







一、前言:
现在,正式开始步入数据结构的大门,对于这门课程,务必花上心思去学,请不要学得一知半解,不求甚解。遇到理解不了的代码,请你动起手来,画出他们的示意图。经常性的练习,日复一日,你定能行!
二、知识体系与总结:
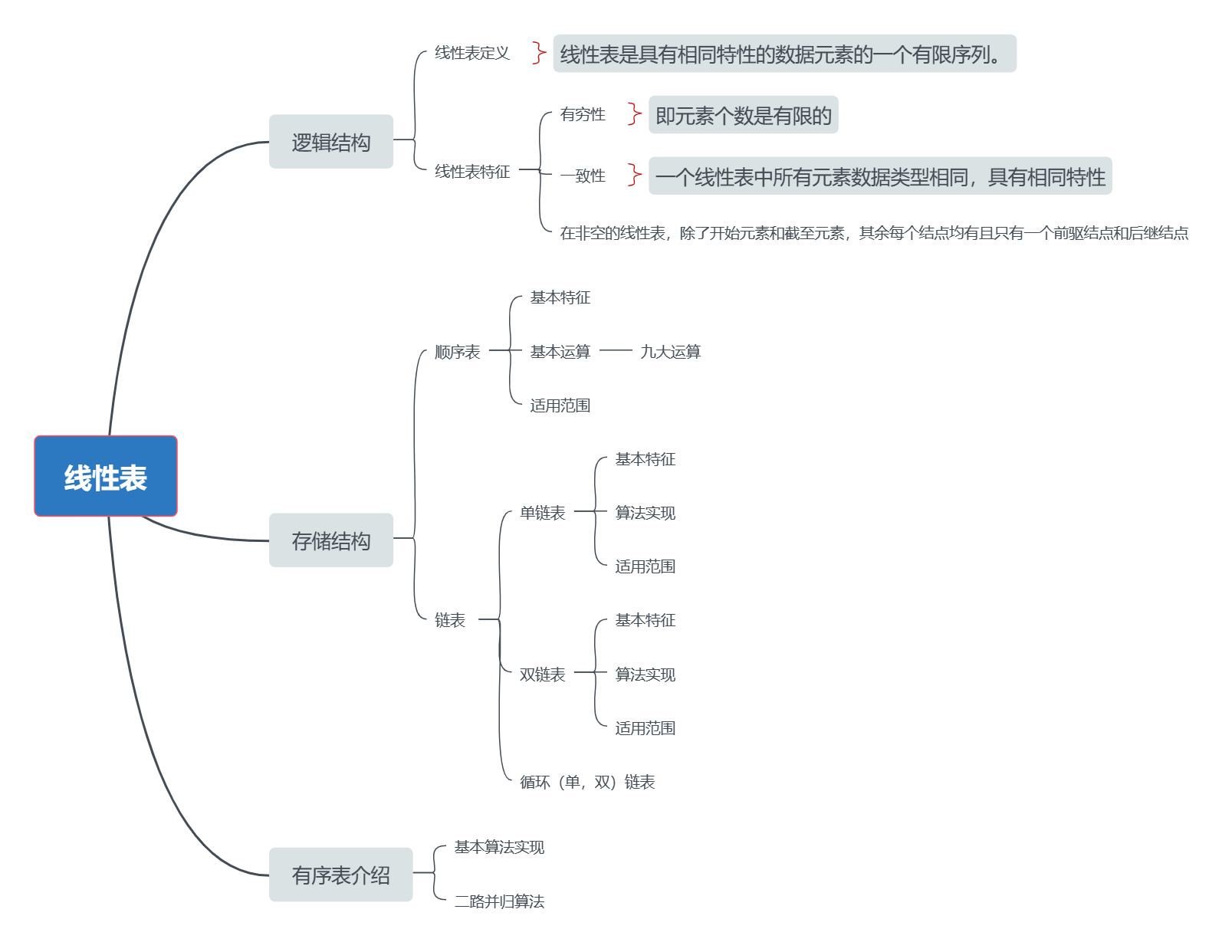
【重点掌握】
顺序结构与逻辑结构的优缺点?
线性表的九大运算(初始化、销毁、判空、判长、输出、插入、删除、查找、建表)
对于链表的理解,学会画图理解代码。需要掌握每一条代码对应图上的每一步。
有序表的二路归并算法的思路及其算法的实现
【性能比较】
线性表虽然简单,但其实其中的理论知识也是非常繁多的,要全部写下来需要很久,所以我个人喜欢在题目中巩固即可。现在就稍微介绍一下顺序表和链表的区别作罢!
