






一 cuda
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。
CPU是用于负责逻辑性比较强的计算,GPU专注于执行高度线程化的并行处理任务。所以在GPU执行计算任务的时候GPU和CPU是联合执行任务的,并且GPU是作为CPU的“运算辅助结构”。 CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。
下面就是本机pytorch的cuda是否可以工作的代码:
import torch
print(torch.cuda.is_available())
结果为True,显然是可以工作的

二 pytorch加载数据
(1)Dataset
Dataset是里面的一个需要继承以及重写的类,这个类通常是用于提供一种方式去获取每一个条数据以及对应数据的label。在这个类当中我们要写三个方法
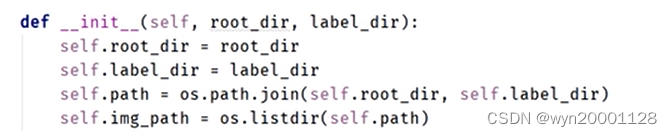
①__init__(self)
这个方法用于构造一些全局变量,便于接下来几个方法的调用。如图所示:
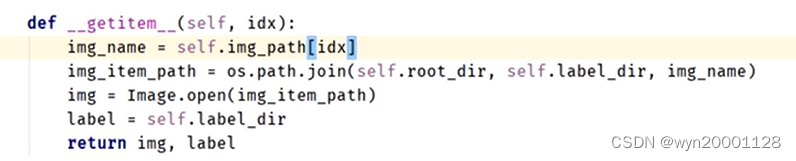
②__getitem__(self,index):
getitem方法是python类编程里面的一种非常神奇的方法,如果给类定义了__getitem__方法,则当按照键取值时,可以直接返回__getitem__方法执行的结果。如下图所示:

这里程序的输出结果是
15
15
15,我们可以看出
s
[
5
]
s[5]
s[5]当中的
5
5
5作为参数被传了进去,并且直接返回了__getitem__(5)执行的结果
我们就要利用__getitem__方法这一个特性来返回数据集里面每一条数据以及对应的标签,如下图所示:
③__len__(self,index):返回数据集的大小
def __len__(self):
return len(self.imformation)
一般在编程的时候先在__init__(self)里面就要分好类而后将其设置为全局变量,后面的方法不用再做类似的事情。后面的两个方法就各司其职。
(2)DataLoader
dataloader 是一个加载器,将数据加载到神经网络中。类比成手(神经网络),dataloader 每次从dataset 中去取数据,怎么取,通过 dataloader 参数进行设置。可以使用以下参数进行初始化,

代码如下所示:
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False)
for data in test_loader:
imgs, targets = data
代码中的每一个 d a t a data data里面都有 64 64 64个加载的数据集里面的训练样本
三 torch.nn(搭建网络与传播过程要用到)
我们咋爱搭建网络的时候一般要重写两种方法
①__init__()方法:这种方法是初始化全局变量便于调用,如下方代码:
def __init__(self):
super().__init__()
self.Sigmoid=torch.nn.Sigmoid()
在以后的 f o r w a r d forward forward函数里面 S i g m o i d Sigmoid Sigmoid就是非线性激活函数 S i g m o i d Sigmoid Sigmoid,方便还可以使用 n n . S e q u e n t i a l nn.Sequential nn.Sequential来把一堆结构连起来当作一个完整的架构如下所示:
self.classifier=nn.Sequential(
nn.Linear(6*6*128,2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(2048,num_classes),
)
在 f o r w a r d forward forward函数里面 c l a s s i f i e r classifier classifier就是这几个层的集合体。
②forward(self,x):一个forward代表了一次前向传播的过程,并且通过类是的实例化可以直接调用,如下代码:
class Mynetwork(nn.Module):
def __init__(self):
super().__init__()
self.Sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.Sigmoid(x)
return x
A=Mynetwork()
x=[1,2,3,4]
x=torch.tensor(x)
B=Mynetwork()
x=B(x)
print(x)
输出的结果为:

