







目录
What is MergeFunctions Pass
源码项目中有时会出现多个相同的函数或者功能相同但写法不同的函数,例如:乘2操作和shl 2操作。产生这种情况的原因有许多,其中比较常见的是template和code generator的使用。在编译过程中如果能识别并合并这些相同的函数,就能够减少编译生成的二进制规模并提高代码执行效率。
在LLVM中,MergeFunctions pass实现的就是上述识别相同函数并合并的优化。本文将会着重于MergeFunctions中函数比较的部分,而函数合并部分只会简单涉及。
概述
MergeFunctions pass定义在 lib/Transforms/IPO/MergeFunctions.cpp 文件中,继承了ModulePass,可以在module内做跨函数的分析和转换。与所有的ModulePass一样,通过runOnModule成员方法可以执行该优化。MergeFunctions优化的整体逻辑如下图所示,是一个循环迭代的过程。

FnTree和Deferred
首先看一下MergeFunctions类中两个关键的成员变量:FnTree和Deferred。


上图是FnTree的定义。FnTree存储了分析module中所有独立的、不能进一步合并的函数,可以认为FnTree中存储的就是经过优化后的module中的所有函数。可以看到,FnTree其实是一个C++ STL set,其中存储的元素类型是FunctionNode,FunctionNodeCmp则是对FunctionNode的比较算子。

上图是Deferred的定义。Deferred中存储了所有需要进行比较和分析的函数。在MergeFunctions的优化过程中,找到两个相同的函数并进行合并之后,有可能会影响到之前已经分析过的、放到了FnTree中的函数(所有调用了当前被合并函数的函数),此时需要将这些函数移出FnTree,重新放到Deferred中等待再次分析。
基本流程
就像上面最开始的流程图所示:
- 开始时初始化FnTree为空,初始化Deferred为当前module中需要分析的函数。
- 对于Deferred中每一个需要分析的函数F,尝试在FnTree中寻找与它相同的函数G:
- 如果G不存在,表示当前F是独立的,于是将F添加到FnTree中;
- 如果G存在,则将F和G合并,修改代码中对它们的调用语句并将FnTree中所有调用了F和G的函数移出到Deferred中。
- 整个优化流程循环进行,直至Deferred中不再存在需要进一步分析的函数。此时,FnTree中存储的就是分析模块中所有独立的函数。