顺序表:查找
链表: 插入、删除
一、时间性能比较
取出线性表中的某个元素,使用顺序表更快,时间性能为O(1),因为可以直接下标访问
相比之下,链表的访问只能从表头开始扫描,直到找到特定位置,所需的时间为O(n)。
在链表中进行插入删除操作不需要移动元素,在给出指向链表的某个合适的位置的指针后,插入删除的时间性能为O(1),在顺序表中插入删除所需要的时间性能为O(n)。
所以作为一般规律,我们可以看需求选择。查询少,插入、删除多则选择链表,否则选择顺序表。
二、空间性能比较
所谓的空间性能是指存储结构所占存储空间的大小。我们主要讨论存储密度的比较
链表的存储密度小于顺序表,因为链表除了数据域还有指针域。
对于未知所需空间大小的题目,往往为了不浪费空间,我们会选择使用链表(可以随时增加),当然,你也可以用vector之类的。
好啦,接下来就是练习了,我做完了!
三、习题巩固
一、判断题
( )(1)线性表的链式存储结构优于顺序存储。
( )(2)链表的每个结点都恰好包含一个指针域。
( )(3)在线性表的链式存储结构中,逻辑上相邻的两个元素在物理位置上并不一定紧邻。
( )(4)顺序存储方式的优点是存储密度大,插入、删除效率高。
( )(5)线性链表的删除算法简单,因为当删除链中某个结点后,计算机会自动地将后续的各个单元向前移动。
( )(6)顺序表的每个结点只能是一个简单类型,而链表的每个结点可以是一个复杂类型。
( )(7)线性表链式存储的特点是可以用一组任意的存储单元存储表中的数据元素。
( )(8)线性表采用顺序存储,必须占用一片连续的存储单元。
( )(9)顺序表结构适宜于进行顺序存取,而链表适宜于进行随机存取。
( )(10)插入和删除操作是数据结构中最基本的两种操作,所以这两种操作在数组中也经常使用。
二、填空题
顺序表中逻辑上相邻的元素在物理位置上 相连。
线性表中结点的集合是有限的,结点间的关系是 关系。
顺序表相对于链表的优点是: 和随机存取。
链表相对于顺序表的优点是: 方便。
采用 存储结构的线性表叫顺序表。
顺序表中访问任意一个结点的时间复杂度均为 。
链表相对于顺序表的优点是插入、删除方便;缺点是存储密度 。
在双链表中要删除已知结点*P,其时间复杂度为 。
在单链表中要在已知结点*P之前插入一个新结点,需找到*P的直接前趋结点的地址,其查找的时间复杂度为 。
单链表中需知道 才能遍历整个链表。
性表中第一个结点没有直接前趋,称为 结点。
在一个长度为n的顺序表中删除第i个元素,要移动 个元素。
在一个长度为n的顺序表中,如果要在第i个元素前插入一个元素,要后移 个元素。
在无头结点的单链表中,第一个结点的地址存放在头指针中,而其它结点的存储地址存放在( )结点的指针域中。
当线性表的元素总数基本稳定,且很少进行插入和删除操作,但要求以最快速度存取线性表中的元素时,应采用 存储结构。
在线性表的链式存储中,元素之间的逻辑关系是通过 决定的。
在双向链表中,每个结点都有两个指针域,它们一个指向其 结点,另一个指向其( )结点。
对一个需要经常进行插入和删除操作的线性表,采用 存储结构为宜。
双链表中,设p是指向其中待删除的结点,则需要执行的操作为: 。
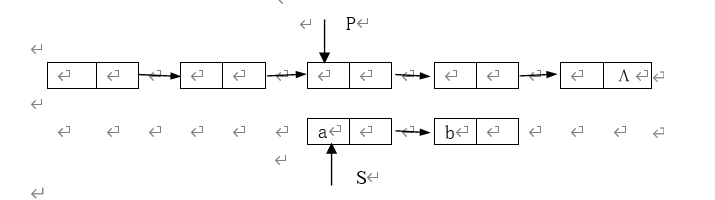
在如图所示的链表中,若在指针P所在的结点之后插入数据域值为a和b的两个结点,则可用下列两个语句: 和P->next=S;来实现该操作。
三、选择题
在具有n个结点的单链表中,实现( )的操作,其算法的时间复杂度都是O(n)。
A.遍历链表或求链表的第i个结点 B.在地址为P的结点之后插入一个结点
C.删除开始结点 D.删除地址为P的结点的后继结点
单链表的存储密度( )。
A. 大于1 B. 等于1 C.小于1 D. 不能确定
已知一个顺序存储的线性表,设每个结点占m个存储单元,若第一个结点的地址为B,则第i个结点的地址为( )。
A. B+(i-1)*m B.B+i*m C. B-i*m D.B+(i+1)*m
在有n个结点的顺序表上做插入、删除结点运算的时间复杂度为( )。
A.O(1) B.O(n) C.O(n2) D.O(log2n)
设Llink、Rlink分别为循环双链表结点的左指针和右指针,则指针P所指的元素是双循环链表L的尾元素的条件是( )。
A.P==L B.P->Llink==L C.P== NULL D.P->Rlink==L
两个指针P和Q,分别指向单链表的两个元素,P所指元素是Q所指元素前驱的条件是( )。
A.P->next==Q->next B.P->next== Q C.Q->next== P D.P== Q
用链表存储的线性表,其优点是( )。
A. 便于随机存取 B. 花费的存储空间比顺序表少
C. 便于插入和删除 D. 数据元素的物理顺序与逻辑顺序相同
在单链表中,增加头结点的目的是( )。
A. 使单链表至少有一个结点 B. 标志表中首结点的位置
C. 方便运算的实现 D. 说明该单链表是线性表的链式存储结构
