







Keras 预训练模型简介
在 Keras 中,包含有一个辅助应用模块 keras.applications,其提供了带有预训练权重的 Keras 模型。你可以直接使用这些模型,或者像本文一样对模型进行改造后完成迁移学习。
计算机视觉领域,有 3 个最著名的比赛,分别是:ImageNet ILSVRC,PASCAL VOC 和微软 COCO 图像识别大赛。其中,Keras 中的模型大多是以 ImageNet 提供的数据集进行权重训练。
目前,Keras 包含有 5 个预训练模型,分别为:Xception,VGG16,VGG19,ResNet50,InceptionV3,MobileNet。其中:
Xception 由 Google 在 2016 年基于 ImageNet 完成训练,并取得了验证集 top1 0.790 和 top5 0.945 的分类正确率。目前,Keras 采用的 Xception 模型预训练权重由 Keras 训练而来。Keras 导入 Xception 模型及默认参数如下:
keras.applications.xception.Xception(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
VGG16 模型和VGG19模型均有牛津大学 VGG(Visual Geometry Group)发布的预训练权重移植而来。VGG 模型取得的成绩如下:
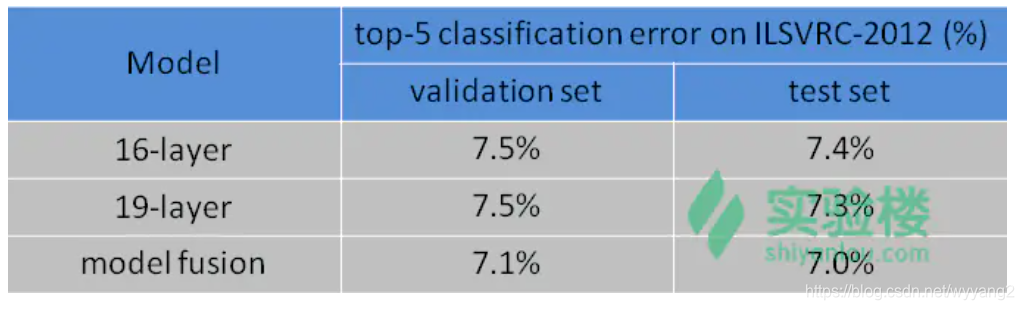
Keras 导入 VGG16 和 VGG19 模型及默认参数如下:
keras.applications.vgg16.VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
keras.applications.vgg19.VGG19(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
ResNet50 是由微软团队训练的 50 层残差网络模型。其在 ILSVRC & COCO 2015 比 中获得了第一名,比 VGG16 的错误分类率更低。ResNet50 模型预训练权重由原团队移植而来。Keras 导入 ResNet50 模型及默认参数如下:
keras.applications.resnet50.ResNet50(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
InceptionV3模型由 Google 构建,其通过 ILSVRC 2012 提供的基准测试得到了 Top-1 4.2% 的错误分类率。Keras 导入 InceptionV3 模型及默认参数如下:
keras.applications.inception_v3.InceptionV3(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
MobileNet 模型是 Google 发布用于移动端和嵌入式设备的卷积神经网络模型。与其他模型相比,MobileNet 在计算资源和预测精度之间进行了均衡,可广泛应用与对象检测、细粒度分类、面部识别以及大规模地理定位等方面。Keras 导入 MobileNet 模型及默认参数如下:
keras.applications.mobilenet.MobileNet(input_shape=None, alpha=1.0, depth_multiplier=1, dropout=1e-3, include_top=True, weights='imagenet', input_tensor=None, pooling=None, classes=1000)
使用 InceptionV3 完成 ImageNet 分类
下面,我们使用 Karas 提供的 InceptionV3 预训练模型完成 ImageNet ILSVRC 分类。
上面我们提到过,ImageNet 是目前世界上最大的可用于机器学习图像测试的数据集,其拥有超过 1500 万张训练图片,以及经过标记的2.2万种类别。值得一提的是,ImageNet 最初是由华裔科学家李飞飞带领的团队创建,她也是著名的机器学习专家,目前在斯坦福任教。
在本章节中,我们打算采用 InceptionV3 预训练模型对 ImageNet ILSCVRC 所包含的类别集合进行识别。ILSCVRC 的全称为 ImageNet Large Scale Visual Recognition Competition,译作:ImageNet 大规模图像识别竞赛。其包含的标签数量为1000种(下图)。