相同函数搜索
为了实现MergeFunctions的功能,首先需要识别出哪些函数有相同的功能,这样才能将它们进行合并。MergeFunctions优化中同时使用了两种函数比较的方法:函数哈希值比较和函数结构比较。这一张首先介绍一下函数的哈希比较。
函数哈希值比较
函数哈希值的计算
上文提到FnTree中存储的对象是FunctionNode。FunctionNode是MergeFunctions优化过程中定义的对LLVM Function的封装类,定义如下图所示。可以看到除了封装的函数本身外,FunctionNode中还存储了函数的哈希值Hash。

从FunctionNode的构造函数中可以看到函数哈希计算使用的是FunctionComparator::functionHash方法。FunctionComparator类定义在 lib/Transforms/Utils/FunctionComparator.cpp 文件中,除了提供函数哈希的计算外,它还实现了针对不同函数结构的比较算法。
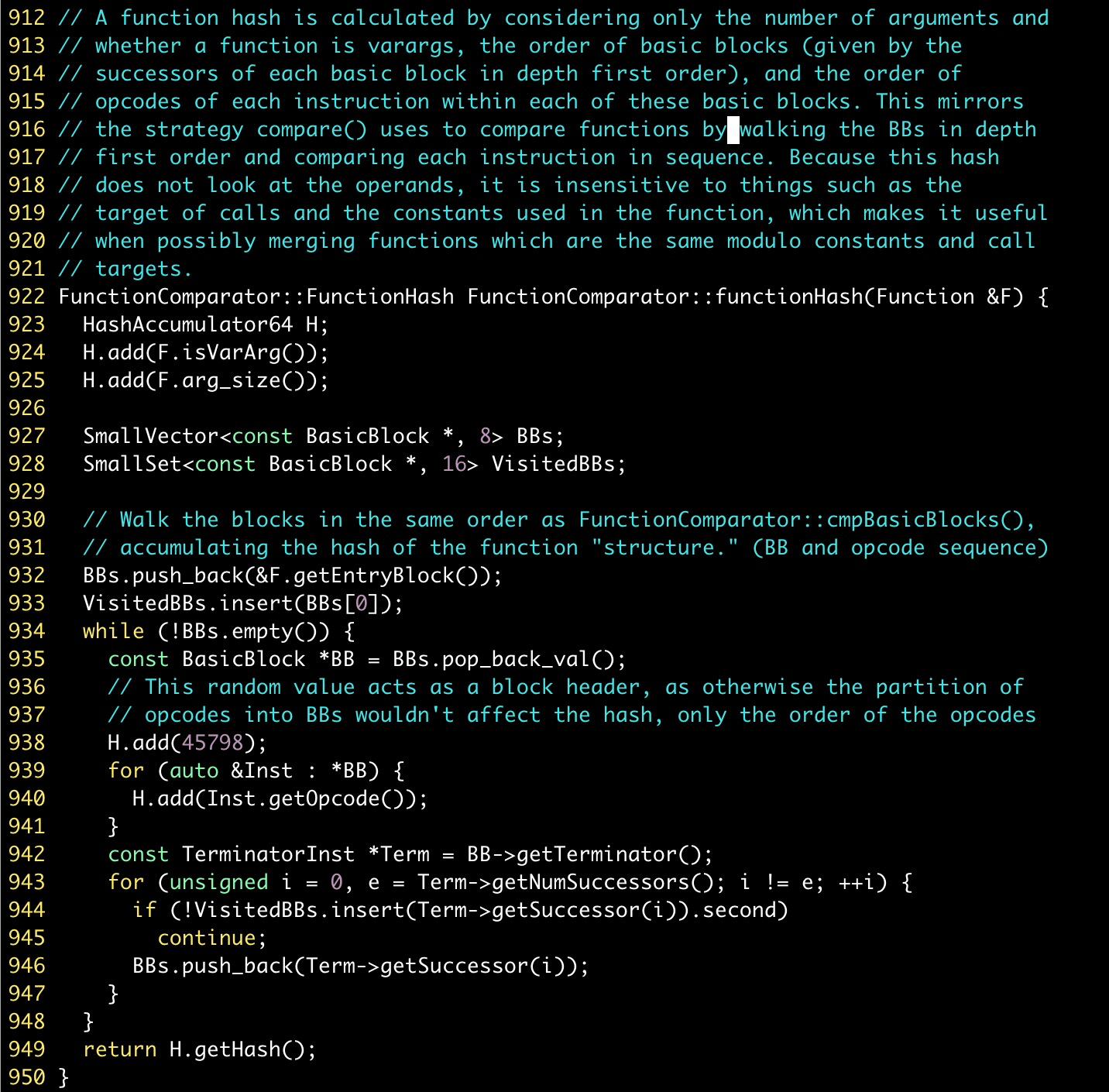
计算函数哈希的函数functionHash定义如上图所示。在计算时,首先考虑了函数是否有可变参数和函数的参数个数两个因素。之后以深度优先的方式遍历函数的AST,依次将遍历到的基本块中语句的操作符添加到函数的哈希计算中。最终综合上述这些因素,计算得到函数的哈希值。
MergeFunctions优化中使用的函数哈希计算方式只考量了函数的部分特性,并不能完全代表完整的函数。所以,即使两个函数的哈希相同也不能表示它们是相同的,依然需要进一步的比较;反之,如果两个函数的哈希不同则可以直接认为它们是不同的。这里之所以使用这样的设计主要有两个原因:
- 设计一个能够完整表示函数所有特征的哈希算法过于复杂。
- 虽然使用能够完整表示函数所有特征的哈希算法能够省去后续的基于函数结构的比较,但是这样的哈希计算实际开销过大,实验测试表明直接使用完整哈希算法的效率比当前简单哈希+函数结构比较设计的效率要低。
函数哈希值比较的使用
由于函数哈希值相同是函数相同的必要不充分条件,所以在MergeFunctions优化中被作为一种过滤方式使用:通过函数哈希值过滤掉大部分的函数对,只保留少数的函数对进行开销较大的函数结构比较。
函数哈希值比较在两个地方有使用:Deferred初始化部分和FunctionNodeCmp算子的比较开始阶段。这里介绍一下Deferred初始化部分,FunctionNodeCmp部分在后面会介绍到。
