






一 毕设主要做的工作
本文提出了一个基于人体关节夹角的人体动作识别算法,主要做了以下工作:①提出了一个可解释性强,耗费算力较少且鲁棒性较高的基于人体关节夹角的人体动作序列的特征抽取方法 ②本文所使用的分类模型是一个融合了SVM,KNN等多个分类模型的集成学习模型,并且使用了一个结合了Boosting和Bagging的集成学习策略。 最终本论文提出的方法在G3D数据集上的分类准确率为92.3%。该结果验证论文中方法的可行性。 论文可分为以下几个部分:
(1)特征抽取部分:在每一个人体动作序列中等间距取50张图。对于每一张图片使用Openpose结合数据集的深度图获取人体关键点3D坐标和肢体识别结果,可以得到24 个肢体向量。然后通过计算每一张图片中的24 个肢体向量两两之间的夹角的余弦值,可以得到50个长度为276的人体姿态特征向量表示,把他们拼接起来后用基于方差的Filter方法和基于随机森林的RFE方法来进行特征选择,最后得到人体动作序列的特征向量表示。
(2)模型集成部分:因为logistic回归拟合能力较弱,所以先让它进行Adaboost增强拟合能力,而后再把它和SVM,KNN,随机森
林一起进行基于软投票策略的Bagging方法后输出最终的分类结果
(3)模型训练部分:按照训练集和测试集5:5的比例划分数据集,而后按照划分的数据集使用网格调参法调出每一个基分类模型的最佳参数,而后将其带入集成学习模型当中进行最终的模型分类预测。具体的流程如下图所示:
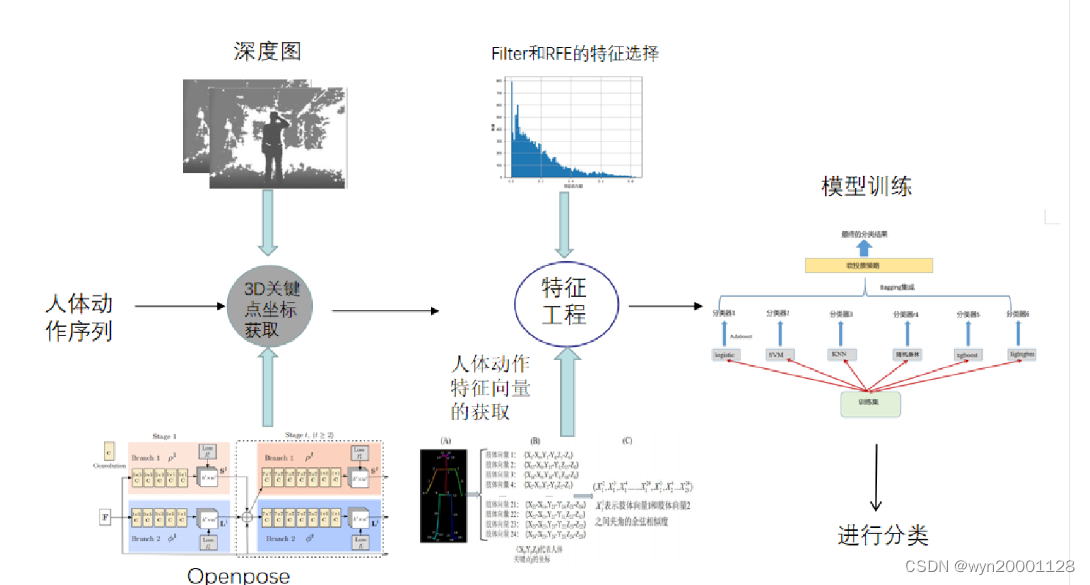
如果需要毕设代码github代码的话访问这里:优秀毕设
二 具体的技术
①Openpose
Openpose 的核心技术就是采用 PAF 进行自下而上的人体姿态估计,可以巧妙地解决多人肢干连接问题。该技术借鉴 CPM的方法,CPM 先对输入进行处理,最后得到的检测结果是一幅预测人体关键点的 heatmap。这样每一个关键点在 heatmap 上面都服从一个高斯分布,而后高斯分布的极大值点的位置就是对应的关键点的位置。
Openpose 的改进就在于它引入了 PAF 的概念。PAF 就是人体动作的亲和力场,通俗地说就是 PAF 代表了两个关节点属于同一个肢体的可能性,PAF 越大两个关键点之间属于同一个肢体的可能性越高。F 是输入的图片通过 VGG-19 网络前 10 层经过预处理之后的结果。而后 F 作为输入兵分两路进入两个卷积神经网络进行学习,分别用以对人体的关键点和PAF 进行回归预测。Openpose 的总网络结构图如下图所示:
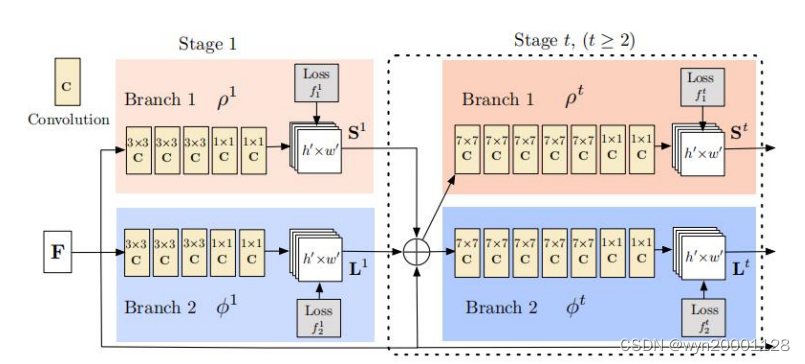
F 经过这两个网络结构之后可以得到两个处理结果:一个是人体关键点的 heatmap,一个是 PAF 的 heatmap。而后把任意两个关节点(由 CPM 的网络结构预测出来的)之间的PAF 进行线积分,就可以得到这两个关节点之间的 PAF。通过以上方法求出来的人体关键点以及对应的 PAF 可以按照图论的角度进行建模,这样接下来就把人体关键点的识别问题转化成了多个二分匹配的问题(如下图所示),然后我们可以使用图论的二分匹配算法例如匈牙利算法[47]得到最终结果。
②特征选择部分
(1)基于方差的Filter 方法
这种方法依靠数据的一些具有统计学意义的量来评估特征的重要性。基于 Filter 分方法一般包含两个步骤:第一步是根据这些具有统计学意义的特征评价标准对特征的重要性进行排序。第二步就是低排名特征被过滤掉。
在论文当中我采用了方差作为选定的具有统计学意义的量。方差反应的就是特征数据的变化情况,如果一个特征的方差特别小,那意味着这个特征的数据变化情况特别小。则在分类问题之中这个特征不会因为类别的变化而发生变化,也就是说这个特征不会为分类问题提供有价值的信息。我在论文当中先用pandas计算了13800个特征的方差值,如下所示:
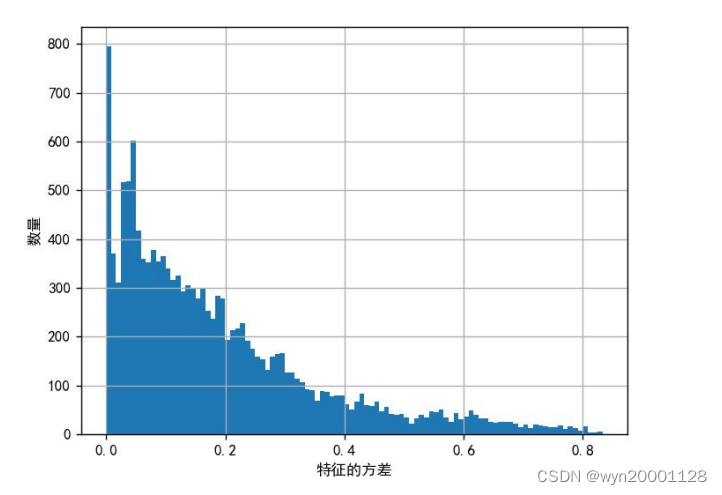
由上图可见方差在 0 到 0.2 的特征非常多。可见许多的特征没有什么变化,它们不会给分类任务提供非常多的有用的信息。所以我们有必要使用基于方差的 Filter 方法来先对特征进行第一轮选择。根据研究者们的做法方差低于 0.16 的特征都应该被剔除掉。所以我们把 0.16 作为参数进行 Filter 特征选择。消除了以后才用的RFE
(2)递归特征消除法(RFE)
这个方法所使用的是一种贪心策略的方法。具体的步骤如下:
①先把原始的特征集 D 作为输入输进去机器学习算法,然后根据机器学习算法的效果对原有的特征根据某些属性(例如 feature_importances)进行排序。在论文当中我们选择了随机森林作为 RFE 的给定的机器学习方法