四 损失函数和反向传播
pytorch为我们封装了许多的Loss函数和优化器,我们在做反向传播的时候就首先要创建这两个实例,具体的代码如下:
loss_fun=MSELoss()
model=Mynetwork()
optim=SGD(model.parameters(),lr=0.01)#要把模型的参数传进来
for data in dataloader:
input,target=data #从加载的dataloader去除取出数据
output=model(input)#前向传播
loss=loss_fun(output,target)#使用实例化的对象计算损失函数
optim.zero_grad()#调用backward方法计算梯度之前先调用优化器实例的zero_grad()把梯度清零
loss.backward()#调用backward方法计算梯度
optim.step()#调用优化器的step()方法来根据backward计算出来的梯度更新参数
五 使用GPU对模型进行训练
我们如果要把一个东西加载到GPU里面,会写下面所示的代码:
if torch.cuda.is_available():
model.cuda()
意思是GPU存在的话就把代码的东西调入GPU当中
在模型训练的过程当中只有三种东西可以被载入GPU当中
①模型(在把模型对应的类实例化之后再后面加上代码就行)
class Mynetwork(nn.Module):
def __init__(self):
super().__init__()
self.Sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.Sigmoid(x)
return x
model=Mynetwork()
if torch.cuda.is_available():
model.cuda()
②数据和lable(在把数据从dataloader取出来的时候载入)
for data in dataloader:
input,target=data #从加载的dataloader去除取出数据
if torch.cuda.is_available():
input.cuda()
target.cuda()
output=model(input)#前向传播
③损失函数
六 模型训练流程
①数据准备:写Dataset类来组织数据,然后将其加载到Dataloader类里面进行数据的训练。很多数据都已经被pytorch组织成Dataset类了。但是到没有被组织的时候通常需要自己重写一个Dataset类来组织自己的数据

