







1、什么是内存屏障?
现在大多数现代计算机为了提高性能而采取乱序执行,这可能会导致程序运行不符合我们预期,内存屏障就是一类同步屏障指令,是CPU或者编译器在对内存随机访问的操作中的一个同步点,只有在此点之前的所有读写操作都执行后才可以执行此点之后的操作。
2、为什么会出现内存屏障
内存屏障存在的意义就是为了解决程序在运行过程中出现的内存乱序访问问题,内存乱序访问行为出现的理由是为了提高程序运行时的性能,Memory Bariier能够让CPU或编译器在内存访问上有序。
在进一步剖析为什么会出现内存屏障之前,如果你对Cache原理还不了解,强烈建议先阅读一下这篇文章,对Cache有了一定的了解之后,再阅读下面的内容。
2.1、内存屏障出现的背景(内存乱序是怎么出现的?)
早期的处理器为有序处理器(In-order processors),有序处理器处理指令通常有以下几步:
- 指令获取
- 如果指令的输入操作对象(input operands)可用(例如已经在寄存器中了),则将此指令分发到适当的功能单元中。如果一个或者多个操 作对象不可用(通常是由于需要从内存中获取),则处理器会等待直到它们可用
- 指令被适当的功能单元执行
- 功能单元将结果写回寄存器堆(Register file,一个 CPU 中的一组寄存器)
相比之下,乱序处理器(Out-of-order processors)处理指令通常有以下几步:
- 指令获取
- 指令被分发到指令队列(Invalidate Queues,后面会讲到)
- 指令在指令队列中等待,直到输入操作对象可用(一旦输入操作对象可用,指令就可以离开队列,即便更早的指令未被执行)
- 指令被分配到适当的功能单元并执行
- 执行结果被放入队列(放入到store buffer中,而不是直接写到cache中,后面也会讲到)
- 只有所有更早请求执行的指令的执行结果被写入cache后,指令执行的结果才被写入cache(执行结果重排序,让执行看起来是有序的)
已经了解了cache的同学应该可以知道,如果CPU需要读取的地址中的数据已经已经缓存在了cache line中,即使是cpu需要对这个地址重复进行读写,对CPU性能影响也不大,但是一旦发生了cache miss(对这个地址进行第一次写操作),如果是有序处理器,CPU在从其他CPU获取数据或者直接与主存进行数据交互的时候需要等待不可用的操作对象,这样就会非常慢,非常影响性能。举个例子:
如果CPU0发起一次对某个地址的写操作,但是其local cache中没有数据,这个数据存放在CPU1的local cache中。为了完成这次操作,CPU0会发出一个invalidate的信号,使其他CPU的cache数据无效(因为CPU0需要重新写这个地址中的值,说明这个地址中的值将被改变,如果不把其他CPU中存放的该地址的值无效,那么就有可能会出现数据不一致的问题)。只有当其他之前就已经存放了改地址数据的CPU中的值都无效了后,CPU0才能真正发起写操作。需要等待非常长的时间,这就导致了性能上的损耗。
但是乱序处理器山就不需要等待不可用的操作对象,直接把invalidate message放到invalidate queues中,然后继续干其他事情,提高了CPU的性能,但也带来了一个问题,就是程序执行过程中,可能会由于乱序处理器的处理方式导致内存乱序,程序运行结果不符合我们预期的问题。
2.2、内存屏障的分类
Memory Barrier能够让CPU或编译器在内存访问上有序。内存屏障包括两类:
编译器内存屏障
Linux 内核提供函数barrier()用于让编译器保证其之前的内存访问先于其之后的完成。#define barrier() __asm__ __volatile__("" ::: "memory")CPU内存屏障
1、通用barrier,保证读写操作有序,mb()和smp_mb()
2、写操作barrier,仅保证写操作有序,wmb()和smp_wmb()
3、读操作barrier,仅保证读操作有序,rmb()和smp_rmb()
3、有什么优化方法?