②剔除掉一些重要性比较低的特征,保留一些重要特征构成新的特征集 D1。
③D1 作为输入再次输入机器学习算法当中,进行和①②一样的操作,而后往复循环地进重复①②的操作,直到所选的特征数量达到要求缩减的数量为止。
③用到的模型
①logistic 回归
线性回归是一种非常经典的回归任务的机器学习方法。线性回归就是根据已知的数据集里面的特征,训练出一个线性的回归方程。但是线性回归的输出结果是一个连续的结果,而分类问题需要的是一个可以输出离散的分类结果的分类器。所以线性回归不可以直接运用于分类作用。但是分类问题可以理解为是选择概率最大的类别作为分类器,而概率是一个 0 到 1 之间的连续值。所以通过某种映射使得线性回归的结果出现在 0-1 之间,那么就有可能把线性回归运用到分类问题中来
以二分类为例,分类器把某个样本点归类为“1”的根据就是分类器预测该样本点是“1”的概率至少大于 0.5。显然 sigmoid 函数就适合二分类的条件,这就使得这个函数十分适合用于分类问题的映射。所以研究者们就设计出了 logistic 二元分类器,具体的分类器函数如下公式所示:
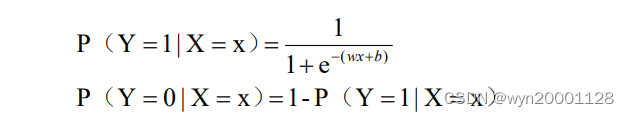
为了找到最合适的 W 和 b,我们采用的是极大似然估计法。极大似然估计法的核心思想就是找到适合的参数,让参与极大似然估计的样本出现的可能性最大。将其应用在二元分类的应用情况下就是:找到特定的 W 和 b,使得所有样本都被 logistic 二元分类器正确分类的概率最大。所以研究者们设计 logistic 二元分类器的损失函数如下: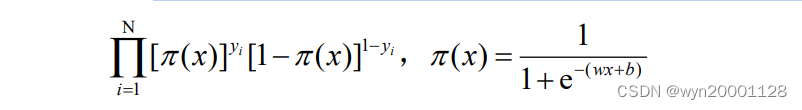
②SVM
支持向量机(SVM)属于监督学习,并且是机器学习里面最为经典并且数学推导最为优美的分类模型之一。支持向量机的核心理念就是训练出一个超平面,这个超平面是两个类别之间的最大间隔平面。这就把一个机器学习的参数估计问题转化成了一个最优化理论的凸优化问题,相比起 logistic 回归,支持向量机的推导过程中表现出了更加严谨的数学性以及更加良好的可解释性从数据的分布的角度来看,一个二分类问题的本质就是寻找一个可以把训练集中的属于不同类别的数据分割开来的超平面。但是有许多的超平面都可以做到这一点(如下所示)。所以可以肯定在这些超平面当中一定存在着某个超平面使得两边的分类的效果达到最好。SVM 就是旨在找到这个向量。
