






一、图的基本概念
关联至:边关联至顶点
邻接至:顶点之间邻接
图G是强连通图:有向图中任意两个顶点vi和vj,如果从vi到vj和从vj到vi都有路径
二、图的存储
1.顺序存储:
邻接矩阵(顶点之间)
当(i,j)属于E时:A(i,j)=1(或权重)
特性:
对无向图:A(i,i)=0;邻接矩阵对称;行、列之和均等于顶点的度
对有向图:行之和=出度;列之和=入度
优化:
常规用a[n][n],利用d*n^2字节(sizeof(type)=d)
1.不储存对角线:节省d*n字节
2.若元素只取值01,用二进制位保存:n(n-1)/8字节
*8位(bit)=1字节(byte)
3.无向图是对称矩阵,只保存上(下)三角:n(n-1)/16字节
时间复杂度:
• 求给定节点的邻接节点集合,O (n)• 求图中总的边数,O (n^ 2 )• 增加、删除一条边,O (1)
邻接压缩表
时间复杂度:• e 远远小于 n 2 à 空间复杂性远优于邻接矩阵• 顶点 i 的度 h[i+1]-h[i] , Q (1)• 边总数无向图: h[n+1]/2 ,有向图: h[n+1] , Q (1)• 增加、删除一条边, O(n+e)
关联矩阵(边与顶点之间)
用mij表示顶点vi与边ej关联的次数(可能取值0,1,-1)
2.链表存储:
邻接链表:
邻接表(邻接顶点集合)用链表保存
Chain<int>类型的数组h
h[i]——顶点i的邻接表,只记录存在的边
空间复杂度:
• 有向图 = O (n + e)• 无向图 = O (n + 2* e) = O (n + e)• 适用于稀疏图• 平面图 = O (n + 3* n) = O (n)
较之邻接矩阵,有极大改进
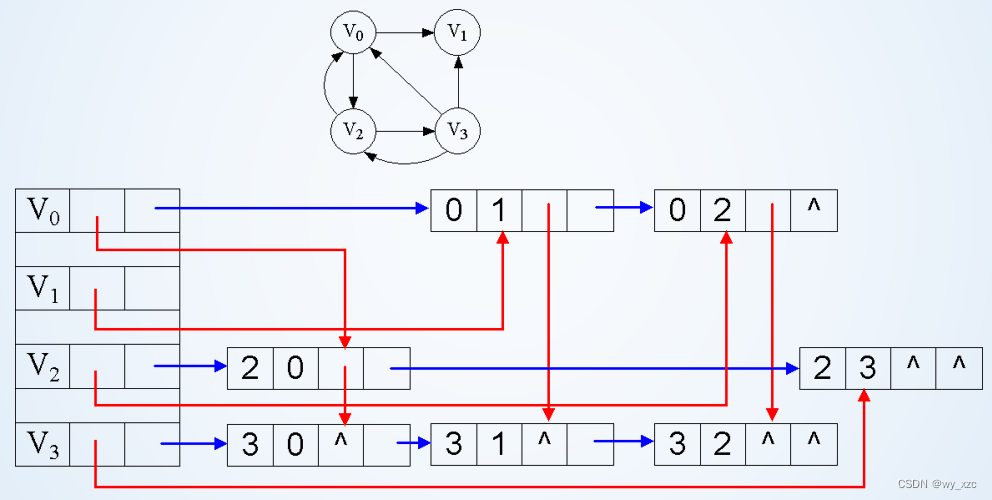
十字链表:
三、图的遍历
宽度优先搜索(BFS):
访问顶点s -> 依次访问s所有尚未访问的邻接顶点 ->依次访问它们尚未访问的邻接顶点
伪代码:
/从顶点v 开始的宽度优先搜索
把顶点v标记为已到达顶点;
初始化队列Q,其中仅包含一个元素v;
while (Q不空)
{
从队列中删除顶点w;
令u 为邻接于w 的顶点;
while (u)
{
if ( u 尚未被标记)
{
把u 加入队列;
把u 标记为已到达顶点;
}
u = 邻接于w 的下一个顶点;
}
}
找连通分量与可达分量:
算法:从s出发做BFS,输出所有“被发现”顶点,队列为空后终止
若图中包含多个连通/可达分量,又该如何保证对全图的遍历呢?
经过BFS,会将边分为两类(无向图)
树边:联边之前:v DISCOVERED && u UNDISCOVERED
联边之后:v == parent(u)跨边:无向图:只可能v和u均为DISCOVERED
有向图:还可能v是DISCOVERED、u是VISITED
BFS树/森林
1.对于每一连通/可达分量,bfs()进入BFS(v)恰好1次(v为该分量的起始顶点)
2.进入BFS(v)时,队列为空,v所属分量内的每个顶点,迟早会以UNDISCOVERED状态进队1次
进队后随即转为DISCOVERED状态,并生成一条树边;迟早会出队并转为VISITED状态;退出BFS(v)时,队列为空
3.BFS(v)以v为根,生成一棵BFS树,bfs()生成一个BFS森林,包含c棵树、n - c条树边和e - n + c条跨边
深度优先搜索(DFS):
v为开始顶点,首先标记v;选择一个与v邻接,且尚未标记的顶点u;像处理v一样对u进行处理——DFS递归调用;对u的处理完毕后,选择另一个与v相邻且未标记的顶点,继续搜索;若不存在,搜索中止
四、最小生成树
各边总权重最小的树
割:删除后变得不连通
Prim算法:
选择生成树的n-1条边
贪心准则:1.加入后仍形成树,且耗费最小 2.始终保持树的结构(Kruskal算法是森林)
算法过程:
• 从单一顶点的树 T 开始• 不断加入耗费最小的边 (u, v) ,使 T ∪ {(u, v)} 仍为树 ——u 、 v 中必然有一个已经在 T 中,另一个不在 T 中
最小耗费生成树(Kruskal算法):
Kruskal:
• 每个步骤选择一条边加入生成树• 贪心准则:不会产生环路,且耗费最小• 可按耗费递增顺序考察每条边• 若产生环路,丢弃• 否则,加入















 2069
2069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