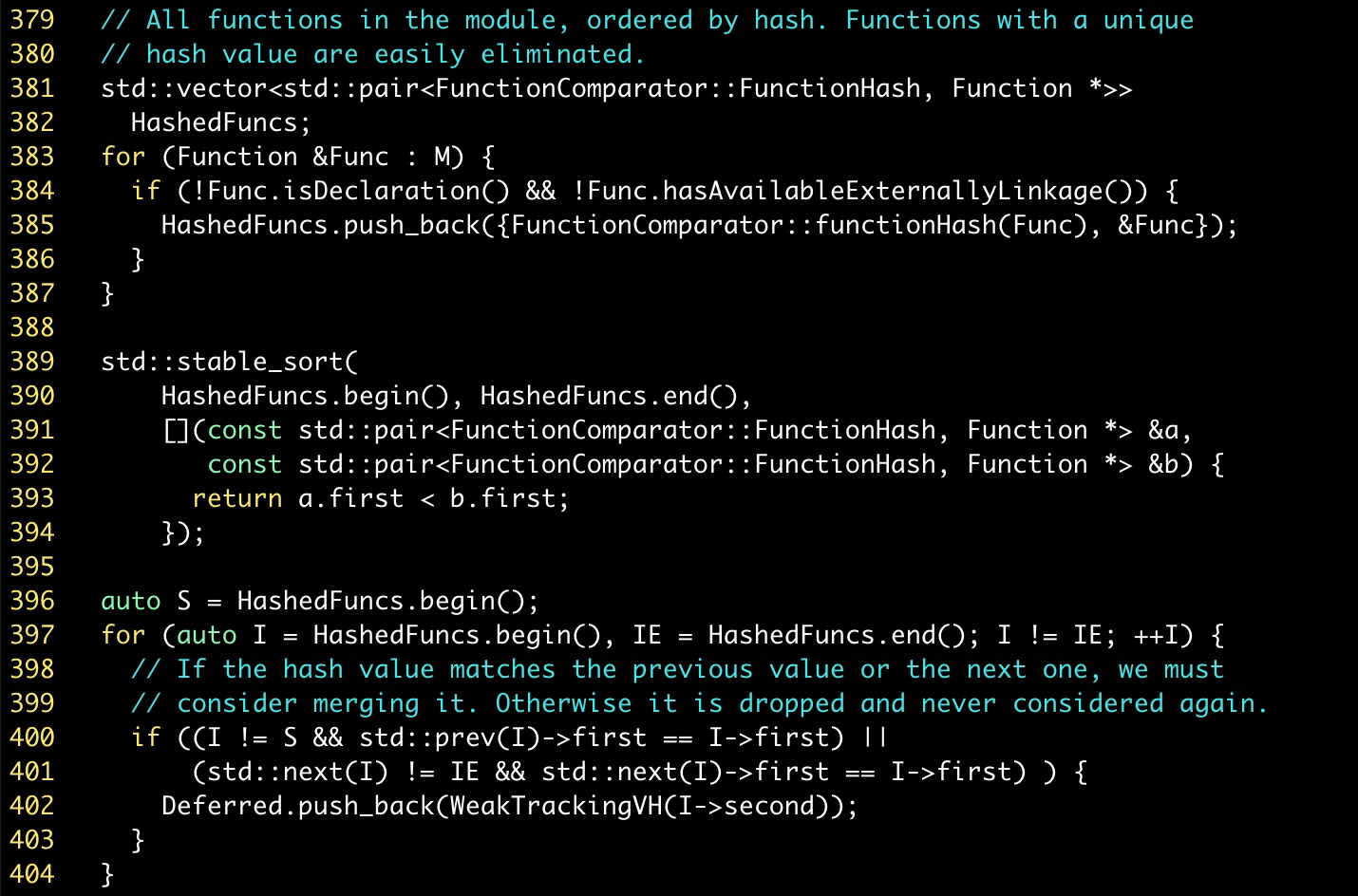
Deferred初始化的代码如下所示。在MergeFunctions优化开始时,需要收集可能可以进行合并的函数到Deferred中。对于分析module中的所有函数计算函数哈希值,只把有相同哈希值的函数初始化到Deferred中,因为哈希值唯一的函数一定是与其他所有的函数都不相同的,不需要进行后续的比较。这样就可以大大节省分析优化的时间。
函数结构比较
对于函数哈希值相同的函数,MergeFunctions会通过函数结构的比较来判定函数是否相同。在进行函数结构比较时秉承的一个思想是:将当前分析的程序模块转换为一些更小的模块,通过比较小模块来决定当前的大模块是否相同。例如:将函数的比较转换为基本块之间的比较;将基本块的比较转换为基本块内指令的比较等。同时,与其他的优化一样,MergeFunctions应该是conservative的,也就是宁可放过一千,不能错杀一个。
为了实现函数的比较,LLVM中针对不同的程序结构定义了不同的全序关系。这些按照全序关系比较函数结构的方法实现在FunctionComparator中。而MergeFunctions pass则是通过FnTree中定义的FunctionNodeCmp算子对集合内的函数进行比较和查找。
FunctionNodeCmp
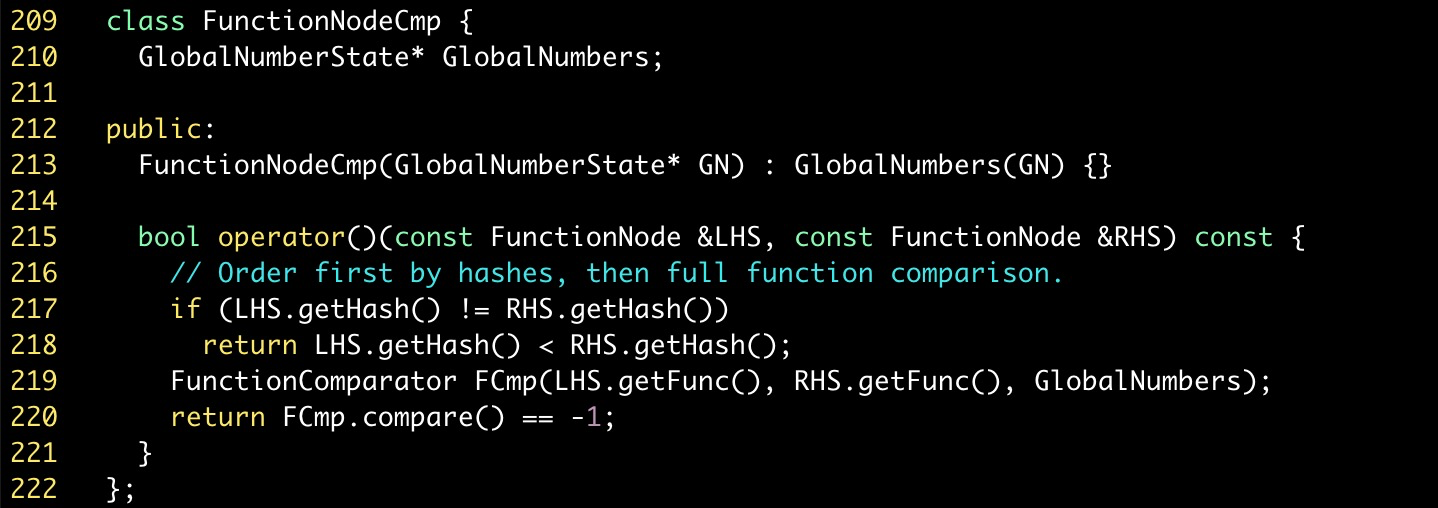
FunctionNodeCmp定义在MergeFunctions类内,如下图所示。在比较两个FunctionNode是否相同时,首先会判断它们的函数哈希值是否相同:如果不同则直接返回。这里就是上文所说的函数哈希值比较的另一处使用,可以快速过滤不同的函数,提高优化的速度。对于函数哈希相同的函数对,构造FunctionComparator并通过FunctionComparator::compare方法进行比较,判定是否相同。
函数比较方法
FunctionComparator中设计实现了对于多种不同程序结构的比较算法,通过compare方法可以直接比较函数是否相同。FunctionComparator::compare方法定义在lib/Transforms/Utils/FunctionComparator.cpp文件中。判断两个函数是否相同分为两步:判断函数签名是否相同以及判断函数体是否相同。如果函数签名不同,就不需要进行后续函数体内容的比较;只要在函数签名相同的情况下才去比较函数体的内容。
函数签名比较