3.2、硬件上的优化
3.2.1、store buffer
有一种可以阻止CPU进入阻塞状态的方法,就是在CPU和cache之间加入一个store buffer的硬件结构,如下图:
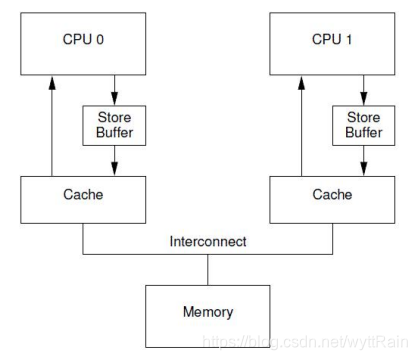
加入了这个硬件结构后,但CPU0需要往某个地址中写入一个数据时,它不需要去关心其他的CPU的local cache中有没有这个地址的数据,它只需要把它需要写的值直接存放到store buffer中,然后发出invalidate的信号,等到成功invalidate其他CPU中该地址的数据后,再把CPU0存放在store buffer中的数据推到CPU0的local cache中。每一个CPU core都拥有自己私有的store buffer,一个CPU只能访问自己私有的那个store buffer。
3.2.1.1、store buffer的弊端
先看看下面的代码,思考一下会不会出现什么问题
a = 1;
b = a + 1;
assert(b = 2);
我们假设变量a的数据存放在CPU1的local cache line中,变量b在CPU0的cache line中,如果我们单纯使用CPU来运行上面这段程序,应该是正常运行的,但是如果加入了store buffer这个硬件结构,就会出现assert失败的问题,到底是为什么呢?我们来走一走程序的流程。
- CPU0执行a=1这条命令,由于CPU0本地没有数据,会发出read invalidate消息从CPU1那获得数据,并发出invalidate命令
- CPU0把要写入的数据放到store buffer中
- CPU1接收到了CPU0发来的read invalidate信号,将其local cache line 中的数据发送给CPU0,并把自己本地cache line中的数据设置为无效
- CPU0执行b=a+1
- CPU0接收到CPU1返回回来的a的值,等于0,b=0+1=1
- CPU0将store buffer中的a=1的值推入到cache中,造成了数据不一致性
3.2.1.2、store forwarding
硬件上出现一种新的设计,为了解决优化上面所说的store buffer的弊端, 具体结构如下图:
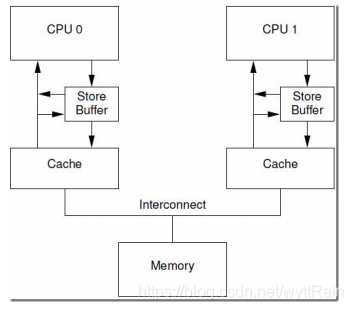
当CPU执行load操作的时候,不但要看cache,还要看store buffer中是否有内容,如果store buffer有该数据,那么就采用store buffer中的值。
但是这样,就能保证程序的正确运行,就能保证数据的一致性了吗?并不是!!
3.3、软件上的优化
我们先来分析分析一个例子,看看下面的例子有可能会出现什么问题
void foo(void)
{
a = 1;
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
同样,我们假设a和b都是初始化为0,CPU0执行foo函数,CPU1执行bar函数,a变量在CPU1的cache中,b在CPU0的cache中
- CPU0执行a=1的操作,由于a不在local cache中,CPU0会将a的值写入到store buffer中,然后发出read invalidate信号从其他CPU获取a 的值
- CPU1执行while(b == 0),由于b不在local cache中,CPU发送一个read message到总线上,看看是否可以从其他CPU的local cache中或者memory中获取数据
- CPU0继续执行b=1,由于b就在自己的local cache中,所以CPU0可以直接把b=1直接写入到local cache
- CPU0收到read message,将最新的b=1的值回送到CPU1,同时把存放b数据的cache line在状态设置为sharded
- CPU1收到来自CPU0的read response消息,将b变量的最新值1写入自己的cachelline,并设置为sharded。
- 由于b的值为1,CPU1跳出while循坏,继续执行
- CPU1执行
assert(a==1),由于CPU1的local cache中a的值还是旧的值为0,assert(a==1)失败。 - 这个时候,CPU1收到了CPU 0的read invalidate消息(执行了a=1),清空了自己local cache中a的值,但是已经太晚了
- CPU0收到CPU1的invalidate ack消息后,将store buffer中的a的最新值写入到cache line,然并卵,CPU1已经assertion fali了。
这个时候,就需要加入一些memory barrier的操作了。说了这么久,终于说到了内存屏障了,我们把代码修改成下面这样:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
可以看到我们在foo函数中增加了一个smp_mb()的操作,smp_mb有什么作用呢?
