






题目:压缩感知重构算法之Gradient Descent with Sparsification(GraDeS)
本篇介绍压缩感知重构算法GraDes(GradientDescent with Sparsification),该算法是在文献【GargR, Khandekar R. Gradient descent with sparsification: an iterative algorithmfor sparse recovery with restricted isometry property[C]//Proceedings of the26th Annual International Conference on Machine Learning. ACM, 2009: 337-344】中提出的,该论文可由链接【1】下载,另外,该论文在发表的会议上有一个talk,PPT见链接【2】,两位作者的主页参见链接【3】。文章的署名单位为IBM的T.J. Watson Research Center,目前第一作者Rahul Garg已到印度理工学院(德里校区)工作。
1、算法
先说一下符号约定,算法GraDeS是为了求解如下问题:
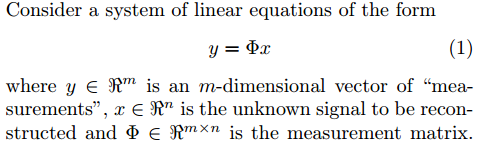
接下来,我们来看一下算法GraDeS的具体内容:

其中:
函数Ψ(x)定义如下:
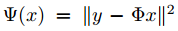
符号Hs(·)的含义如下:
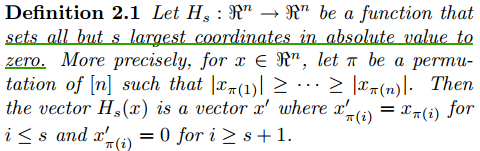
也就是说,Hs(x)是将一个n维向量x中最大的s个值保留,其余全部置零,也就是将n维向量x强制变为s稀疏的。文章中紧跟表格Algorithm1有一段有关Hs(·)的描述:

参数γ的取值参见Theorem 2.1:

即若要恢复一个s稀疏的向量x,γ等于1加上矩阵Φ的2s阶有限等距常数δ2s。另外,在Theorem2.1中要求矩阵Φ的2s阶有限等距常数δ2s<1/3,还给出了具体的迭代次数公式。但个人感觉,Theorem 2.1的结果并没有实际意义,无论是参数γ还是迭代次数,原因很简单,因为在实际当中矩阵Φ的2s阶有限等距常数δ2s根本无法得到。
2、GraDeS算法MATLAB代码
作者给出了该函数的MATLAB代码,参见链接【4】,官方版本略微复杂,为了便于理解算法,这里根据Algorithm1,给出一个简化版的GraDeS的实现代码,该算法是如此的简单,以至于我们可以很轻松地写出来:
注:本来就单纯想按照论文的Algorithm 1中的流程写了个简简单单的函数,但在while循环条件里面仍然加入了最大循环次数的限制,这是因为仿真过程中发现程序经常处于死循环状态。
这里也给出作者的官方版本(参见链接【4】):
3、单次重构代码
注1:这里不给出仿真结果了,因为仿真结果不太好,总是无法重构;
注2:Phi必须经过“Phi= orth(Phi')';”处理,否则根本没有重构结果输出。
4、为什么能够重构?
该算法比以往介绍的任何算法都要简单,但为什么执行以下迭代
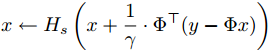
最终就可以得到稀疏解x呢?我们来看文章2.1节的一段描述:

也就是说,每次迭代,我们都会根据参数γ沿着目标函数Ψ(x)梯度相反的方向走一步,为了保证每次迭代后仍是s稀疏的,对迭代结果执行硬阈值(hard-thresholding),也就是函数Hs(·)。
那么这里有两个问题:
一是为什么沿着目标函数Ψ(x)梯度相反的方向走一步会使目标函数变小?
二是执行硬阈值后会不会使目标函数Ψ(x)很大幅度地增加?
对于第一个问题:
实际上,这个类似于最优化方法中的梯度下降法(或称最速下降法),我们举一个简单例子,比如f(x)=x2,求它的梯度(也就是导数)▽f(x)=2x,对于变量x来说只有两个移动方向,要么是正方向,要么是负方向:
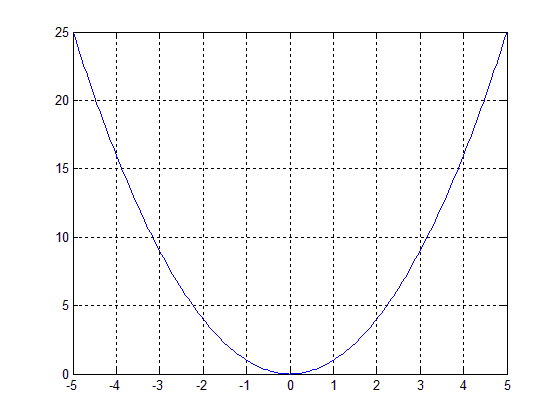
假设我们的初始点在x=4,这时梯度▽f(4)=2×4=8>0,梯度方向(单位向量可以通过▽f(x)/|| ▽f(x)||得到)为正方向(即由0指向1),其反方向为负方向(即由0指向-1),从f(x)=x2的图像中可以很容易的知道,从x=4往负方向走一步函数值会下降(当然步子不能迈得太大);假设我们的初始点在x=-4,这时梯度▽f(4)=2×(-4)=-8<0,梯度方向为负方向(即由0指向-1),其反方向为正方向(即由0指向1),从f(x)=x2的图像中可以很容易的知道,从x=-4往正方向走一步函数值会下降(当然步子也不能迈得太大)。因为这个自变量只有一个,所以可移动的方向只有两个,即在一条直线上移动;如果自变量有两个的话,则移动范围是在一个平面上。求解只有一个变量函数的极值问题即为一维极值问题,求解有多个变量函数的极值问题即为多维极值问题。
对于第二个问题:
为了解释第二个问题,先来看一段文章内容:

注:w.r.t.意思是“关于”,是英文“with regard to”或“withreference to”或“with respect to”的简称。
这段内容首先是对该算法的原理进行了简要的描述,这个类似于分析第一个问题中的引用的那段话;紧跟着有一句非常关键的话“the RIP of Φ impliesthat the sparsification step does not increase the error Ψ(x) by too much”,也就是说Φ的RIP保证了稀疏步骤(sparsificationstep,即执行硬阈值步骤)不会使Ψ(x)误差增加很多。但刨根问底,为什么呢?接下来提到这篇论文重要的贡献是分析了硬阈值函数Hs(·)对Ψ(x)的影响,也就是Lemma 2.4。
引理2.4是由下面内容引出的:

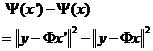
其中:
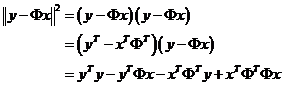
同理:
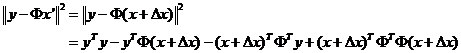
将带括号的三项拆开:
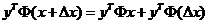
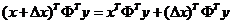
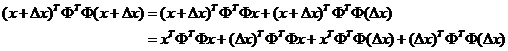
所以
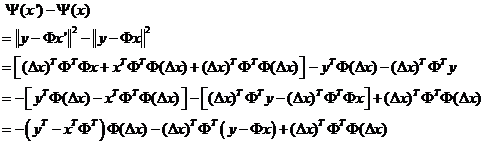
由于
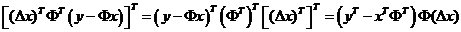
所以
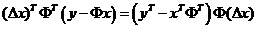
注:上面相等的原因是由于二者均为1×1的矩阵,即为一个数;而一个数的共轭等于它本身。
进而
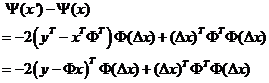
值得注意的是文中的推导至此有一点小错误:
矩阵Φ的维数为m×n,因此转置后ΦT的维数为n×m,(y-Φx)的维数是m×1,△x的维数为n×1,所以不可能为文中的
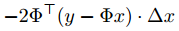
因为根本不满足矩阵相乘的维度条件。因此,g的定义应该为
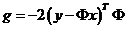
式(5)就是应用了RIP性质不等式,这是因为
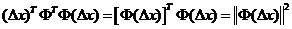
根据文中式(3)即可得式(5)。至于这里为什么是2s阶有限等距常数δ2s可简单这样理解:两个s稀疏的向量相减,最坏的情况是两个相量各自s个有值的位置都不对应,所以减完之后的结果最坏情况会包含2s个值,也就是稀疏度是2s。
式(6)就是简单的令γ=δ2s+1便可由式(5)得到(参见定理2.1)。
整个推导结果的意义在于执行一次迭代后,目标函数的变化不大于式(6)。
分析完了引理2.4的铺垫,接下来那么我们就来看一下引理2.4的具体内容:

引理2.4的意思是,对于目标函数
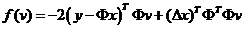
在约束条件
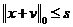
即x+v稀疏度不超过s的约束下,其最小值在△x处取得。也就是说式(6)的结果是一个最小值。下面是证明过程,有兴趣的可以研究一下,只要把符号搞清楚也并不是很复杂:


5、结束语
值得注意的是,这个算法应该不属于凸优化类重构算法。其实这些天一直在学习凸优化类重构算法,但由于各算法之间的复杂关系,最后居然先学习完了GraDeS这个算法,因此就先写写有关它的总结了……
另外,学习研究了几天,但重构结果并不是很好,心中有一点失落……
算了,还是继续前行吧……
6、参考链接:
【1】Download:
http://www.cse.iitd.ac.in/~rahulgarg/Publications/2009/GK09.icml.pdf
http://people.cse.iitd.ernet.in/~rohitk/research/sparse.pdf
【2】PPT: http://www.cse.iitd.ac.in/~rahulgarg/Publications/2009/GK09.icml.talk.pdf
【3】Author Homepage:
http://www.cse.iitd.ac.in/~rahulgarg/
http://people.cse.iitd.ernet.in/~rohitk/
【4】Code: http://www.cse.iitd.ac.in/~rahulgarg/Code/grades.m















 5254
5254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