函数签名比较的实现在FunctionComparator::compareSignature方法中。虽然这部分的名字叫做函数签名比较,但是比较的内容远不止函数签名,包含了所有除了函数体外会影响函数是否相同判断的因素。只有满足如下的所有条件,才认为两个函数的函数签名是相同的。
- attributes:两个函数的函数attributes列表相同。
- GC:两个函数都没有GC,或者两个函数有相同的GC。
- Section:两个函数都不在section内,或者两个函数在相同的section内。
- Various Args:两个函数都有可变参数或者都没有可变参数。
- Calling Convention:两个函数的calling convention相同。
- Function Type:两个函数的函数类型相同。
- Arg number:两个函数的参数个数相同。
函数体内容比较
对于函数签名相同的函数,需要进一步比较它们的函数体是否相同。函数体比较是基于AST树结构和基本块内的指令的比较。中心思想是:对于两个函数F和G,按照相同的遍历方法遍历AST,分别得到两个基本块链ChainF和ChainG。那么,如果两个函数相同,则基本块链上相同位置的基本块内的指令必然是相同的。
需要注意的是,这样的比较逻辑决定了MergeFunctions pass是依赖AST结构的,因此难以处理函数功能相同但是控制流发生改变的情况。
下图就是compare方法中对函数体的比较部分。可以看到,MergeFunctions以深度优先的方式同时遍历两个函数的AST去获得在相同位置的两个基本块;之后通过cmpBasicBlocks方法比较基本块是否相同。最终函数是否相同的结果取决于AST的结构是否相同和基本块内容比较的结果。

基本块与指令比较
基本块比较的实现在cmpBasicBlocks方法中。比较过程中,遍历两个基本块内对应位置的指令并进行比较。指令的比较可以分为两步:首先比较指令的操作符是否相同,之后依次比较指令对应位置的操作数是否相同。指令操作符的比较方法在FunctionComparator::cmpOperations方法中。在比较操作符的时候,考虑了如下的这些因素:
- 两条指令的操作符在LLVM中对应的Opcode是否相同。
- 两条指令的操作数个数是否相同。
- 两条指令的类型是否相同。
- 两条指令的optional flags是否相同。
- 两条指令所有对应位置上的操作数的类型是否相同。
- 特殊指令的处理:对于GetElementPtrInst,则使用cmpGEP方法进行比较。
- 对于特殊的指令的特殊的检查。例如:对于内存分配指令,会比较分配内容的类型是否相同以及分配内存的alignment是否相同。