下面,我们使用 Keras 来构建图像识别代码。我们要实现的效果大致为:导入一张图片,然后让预训练模型来判断图片中所包含的主体要素是什么(汽车?长颈鹿?狗熊?)。
在这之前,我们先打开终端,初步尝试构建模型:
# 导入模型
>>> from keras.applications.inception_v3 import InceptionV3
# 构建 InceptionV3 模型
>>> model = InceptionV3()
你会发现,终端开始尝试从 Github 上,下载以.h5结尾的InceptionV3 预训练模型。
由于模型较大,十分容易出现下载失败的情况。本次实验已经预先下载好 InceptionV3 预训练模型,并传到的实验楼自己的服务器上。
你可以直接关闭正在执行的终端,重新打开新终端,通过以下代码,将模型下载下来,并放到正确的位置:
# 切换到 Keras 预训练模型保存位置
cd ~/.keras/models
# 从实验楼服务器下载 InceptionV3 预训练模型
wget http://labfile.oss.aliyuncs.com/courses/932/inception_v3_weights_tf_dim_ordering_tf_kernels.h5
# 从实验楼服务器下载 ImageNet ILSCVRC 类别索引
wget http://labfile.oss.aliyuncs.com/courses/932/imagenet_class_index.json
正常情况下,你会在数秒之后完成模型下载。

当然,在此也提供了两张演示照片,方便测试。你需要提前下载到实验环境中:
# 切换默认目录
cd ~
# 从实验楼服务器下载演示照片
wget http://labfile.oss.aliyuncs.com/courses/932/demo1.jpg
wget http://labfile.oss.aliyuncs.com/courses/932/demo2.jpg
完成上面的准备工作,我们就可以开始图像识别了。
>>> import numpy as np
>>> from keras.preprocessing import image
>>> from keras.applications.inception_v3 import InceptionV3
>>> from keras.applications.inception_v3 import preprocess_input
>>> from keras.applications.inception_v3 import decode_predictions
# 新建模型,此处实际上是导入预训练模型
>>> model = InceptionV3()
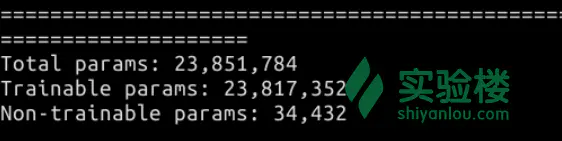
model.summary()
我们可以先用.summary()方法看一下 InceptionV3 模型的内部构成。可以看到,该模型拥有 313 层,包含了 23,851,784 个参数。这是一个相当复杂的模型。
接着书写代码
# 按照 InceptionV3 模型的默认输入尺寸,载入 demo1 图像
img = image.load_img('demo1.jpg', target_size=(299, 299))
# 提取特征
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 预测并输出概率最高的三个类别
preds = model.predict(x)
print('Predicted:', decode_predictions(preds, top=3)[0])
我们可以看到输出结果:

也就是说,有76.4%的概率,该照片中包含有 macaque(猕猴)。demo1 图像如下:

的确是猕猴,模型预测正确了。
以上,我们就使用InceptionV3 预训练模型完成了图像识别。InceptionV3预训练模型是非常厉害的,Google 采用了 120 万张图片,经由数周训练完成。
实验总结
文章的主要内容是使用Keras 预训练模型对图像进行识别。学完之后,我们应该可以使用 InceptionV3 构建的小脚本去完成一些有趣的识别游戏。
但是,这里所用到的 InceptionV3是封装好的.h5 模型文件,里面包含有预先训练好的权重值。在下一个章节(指该教程的下一个章节)中,我们会对模型进行拆解,然后经过对神经网络层改造之后,使之能更好地完成精度要求更高的分支问题(只识别猫或狗)。也就是要谈到的迁移学习。
参考资料:
《How to build an image recognition system using Keras and Tensorflow for a 1000 everyday object categories (ImageNet ILSVRC)》
作者:蓝桥云课
链接:https://www.jianshu.com/p/6d71c745f62b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