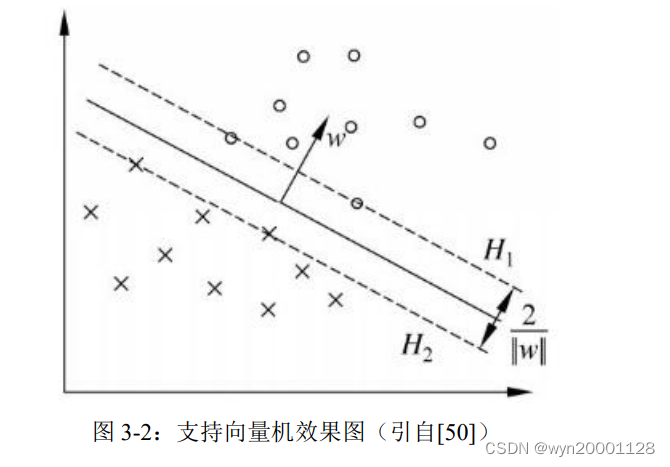
上述是 SVM 进行二分类模型的效果。其实 SVM 也可以拓展到多分类模型的应用场合之下来的,具体的步骤可以分为 3 步:
①从训练数据集当中挑出某一类 A,将剩下的数据统一归为一类 B
②利用二元 SVM 的训练方法训练吃 A 和 B 之间的最大间隔超平面。
③重复步骤①②,直到训练出所有用于分类的超平面为止。
③KNN
算法的思想是非常简单的:就是给定一个训练数据集,对于一个将要被分类的数据样本点,在数据集当中用某种方式找出数据集里面与这个实例“最近的”k 个样本点。然后通过统计看出哪一个类别出现的最多,就把这个样本点归为哪一类。从 KNN 算法的步骤可看出特征工程对 KNN 的表现起着很大的作用。
④随机森林
我们知道机器学习里面有一类算法是极其出名的:以树为基础的算法。这样的决策树一般都是由有向边和节点构成。节点有两种:非叶子节点代表数据集里面的某一个内部特征,叶子节点代表着数据集里面的某一个类别。
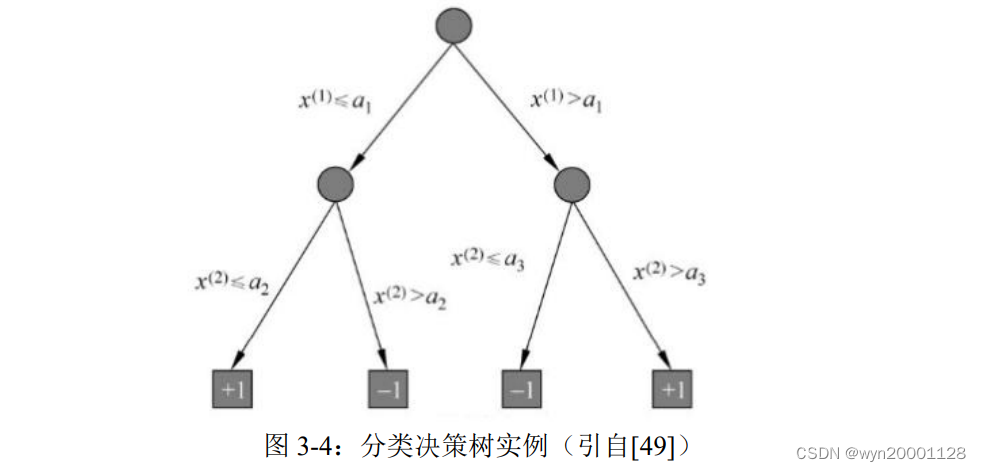
将样本输入以后,先按照根节点里面的特征规则划定路径,然后一步步从根据非叶子节点的规则往下走,最后走到哪一个叶子结点就把该数据样本点划为对应的那个类别。所以在训练决策树的过程当中,选取特征就成为了十分重要的一步。ID3 算法的核心是利用特征的信息增益来选择特征,C4.5 算法则使用的是信息增益比,而 CART 算法使用的是基尼系数。
随机森林:这是决策树在 Bagging 的基础上诞生的模型。具体训练的过程如下:
①从数据集中随机选取 m 个数据样本点,从数据集特征之中随机选取 n 个特征
②利用①选取的数据与特征来对决策树进行训练。
③多次重复步骤①和②训练出多颗决策树
在实际的分类预测当中每一刻决策树都要参与分类,最后所有的分类预测结果中数量最多的那一个类别就是模型的分类结果
⑤Adaboost