它主要是为了让数据在local cache中的操作顺序服务program order的顺序,那么它又是怎么让store buffer中存储的数据按照program order的顺序写入到cache中的呢?我们看看数据读写流程跟上面没有加smp_mb的时候有什么区别
- CPU0执行a=1的操作,由于a不在local cache中,CPU0会将a的值写入到store buffer中,然后发出read invalidate信号从其他CPU获取a 的值
- CPU1执行while(b == 0),由于b不在local cache中,CPU发送一个read message到总线上,看看是否可以从其他CPU的local cache中或者memory中获取数据
- CPU0在执行b=1前,我们先执行了smp_mb操作,给store buffer中的所有数据项做了一个标记marked,这里也就是给a做了个标记
- CPU0继续执行b=1,虽然b就在自己的local cache中,但是由于store buffer中有marked entry,所遇CPU0并没有把b的值直接写到cache中,而是把它写到了store buffer中
- CPU0收到read message,将最新的b=1的值回送到CPU1,同时把存放b数据的cache line在状态设置为sharded
- CPU1收到来自CPU0的read response消息,将b变量的值0写入自己的cachelline(
因为b的最新值1还存放在store buffer中),并设置为sharded。 - 完成了bus transaction之后,CPU1可以load b到寄存器中了,当然,这个时候b的指还是0
- CPU1收到了来自CPU0的read invalidate消息(执行了a=1),清空了自己local cache中a的值
- CPU0将存放在store buffer中的a=1的值写入cache line中,并设置为modified
- 由于store buffer中唯一一个marked的entry已经写入到cache line中了,所以b也可以进入cache line。不过需要注意的是,当前b对应的cache line状态还是sharded(因为在CPU1中的cache line中还保留有b的数据)
- CPU0发送invalidate消息,CPU1清空自己的b cacheline,CPU0将b cacheline设置为exclusive
你以为这样就完了吗????NONONONO!!!!太天真了
3.4、Invalidate Queues
不幸的是:每个CPU的store buffer不能实现地太大,其存储队列的数目也不会太多。当CPU以中等的频率执行store操作的时候(假设所有的store操作都导致了cache miss),store buffer会很快的呗填满。在这种情况下,CPU只能又进入阻塞状态,直到cacheline完成invalidation和ack的交互后,可以将store buffer的entry写入cacheline,从而让新的store让出空间之后,CPU才可以继续被执行。
这种情况也可能发生在调用了memory barrier指令之后,因为一旦store buffer中的某个entry被标记了,那么随后的store都必须等待invalidation完成,因此不管是否cache miss,这些store都必须进入store buffer。
这个时候,invalidate queues就出现了,它可也缓解这个情况。store buffer之所以很容易被填满,主要是因为其他CPU在回应invalidate acknowledge比较慢,如果能加快这个过程,让store buffer中的内容尽快写入到cacheline,那么就不会那么容易被填满了。
而invalidate acknowledge不能尽快回复的主要原因,是因为invalidate cacheline的操作没有那么块完成,特别是在cache比较繁忙的时候,如果再收到其他CPU发来的invalidate请求,只有在完成了invalidate操作后,本CPU才会发送invalidate acknowledge。
然而,CPU其实不需要完成invalidate就可以回送acknowledgement消息,这样就不会阻止发送invalidate的那个CPU进去阻塞状态。CPU可以将这些接收到的invalidate message存放到invalidate queues中,然后直接回应acknowledge,表示自己已经收到请求,随后会慢慢处理,当时前提是必须在发送invalidate message的CPU发送任何关于某变量对应cacheline的操作到bus之前完成。结构如下图:
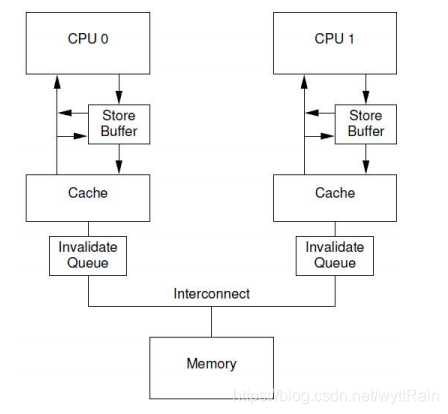
4、ARM架构下的内存屏障
4.1、内存屏障指令
在ARM架构中,有3条内存屏障指令,分别是:
数据存储屏障(Data Memory Barrier,DMB)指令数据同步屏障(Data Synchronization Barrier,DSB)指令指令同步屏障(Instruction Synchronization Barrier,ISB)指令
4.2、Linux内核中的内存屏障接口函数和使用
未完待续…















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









