pandas
import pandas as pd1.获取数据
order_products=pd.read_csv("D:\order_products__prior.csv") products=pd.read_csv("D:\products.csv") orders=pd.read_csv("D:\orders.csv") aisles=pd.read_csv("D:/aisles.csv")
2. 合并表,将user_id和aisle合并在一个表中
tab1=pd.merge(aisles,products,on=["aisle_id","aisle_id"]) tab2=pd.merge(tab1,order_products,on=["product_id","product_id"]) tab3=pd.merge(tab2,orders,on=["order_id","order_id"])结果为下表
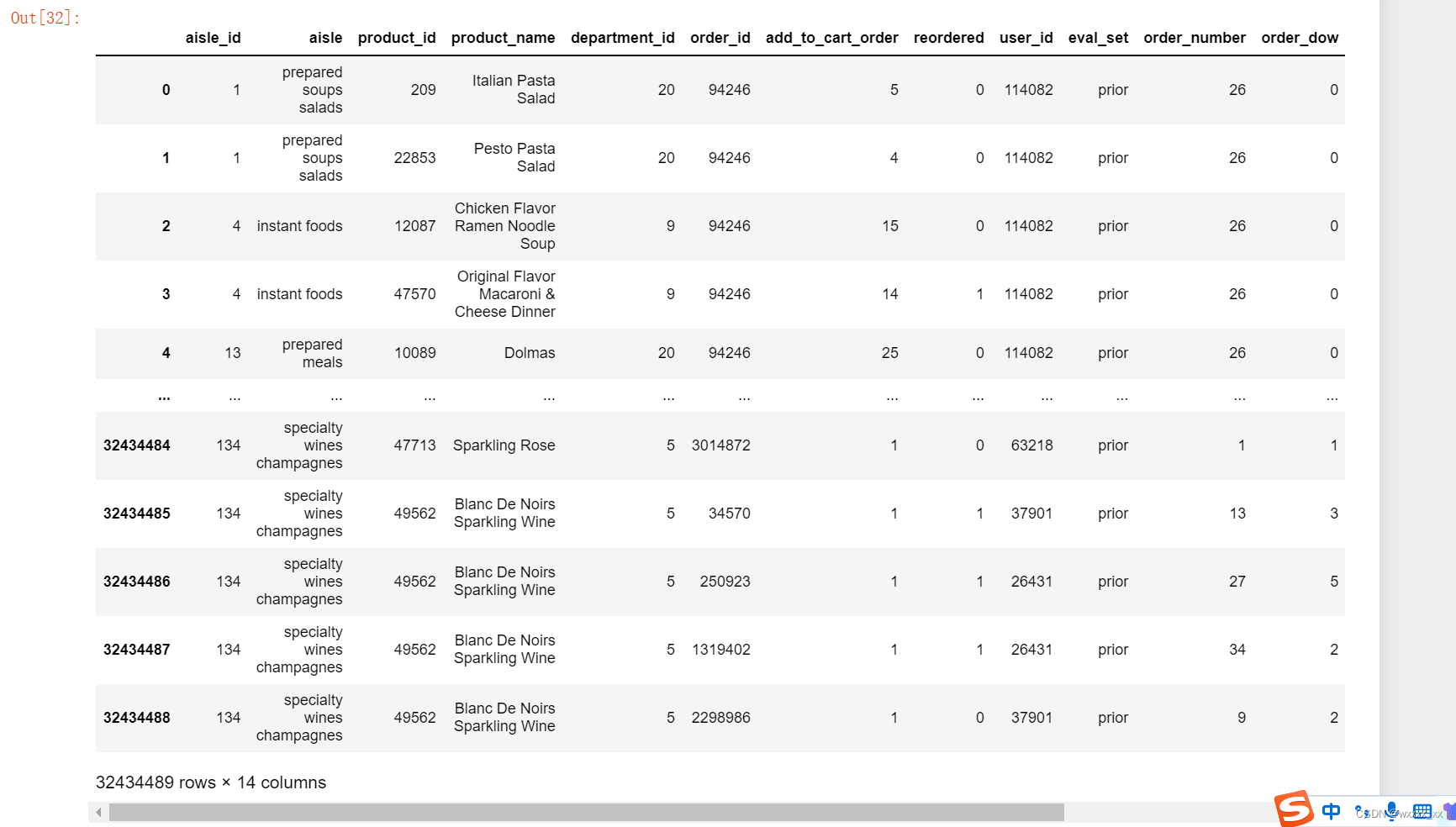
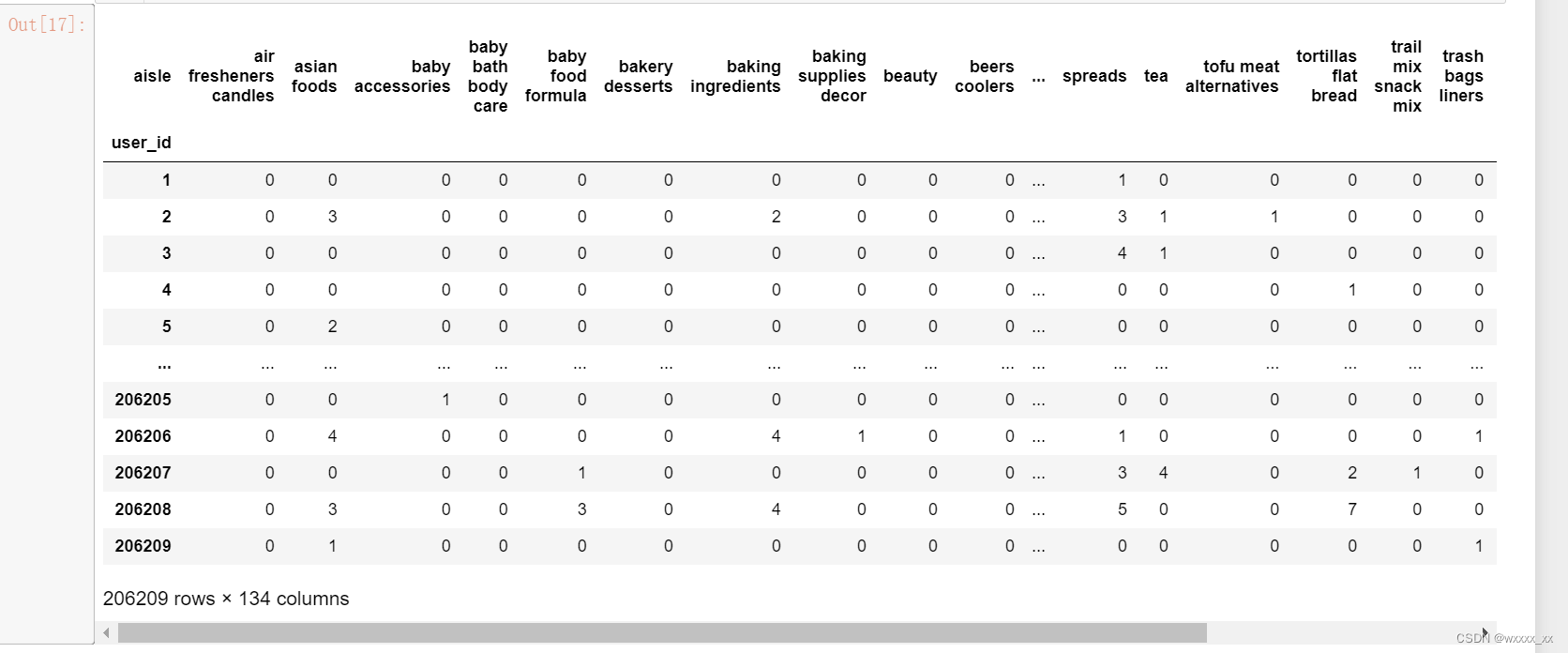
3.找到user_id和aisle之间的关系,合并为一张表,user_id做行索引,aisle做列索引
table=pd.crosstab(tab3["user_id"],tab3["aisle"])结果为下表
