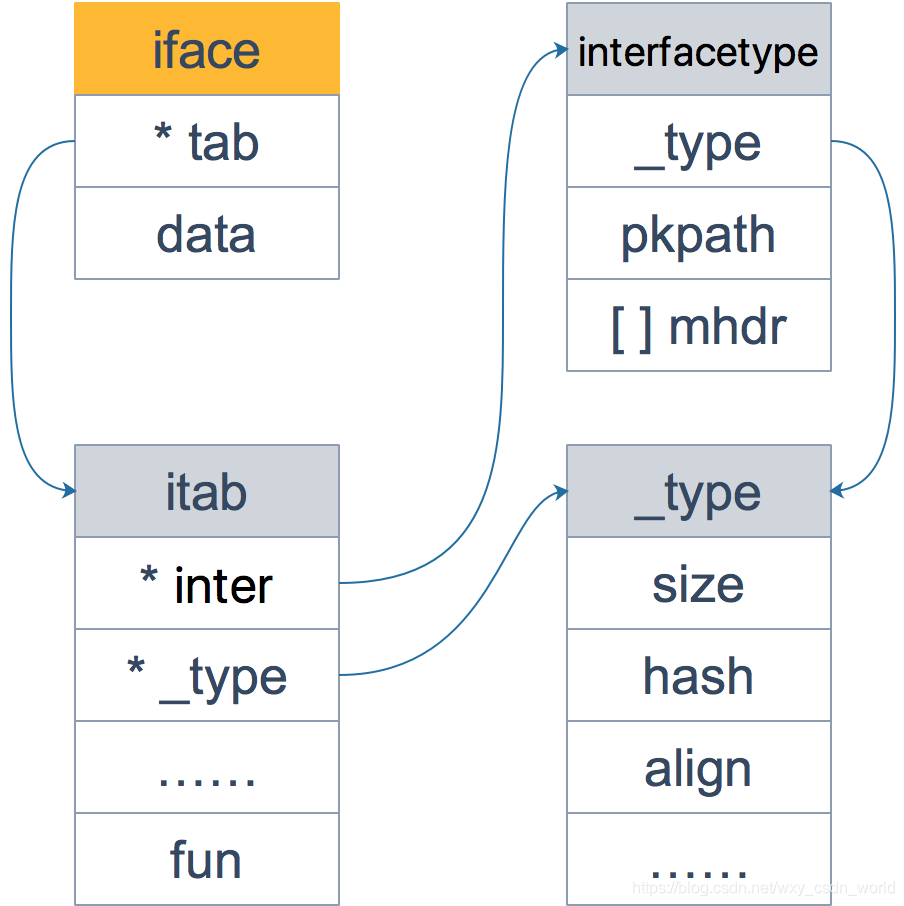
//以下源码在 runtime/runtime2.go 里type itab struct{
inter *interfacetype
_type *_type
hash uint32// copy of _type.hash. Used for type switches._[4]byte
fun [1]uintptr// variable sized. fun[0]==0 means _type does not implement inter.}
再来仔细看一下 itab 结构体:inter 字段则描述了接口的类型;_type 字段描述了实体的类型,包括内存对齐方式,大小等。fun 字段放置和接口方法对应的具体数据类型的方法地址,实现接口调用方法的动态分派,一般在每次给接口赋值发生转换时会更新此表,或者直接拿缓存的 itab。这里只会列出实体类型和接口相关的方法,实体类型的其他方法并不会出现在这里。另外,你可能会觉得奇怪,为什么 fun 数组的大小为 1,要是接口定义了多个方法可怎么办?实际上,这里存储的是第一个方法的函数指针,如果有更多的方法,在它之后的内存空间里继续存储。从汇编角度来看,通过增加地址就能获取到这些函数指针,没什么影响。顺便提一句,这些方法是按照函数名称的字典序进行排列的。
再看一下 interfacetype 类型,它描述的是接口的类型:
//以下源码在 runtime/type.go 里type interfacetype struct{
typ _type
pkgpath name
mhdr []imethod
}
可以看到,它包装了 _type 类型,_type 实际上是描述 Go 语言中各种数据类型的结构体。我们注意到,这里还包含一个 mhdr 字段,表示接口所定义的函数列表, pkgpath 记录定义了接口的包名。
最后看一下 _type 类型,它描述的是实体的类型:
//以下源码在 runtime/type.go 里type _type struct{
size uintptr
ptrdata uintptr// size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8// function for comparing objects of this type// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer)bool// gcdata stores the GC type data for the garbage collector.// If the KindGCProg bit is set in kind, gcdata is a GC program.// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
Go 语言各种数据类型都是在 _type 字段的基础上,增加一些额外的字段来进行管理的:
type maptype struct{
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer,uintptr)uintptr
keysize uint8// size of key slot
elemsize uint8// size of elem slot
bucketsize uint16// size of bucket
flags uint32}type arraytype struct{
typ _type
elem *_type
slice *_type
lenuintptr}type chantype struct{
typ _type
elem *_type
dir uintptr}type slicetype struct{
typ _type
elem *_type
}type functype struct{
typ _type
inCount uint16
outCount uint16}type ptrtype struct{
typ _type
elem *_type
}
package main