Adaboost 就是一个经典的 Boosting 算法的应用。在 Adaboost 算法的初始情况之中,所有的数据点在数据集当中的分布都是均匀的,也就是说一开始所有的数据样本点在模型训练当中都是起着相同的作用的。经过一轮训练以后总有一些错误分类的情况存在,那么此时为了将模型训练的注意力转移到那些分类错误的样本点上的时候,所有样本点的权重都会发生变化。分类正确的数据样本点在总的 Loss 函数上的权重会降低,而分类错误的数据样本点在 Loss 函数上面的权重则会提高。按照这个流程训练下去会得到多个分类器。如何综合利用那么多个分类器所得出来的结果又是一个问题。Adaboost 的策略就是每个分类器进行投票,票数多的那个类就是分类结果。
⑥Bagging
Bagging 的思想是有放回地从训练集当中取出 M 个数据样本,依次放入多个机器学习模型当中进行训练,这样可以得到多个预测模型。对于分类问题,Bagging 所采取的策略是根据各个模型预测出分类结果以后投票表决产生最终的分类结果
Bagging 的核心思想综合考虑了所以模型的预测结果。因为不同的模型学习能力以及学习特点都是不一样的。综合考虑所有模型的预测结果可以说是起到了一个“取长补短”的效果,这样就使得模型对于训练数据集外数据的适配性大大增加,也使得过拟合现象发生的可能性以及过拟合的程度大大减小
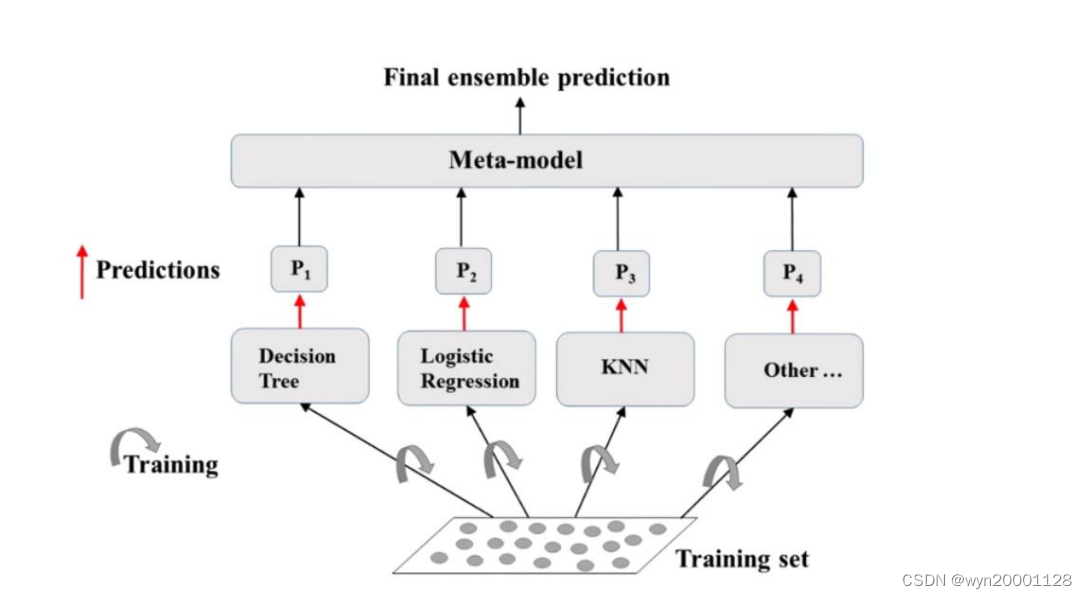
⑦本论文当中的模型
Boosting 让模型的 bias error 变低却让 Variance 变高,这就是说 Boosting 在增加了模型拟合能力的同时很容易让模型发生过拟合现象。同时 Bagging 又可以比较好地降低过拟合现象,基于这两种集成算法的优缺点,我们在论文中使用的集成策略综合了两种集成算法,具体的分类模型结构如下所示:
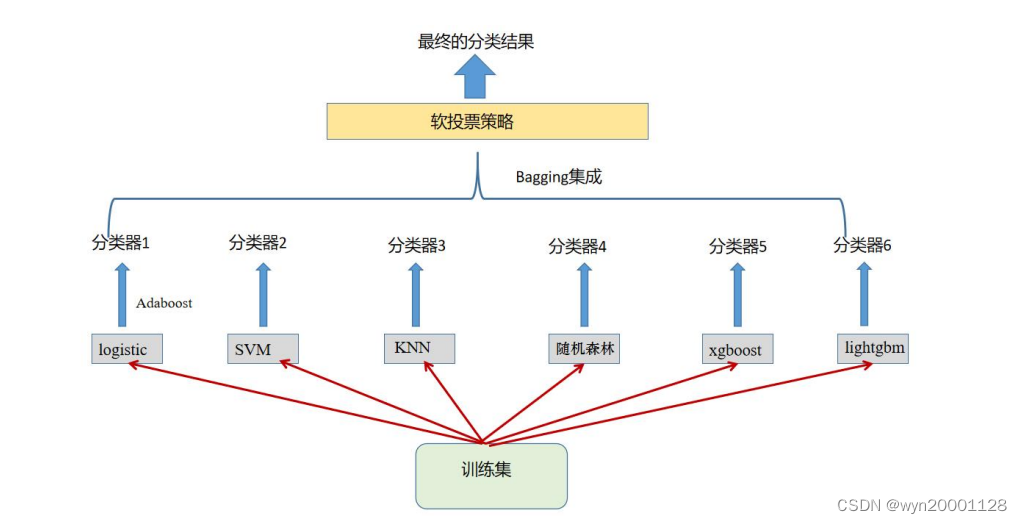
在我们的集成学习建模当中,我们先让 logistic 回归都根据已有的全部训练集为进行Adaboost 来提高模型的拟合能力。因为这个模型的拟合能力相对其他模型比较差一些。Lightgbm,Xgboost 和随机森林都是已经经过集成学习策略优化的模型了所以不需要再次集成。而后使用 6 个分类器进行预测以后使用软投票策略得到最终分类结果。这样集成既考虑到了Boosting对模型拟合能力的提升也考虑到了 Bagging对整个模型Variance 的降低。找到了一个 Bias 和 Variance 的平衡点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