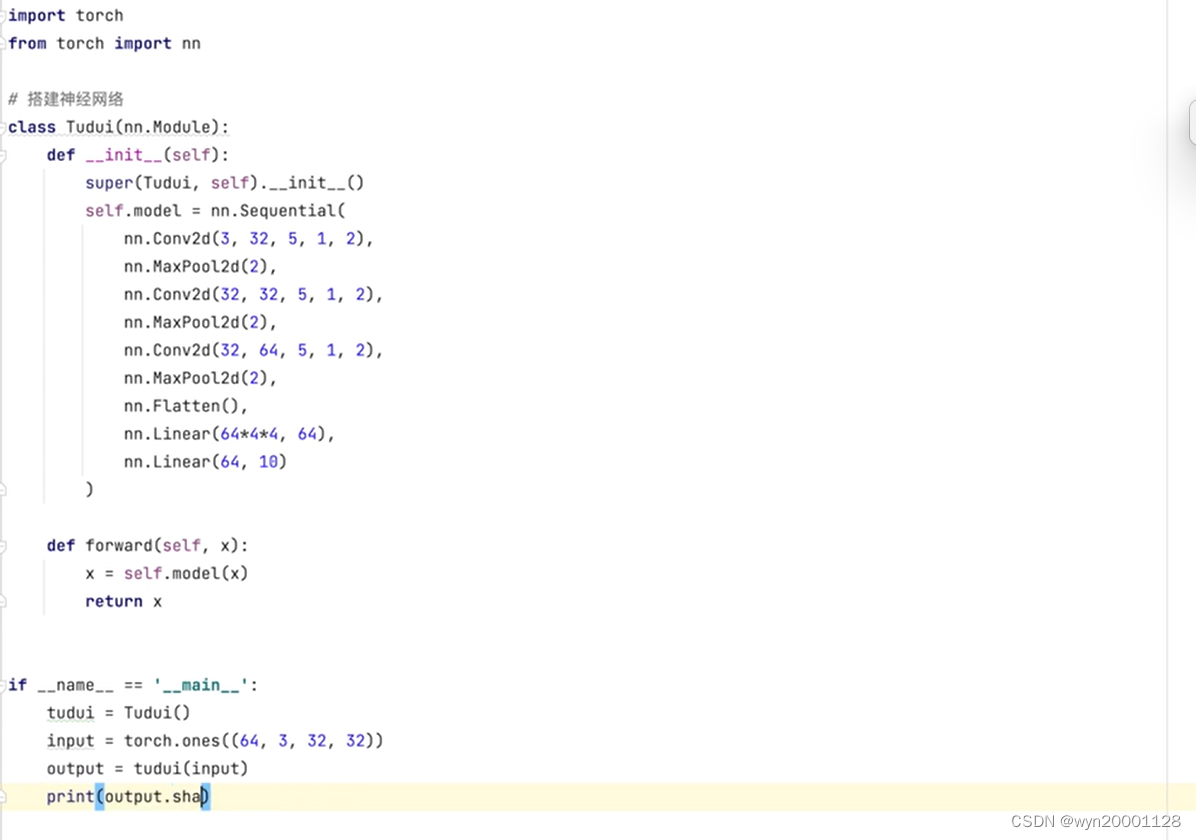
②模型准备:继承model类来写一个模型,通常一般放在另外一个文件里面,还可以在那里测试网络的输出:
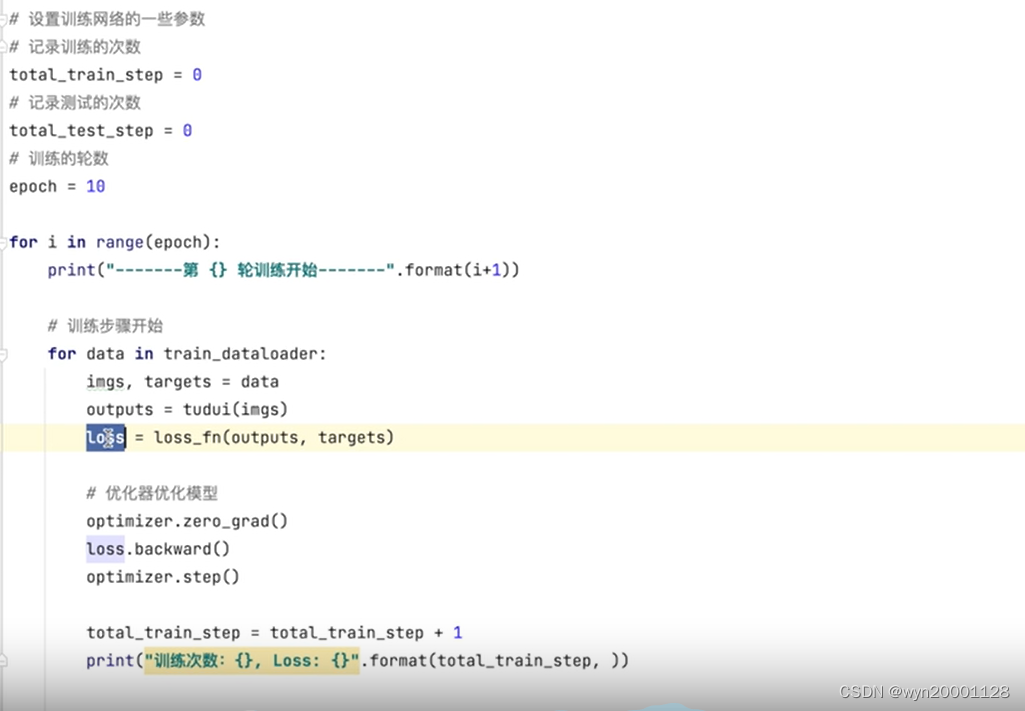
③模型的正式训练
(1)模拟每一个样本的训练过程(包括建立优化器和损失函数。前向传播,计算损失值,梯度清零,计算梯度,更新参数,):
(2)在训练的过程当中可以设置一些数例如损失函数,验证集的准确率得到来反映模型在训练过程中的效果变化。
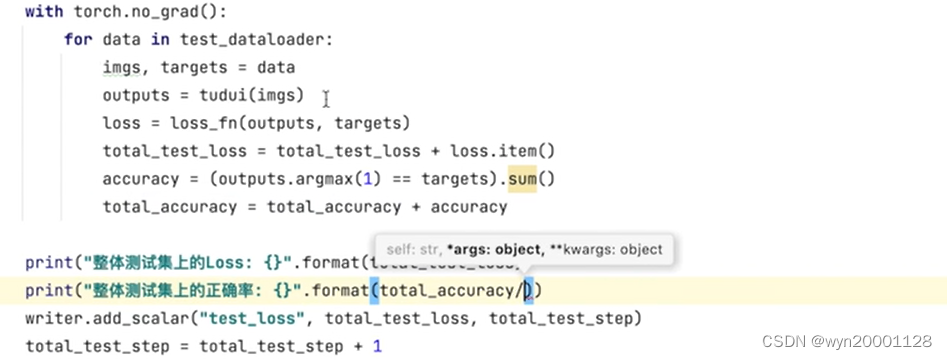
(3)模型保存

(4)两条特殊指令model.train()和model.eval
1 model.train()
启用 Batch Normalization 和 Dropout。如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()作用:对BN层,保证BN层能够用到每一批数据的均值和方差,并进行计算更新;对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
2. model.eval()
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层直接利用之前训练阶段得到的均值和方差,即测试过程中要保证BN层的均值和方差不变;对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