import"fmt"type coder interface{code()debug()}type Gopher struct{
language string}func(g Gopher)code(){
fmt.Printf("I am coding %s language.\n", g.language)}func(g *Gopher)debug(){
g.language ="golang"
fmt.Printf("I am debugging %s language.\n", g.language)}funcmain(){var c coder
fmt.Printf("before 'c=g', interface: coder %T, %v\n", c, c)
fmt.Println("before 'c=g', c == nil:", c ==nil)var g *Gopher
c = g
fmt.Println("g == nil:", g ==nil)
fmt.Printf("after 'c=g', interface: coder %T, %v\n", c, c)
fmt.Println("after 'c=g', c == nil:", c ==nil)}
输出:
before 'c=g', interface: coder <nil>, <nil>
before 'c=g', c == nil: true
g == nil: true
after 'c=g', interface: coder *Gopher, <nil>
after 'c=g', c == nil: false
解释:一开始,c 的 动态类型和动态值都为 nil,g 也为 nil,当把 g 赋值给 c 后,c 的动态类型变成了 *main.Gopher,仅管 c 的动态值仍为 nil,但是当 c 和 nil 作比较的时候,结果就是 false 了。
package main
import("unsafe""fmt")type iface struct{
itab, data uintptr}funcmain(){var a interface{}=nilvar b interface{}=(*int)(nil)
x :=5var c interface{}=(*int)(&x)
ia :=*(*iface)(unsafe.Pointer(&a))
ib :=*(*iface)(unsafe.Pointer(&b))
ic :=*(*iface)(unsafe.Pointer(&c))
fmt.Println(ia, ib, ic)
fmt.Println(*(*int)(unsafe.Pointer(ic.data)))}
输出:
{0 0} {4881696 0} {4881696 824634236592}
5
解释:代码里直接定义了一个 iface 结构体,用两个指针来描述 itab 和 data,之后将 a, b, c 在内存中的内容强制解释成我们自定义的 iface。最后就可以打印出动态类型和动态值的地址。a 的动态类型和动态值均为 0,也就是 nil;b 的动态类型和 c 的动态类型一致,都是 *int;最后,c 的动态值为 5。
打印接口的hash值
来看例子:
package main
import("fmt""unsafe")type Monster interface{Beat()}type Gesila struct{
weight string}func(g Gesila)Beat(){
fmt.Println("哥斯拉发出原子吐息!")}type itab struct{
inter uintptr
_type uintptr
hash uint32_[4]byte
fun [1]uintptr}type iface struct{
tab *Itab
data uintptr}funcmain(){var m Monster =Monster(Gesila{weight:"12万吨"})
r :=*(*iface)(unsafe.Pointer(&m))
fmt.Println(r.tab.hash)}























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