下面关于线性表的叙述中,错误的是( )关系。
A.顺序表必须占一片地址连续的存储单元 B.顺序表可以随机存取任一元素
C.链表不必占用一片地址连续的存储单元 D.链表可以随机存取任一元素
L是线性表,已知LengthList(L)的值是5,经DelList(L,2)运算后,LengthList(L)的值是 :
A.2 B.3 C.4 D.5
设p为指向单循环链表上某结点的指针,则*p的直接前驱( )。
A.找不到 B.查找时间复杂度为O(1)
C.查找时间复杂度为O(n) D.查找结点的次数约为n
等概率情况下,在有n个结点的顺序表上做插入结点运算,需平均移动结点的数目为( )。
A.n B.(n-1)/2 C. n/2 D.(n+1)/2
在下列链表中不能从当前结点出发访问到其余各结点的是( )。
A.双向链表 B.单循环链表 C.单链表 D.双向循环链表
在顺序表中,只要知道( ),就可以求出任一结点的存储地址。
A.基地址 B.结点大小 C. 向量大小 D.基地址和结点大小
在双链表中做插入运算的时间复杂度为( )。
A.O(1) B.O(n) C.O(n2) D.O(log2n)
链表不具备的特点是( )。
A.随机访问 B.不必事先估计存储空间
C.插入删除时不需移动元素 D.所需空间与线性表成正比
以下关于线性表的论述,不正确的为( )。
A.线性表中的元素可以是数字、字符、记录等不同类型
B.线性顺序表中包含的元素个数不是任意的
C.线性表中的每个结点都有且仅有一个直接前趋和一个直接后继
D.存在这样的线性表,即表中没有任何结点
在( )的运算中,使用顺序表比链表好。
A.插入 B.根据序号查找 C. 删除 D.根据元素查找
四、判断下列代码功能
1.
ListNode *Demo1(LinkList L,ListNode *p)
{ // L是有头结点的单链表
ListNode *q=L->next;
While (q && q->next!=p)
q=q->next;
if (q)
return q;
else
Error(“*p not in L”);
}
2.
void Demo2(ListNode *p,ListNode *q)
{ // p,*q是链表中的两个结点
DataType temp;
temp=p->data;
p->data=q->data;
q->data=temp;
}
五、代码补全题
1.已知线性表中的元素是无序的,并以带表头结点的单链表作存储。试写一算法,删除表中所有大于min,小于max的元素,试完成下列程序填空。
Void delete (lklist head; datatype min, max)
{
q=head->next;
while (p!=NULL)
{
if ((p->data<=min )||(/* */))
{/* */}
else{/* */}
}
}
2. 在带头结点head的单链表的结点a之后插入新元素x,试完成下列程序填空。
structnode
{elemtype data;
node *next;
};
voidlkinsert (node *head, elemtype x)
{node *s,*p;
s= ;
s->data= ;
p=head->next;
while(p!=NULL) && ( p->data!=a )
____ ;
if(p==NULL)
cout<<" 不存在结点a! ";
else{ _____ ______;
___ __________;
}
}
六、程序设计题
1.写一个对单循环链表进行遍历(打印每个结点的值)的算法,已知链表中任意结点的地址为P 。
解:
void Show(ListNode *P)
{
}
2.对给定的带头结点的单链表L,编写一个删除L中值为x的结点的直接前趋结点的算法。
解:
void delete(ListNode *L)
{
}
3.将一个顺序表中从第i个结点开始的k个结点删除。
解
void Del(SeqList *L,int i,int k)
{
}4.已知一个单链表,编写一个函数从单链表中删除自第i个结点起的k个结点。
解:
void Del(node *head,int i,int k)
{
}
5.有—个单链表(不同结点的数据域值可能相同),其头指针为head,编写一个函数计算值域为x的结点个数。
解:本题是遍历单链表的每个结点,每遇到一个结点,结点个数加1,结点个数存储在变量n中。
int counter(head)
node *head;
{
}6.有两个循环单链表,链头指针分别为head1和head2,编写一个函数将链表head1链接到链表head2,链接后的链表仍是循环链表。
解:本题的算法思想是:先找到两链表的尾指针,将第一个链表的尾指针与第二个链表的头结点链接起来,使之成为循环的。
node *link (node*head1, *head2)
{
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









