






题目:压缩感知重构算法之子空间追踪(SP)
如果掌握了压缩采样匹配追踪(CoSaMP)后,再去学习子空间追踪(Subspace Pursuit)是一件非常简单的事情,因为它们几乎是完全一样的。
SP的提出时间比CoSaMP提出时间略晚,首个论文版本是参考文献[1],后来更新了两次,最后在IEEE Transactions on Information Theory发表[2]。从算法角度来讲,SP与CoSaMP差别非常小,这一点作者也意识到了,在文献[1]首页的左下角就有注释:

在文献[2]第2页提到了SP与CoSaMP的具体不同:

从上面可以知道,SP与CoSaMP主要区别在于“Ineach iteration, in the SP algorithm, only K new candidates are added, while theCoSAMP algorithm adds 2K vectors.”,即SP每次选择K个原子,而CoSaMP则选择2K个原子;这样带来的好处是“This makes the SP algorithm computationally moreefficient,”。
以下是文献[2]中的给出的SP算法流程:

这个算法流程的初始化(Initialization)其实就是类似于CoSaMP的第1次迭代,注意第(1)步中选择了K个原子:“K indices corresponding to the largest magnitude entries”,在CoSaMP里这里要选择2K个最大的原子,后面的其它流程都一样。这里第(5)步增加了一个停止迭代的条件:当残差经过迭代后却变大了的时候就停止迭代。
不只是SP作者认识到了自己的算法与CoSaMP的高度相似性,CoSaMP的作者也同样关注到了SP算法,在文献[3]中就提到:

文献[3]是CoSaMP原始提出文献的第2个版本,文献[3]的早期版本[4]是没有提及SP算法的。
鉴于SP与CoSaMP如此相似,这里不就再单独给出SP的步骤了,参考《压缩感知重构算法之压缩采样匹配追踪(CoSaMP)》,只需将第(2)步中的2K改为K即可。
引用文献[5]的3.5节中的几句话:“贪婪类算法虽然复杂度低运行速度快,但其重构精度却不如BP类算法,为了寻求复杂度和精度更好地折中,SP算法应运而生”,“SP算法与CoSaMP算法一样其基本思想也是借用回溯的思想,在每步迭代过程中重新估计所有候选者的可信赖性”,“SP算法与CoSaMP算法有着类似的性质与优缺点”。
子空间追踪代码可实现如下(CS_SP.m),通过对比可以知道该程序与CoSaMP的代码基本完全一致。本代码未考虑文献[2]中的给出的SP算法流程的第(5)步。代码可参见参考文献[6]中的Demo_CS_SP.m。鉴于SP与CoSaMP的极其相似性,这里就不再给出单次重构和测量数M与重构成功概率关系曲线绘制例程代码了,只需将CoSaMP中调用CS_CoSaMP函数的部分改为调用CS_SP即可,无须任何其它改动。这里给出对比两种重构算法所绘制的测量数M与重构成功概率关系曲线的例程代码,只有这样才可以看出两种算法的重构性能优劣,以下是在分别运行完SP与CoSaMP的测量数M与重构成功概率关系曲线绘制例程代码的基础上,即已经存储了数据CoSaMPMtoPercentage1000.mat和SPMtoPercentage1000.mat:
运行结果如下:
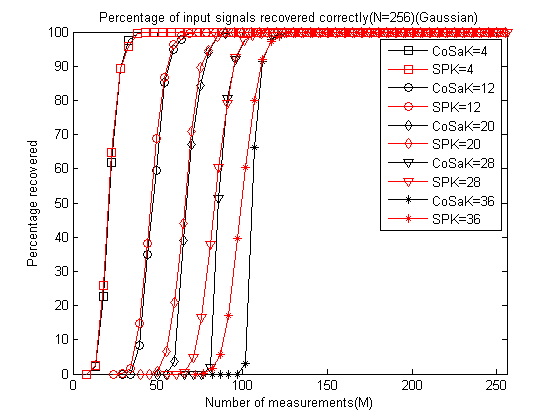
可以发现在M较小时SP略好于CoSaMP,当M变大时二者重构性能几乎一样。
参考文献:
[1]Dai W,Milenkovic O. Subspace pursuitfor compressive sensing: Closing the gap between performance and complexity.http://arxiv.org/pdf/0803.0811v1.pdf
[2]Dai W,Milenkovic O.Subspacepursuit for compressive sensing signal reconstruction[J].IEEETransactions on Information Theory,2009,55(5):2230-2249.
[3]D. Needell, J.A. Tropp.CoSaMP: Iterative signal recoveryfrom incomplete and inaccurate samples. http://arxiv.org/pdf/0803.2392v2.pdf
[4]D. Needell, J.A. Tropp.CoSaMP: Iterative signal recoveryfrom incomplete and inaccurate samples. http://arxiv.org/pdf/0803.2392v1.pdf
[5]杨真真,杨震,孙林慧.信号压缩重构的正交匹配追踪类算法综述[J]. 信号处理,2013,29(4):486-496.
[6]Li Zeng. CS_Reconstruction. http://www.pudn.com/downloads518/sourcecode/math/detail2151378.html















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