至此,MergeFunctions pass中函数比较的主要逻辑基本都已经完成。就像上文所说:在比较的过程中通过层层分解(将函数分解为函数签名和函数体-->将函数体分解为基本块位置和基本块内容-->将基本块分解为指令),将复杂的函数比较问题分解为了一些更小的单元的比较,而这些小单元的比较只需要特定的一些“元比较”操作就能完成,例如:cmpValues、cmpTypes、cmpNumbers等等。这些“元比较”操作都定义在FunctionComparator类中,每一个都实现了LLVM为特定代码结构定义的全序关系和比较,都可以在FunctionComparator.cpp中找到实现。在这里就不再做过多的介绍。
相同函数合并
对于两个相同的函数,需要对它们进行合并。函数合并的主要逻辑在MergeFunctions::mergeTwoFunctions方法中。本文重点在前面的函数比较部分,这部分只做简单的介绍。
假设对于当前分析的函数G,在FnTree中找到了相同的函数F,MergeFunctions在合并函数的时候会保留已有的函数F而删除函数G。相应的,需要修改所有对函数G的调用为新的函数调用。最后,对于FnTree中存在的调用了G的函数,将它们移出FnTree并重新添加到Deferred中等待下一轮的比较。

上图是mergeTwoFunctions方法的实现代码,可以看到,LLVM在实现函数调用替换的过程中,对于不同linkage的函数做了不同的处理。
LLVM中定义interposable如下:
global's definition can be substituted with an arbitrary definition at link time.
对于interposable的函数,在替换的过程中将会构建新的函数H。构建的函数H将会完全复制函数F,并且将所有函数F的调用全部替换为函数H的调用。之后使用writeThunk方法将所有对函数F和函数G的调用替换为对bitcast(H)函数的尾调用。对于非interposable的函数,MergeFunctions pass的替换过程就比较简单:使用writeThunk将所有对函数G的调用替换为对bitcast(F)的调用。
参考资料:MergeFunctions pass, how it works — LLVM 6 documentation
文中涉及的代码版本:LLVM-6.0.0















 3161
3161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