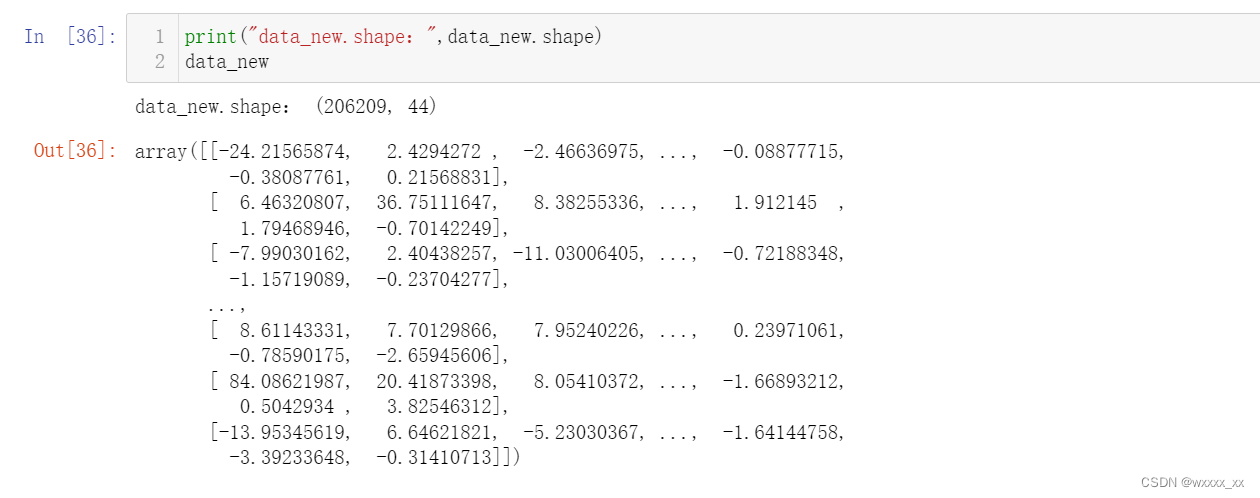
4.由上面的数据看出,存在很多的冗余数据,现在进行PCA降维处理
data=table[:] #4.PCA降维 from sklearn.decomposition import PCA #1.实例化转换器 transfer=PCA(n_components=0.95) #2.调用fit_transform data_new=transfer.fit_transform(data)最终可看到,经过PCA降维处理后,原来的数据shape为(206209,134),现在变成了(206209,44)
完整代码
import pandas as pd
#1.获取数据
order_products=pd.read_csv("D:\order_products__prior.csv")
products=pd.read_csv("D:\products.csv")
orders=pd.read_csv("D:\orders.csv")
aisles=pd.read_csv("D:/aisles.csv")
# 2、合并表
tab1=pd.merge(aisles,products,on=["aisle_id","aisle_id"])
tab2=pd.merge(tab1,order_products,on=["product_id","product_id"])
tab3=pd.merge(tab2,orders,on=["order_id","order_id"])
#3. 找到user_id和aisle之间的关系
table=pd.crosstab(tab3["user_id"],tab3["aisle"]
data=table[:]
#4.PCA降维
from sklearn.decomposition import PCA
#实例化转换器
transfer=PCA(n_components=0.95)
#调用fit_transform
data_new=transfer.fit_transform(data)
#5.输出处理完毕得到的最终数据
print("data_new.shape:",data_new.shape)
data_new运行期间出现的错误 invalid argument
当我运行下面这句代码的时候报了错误 invalid argument
aisles=pd.read_csv("D:\aisles.csv)解决方法:把\改为/就可以了















 1462
1462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











